Посмотреть салют сегодня
Посмотреть салют сегодня
Полностью редизайнил и рефрешнул свой hybrismart — инжиниринговый блог про екоммерс. Да, как вы уже поняли по этому введению, он на английском. Переработаны все 200+ статей, теперь нет зоопарка стилей, шрифт глаза более приятный, иллюстрации кликабельные, навигация внутри статьи есть. Ещё не все идеально, но достаточно много, чтобы выложить в паблик.
Поиск будет. Он уже работает, но я его временно скрыл. Надо чуть доделать его.
Отдельно гордость — система контекстной рекомендации статей. То есть, рядом с абзацем про drools будет ссылка на статью про drools с объяснением, почему та актуальна в этом контексте. На десктопе это будет заметка на полях, на мобиле — врезка в текст.
Весь сайт статический и генерится из markdown. Прощай вордпресс, ты был очень очень плох.
Опубликовал новую статью на Hybrismart — после долгого перерыва. Она о том, как мигрировать данные из старого сайта в новый с использованием graph db (конкретно я юзал neo4j и memgraph). Кейс такой: есть старый сайт и новый сайт, и нужно перенести CMS данные — компоненты, страницы, сетку из старого в новый, и по ходу сделать всякие трансформации — например, в новом стили другие, сетка другая, компоненты частично другие. Вот для этой задачи я и использовал graph db.
Давно не писал на свой блог про SAP Commerce Cloud. Работал на SAP два года, и считал некорректным писать про их продукты, формально имея доступ к внутренним документам. Сейчас работаю на двух проектах параллельно — один про миграцию SAP Commerce Cloud, а другой в существенной спепени про графовые БД. И на стыке этих миров и родилась статья.
https://hybrismart.com/2026/06/10/migrating-sap-commerce-content-with-a-graph-database/
Я наконец доделал до конца книгу The Reader’s Glossary — это по сути словарь на 5200 слов по «Лолите» Набокова, но организовыванный не в алфавитном порядке, как обычные словари, а в порядке встречаемости сложных слов, с разбивкой по главам и с указанием контекста слова или фразы. Сайт — readersglossary точка com (в первом комменте). Предполагается, что им будут пользоваться в том числе при чтении оригинала как книга-компаньон. Да, она вдвое больше 🙂
Словарь получился довольно толстым — на 600-700 страниц. Он доступен на четырех языках — русском, английском, французском и немецком. Также перевод (RU, FR, DE) или разъяснение (на англ) не абстрактные, а контекстные, да еще и с учетом того, как тот или иной фрагмент переводил сам Набоков с английского («Лолита» писал сначала на английском, потом переводил на русский).
У меня на сайте есть огромные фрагменты этих словарей RU,FR,DE,EN на ознакомление (каждая — около 1/3 полного объема).
Также полноценный интерактивный словарь на сайте, где можно вбить слово и посмотреть перевод или разъяснение. В словаре собраны в основном сложные слова, но мы знаем, что сложность для каждого имеет свое определение, поэтому все слова разбиты на три категории и выделены разными рамочками. Наверное, для начитанного англофона первая категория (пунктиром) вообще бесполезная (это около 50% словаря), для неначитанного, наверное, процентов 20 бесполезны. Но я решил дальше не резать, потому что книга не только для англофонов, но и для тех, кому английский второй язык, и там эти рамочки пунктирные очень даже кстати.
В целом, я это делал «для себя и друзей», just for fun, а не как коммерческий проект. Поэтому я совершенно трезво понимаю, что аудитория у нее супернишевая, и если хотя бы раз в неделю будет появляться кто-то, кому она может быть полезна, уже приятно.
Несмотря на то, что это было что-то типа хобби, времени книжки потребовали много. Для того, чтобы получить то, что получилось, я разработал с десяток приложений/скриптов, из которых пара имеют свой интерактивный UI, в котором я в общей сложности за два месяца работы провел много часов. И конечно, во многом разобрался, собственно, это и есть главный фан от процесса.
Итак, приходите на сайт — readersglossary точка ком. Ссылка в комментариях
P.S. На русском языке — только как PDF пока. Amazon не дает продавать книги на русском, только на небольшом количестве европейских языков в дополнение к английскому. Французская и немецкая версии словаря выйдут на Амазоне через неделю где-то.

