Некоторые мысли по поводу LLM и искусственного интеллекта в целом. И в конце про нейроморфные процессоры и Intel Loihi.
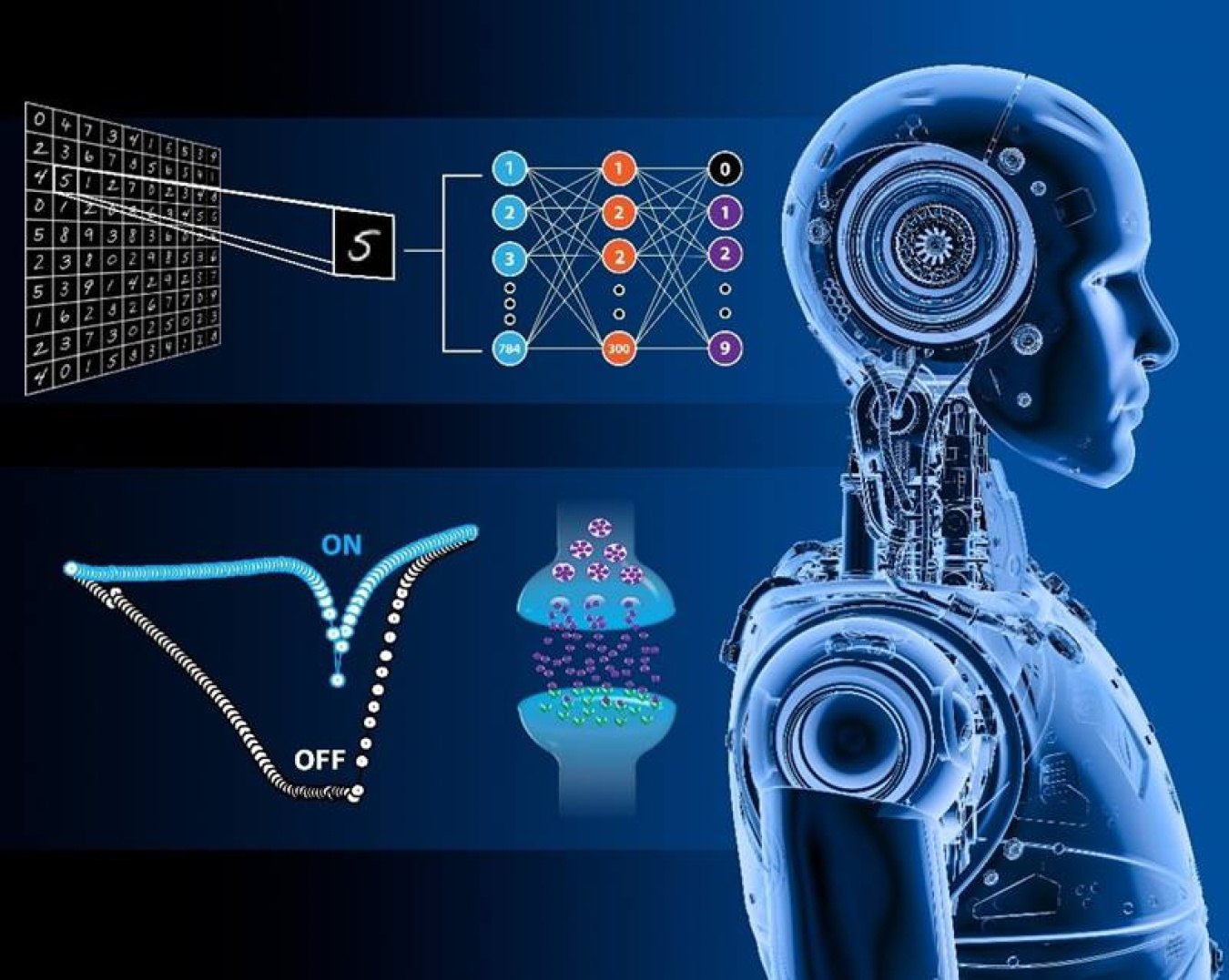
Как вы все знаете, фундаментально LLM работают по принципу «предлагай вероятное следующее слово, используя контекст из предыдущих N слов», и затем слово попадает в контекст, и повторяется все заново для следующего слова. Ну еще и контекст там обрабатывается с учетом важности слов.
А теперь задумаемся, как в первобытных обществах учили языкам детей. Никаких азбук не было, как и грамматики. Но вот сама грамматика, по оценкам, была довольно сложной — по наблюдениям за малыми языками малых народов. Простая грамматика — это современное, когда язык распространился на миллионы и миллиарды.