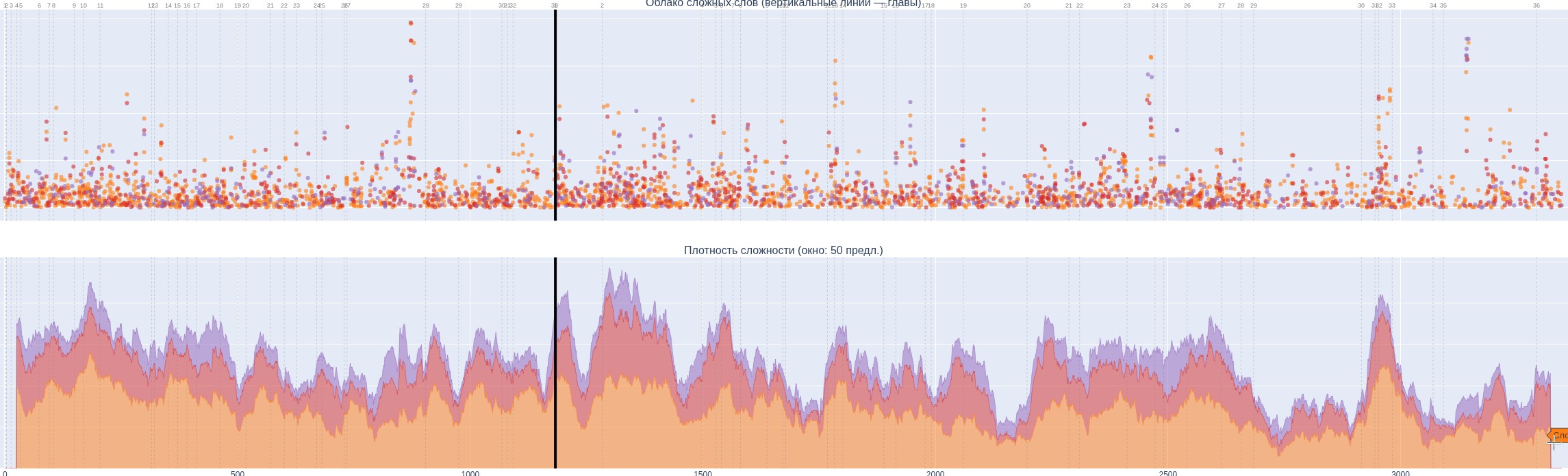
Доделал первую версию книги-словаря по «Лолите» Набокова. На графике показано как распределяется сложность лексики по страницам книги. Нижний график усредняет 25 предложений, по вертикали — число сложных слов, цвета означают сложность/редкость (фиолетовые — самые сложные, красные — менее сложные, желтые — еще менее). Но это я уже убрал еще два уровня, и в целом для иностранца там все пять уровней непростые. В книге пунктиром отмечается уровень 3, простой рамкой — уровень 4, а двойной — уровень 5. Всего сейчас 5794 слова, из которых 541 пятого уровня, 1070 — четвертого, 1883 — третьего, 1393 — второго и 54 — первого (самые простые). Учитывая, что в первой версии получилось 1148 страниц, нужно будет очень сильно подчищать словарь, убирая оттуда то, без чего можно обойтись. Это в существенной степени слова первого и второго уровней, и отдельные из третьего и четвертого. Редкость слов рассчитывается тремя способами : через LLM, и через два списка частот слов англ языка в корпусе текстов (300К слов).
Не все слова сложные. Например, в предложении «With the ebb of lust, an ashen sense of awfulness, abetted by the realistic drabness of a gray neuralgic day, crept over me and hummed within my temples.» наверняка знающему неплохо английский не знакомы слова ebb, abet, drabness, а все остальное знакомо, но чуть снизь требования к читателю, и словарь может быть уже не очень полезным для таких.
Или вот предложение:
Homo pollex of science, with all its many sub-species and forms; the modest soldier, spic and span, quietly waiting, quietly conscious of khaki’s viatric appeal; the schoolboy wishing to go two blocks; the killer wishing to go two thousand miles; the mysterious, nervous, elderly gent, with brand-new suitcase and clipped mustache; a trio of optimistic Mexicans; the college student displaying the grime of vacational outdoor work as proudly as the name of the famous college arching across the front of his sweatshirt; the desperate lady whose battery has just died on her; the clean-cut, glossy-haired, shifty-eyed, white-faced young beasts in loud shirts and coats, vigorously, almost priapically thrusting out tense thumbs to tempt lone women or sadsack salesmen with fancy cravings.
У меня даже браузер подчеркивает тут четыре слова.
У меня есть определения слов на английском, немецком, французском, русском. Я столкнулся с тем, что для разных языков разные слова из текста считаются сложными, а они у меня единые. Так что придется отдельно помечать, например, французские слова в английском тексте, чтобы не включались во французскую версию, так как там читатель знает, например, что такое quel mot.