То есть, мозг ребенка должен реконструировать в своих нейронах грамматику просто на потоке речи от окружающих и через тестирование на понимание сказанного. Возможно, ребенка поправляли, если он говорил неправильно, но как-то эта грамматика и звукоизвлечение должны были улечься в мозг — и вот тут используется тот же механизм, что и в LLM: какие слова/звуки идут рядом в каком контексте определяется латентными и не интерпретируемыми правилами, которые каждый человек в детстве создает в своем мозгу на свой лад. То есть, грубо говоря, тренирует модель ML каждый раз с нуля на потоке речи от окружающих. Ребенок не знает, что такое «падеж», но чувствует, какое окончание статистически более вероятно в данном контексте.
Собственно, современная когнитивистика (теория Карла Фристона) утверждает, что мозг — это буквально «машина предсказания». Мы постоянно генерируем гипотезы о следующем звуке или слове и корректируем их при несовпадении (ошибка предсказания).
Особенность LLM в том, что для нее учителя — это тексты и картинки, а для мозга ребенка — это живой мир вокруг, и если все тексты, которые он слышит, оцифровать, то объема не хватит даже на тренировку очень слабой модели. LLM видит слово «яблоко» рядом со словом «красное». Ребенок видит яблоко, чувствует его запах, вкус, вес и одновременно слышит звук. Эта «сшивка» разных сенсорных каналов позволяет выстраивать нейронные связи в тысячи раз быстрее, чем на чистом тексте. То есть, LLM современные берут брутфорсом — просто наблюдают за речью миллиардов, а не только своего ближайшего окружения. Хороший вопрос как мозг человека умудряется научиться на относительно маленьком датасете. Правда, большой вопрос маленький ли это датасет — например, движения губ, мимика, контекст дают очень много для построения этой нейронной сети в биологическом мозгу.
Про контекст: в отличие от LLM, ребенок понимает намерение говорящего. Если мама смотрит на чашку и говорит «горячо», мозг ребенка ограничивает пространство поиска смыслов одной чашкой. И если он не понял, то обожжется и запомнит.
Можно, конечно, предположить, что мозг уже при рождении имеет готовую сеть. Оно так, но наука пока это не может нормально объяснить. Вся наша генная программа насчитывает порядка 20 000 генов, кодирующих белки, и эти 20000 отвечают вообще за все — где и как должны быть построены легкие, сердце, кости, кровь, и сами по себе что ни возьми, все имеет запредельную сложность, и где-то среди 3 млрд нуклеотидов и 20 тыс генов эта информация должна быть записана.
Судя по всему, гены кодируют не карту, а алгоритм самосборки. Фактически, архитектура нейронной сети строится динамически, и начинается этот процесс задолго до рождения. Далее она калибруется по всем сигналам, которые принимает еще не родившийся ребенок, и к моменту рождения в мозгу уже есть как-то настроенная сеть.
Вероятно, что мозг ребенка — это миллионы нейросетей разных «архитектур», которые эволюционно усложняются, объединяются в процессе обучения. В отличие от LLM, где обучение и использование жестко разделены во времени. Но самое главное — мозг хоть и самый энергозатратный в организме, но в абсолютных значения он крайне мало потребляет энергии, особенно, если сравнивать с текущими «кандидатами на заменители в железе».
Последние годы активно идут разработки в области нейроморфных систем (например, процессоры старенький IBM TrueNorth и активно разивающийся Intel Loihi). В обычном AI нейроны передают числа (0.15, 0.88…). В нейроморфных системах они передают «спайки» (импульсы) — как в живом мозгу (и архитектура называется Spiking Neural Network — SNN). Несколько лет назад Intel выпустила Loihi 2. Полностью программируемая. Нейроны на Loihi могут менять свои связи (синапсы) прямо во время работы. Поддерживает пластичность — тот самый биологический механизм, когда связь между нейронами усиливается, если они часто «срабатывают» вместе. Но главное — потребляет очень мало.
В этой архитектуре модель может дообучаться «на лету» прямо во время работы, не забывая старые данные (Continual Learning). Кроме этого — экстремальная энергоэффективность.
Loihi 2 не умеет перемножать матрицы как это делают современные GPU, поэтому для них нужно вообще с нуля писать софт (и движется это очень медленно). Никакого PyTorch или Tensorflow — для Loihi есть только фреймворк Lava на сегодня. Ну и 1 млн нейронов от Loihi 2 для LLM очень мало. Поэтому Intel создает системы вроде Hala Point — это массив из 1152 процессоров Loihi 2. Он содержит до 1,15 миллиарда нейронов. Теоретически, по своей эффективности при работе с AI-моделями такая система может превосходить классические GPU в 10–50 раз по показателю «производительность на ватт».
На Loihi 2 уже запускают экспериментальные LLM (например, модели на 370 млн параметров). Они пока не заменят ChatGPT в облаке, но теоретически они — будущее для «умных» роботов и гаджетов, которым нужно понимать человеческую речь, работая от маленькой батарейки.
Понаблюдаем. Может оказаться пшиком, а может быть еще одной большой революцией.