В общем, на выходных буду убирать, видимо, половину, в ручном режиме, и тогда можно делать обложку и выставлять на Amazon.

Мое творение — инструмент для организации знаний Smartfolio.me — обросло новыми фичами. Прилагаю видос пятиминутный с обзором.
Это как гугл докс, но документы можно вкладывать друг в друга, создавая целую сеть связанных знаний, и такими документами могут быть и PDF, и обычные тексты.
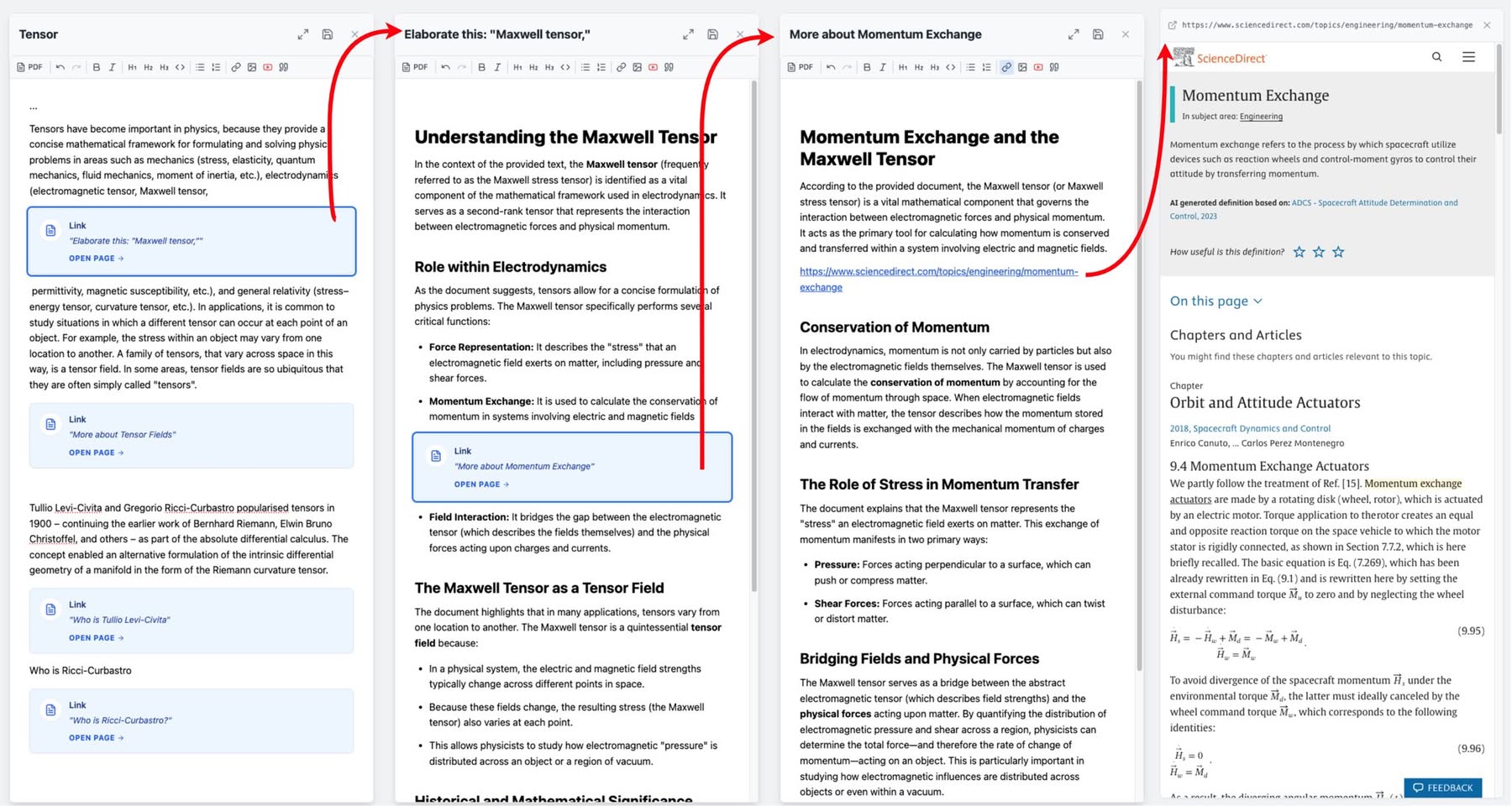
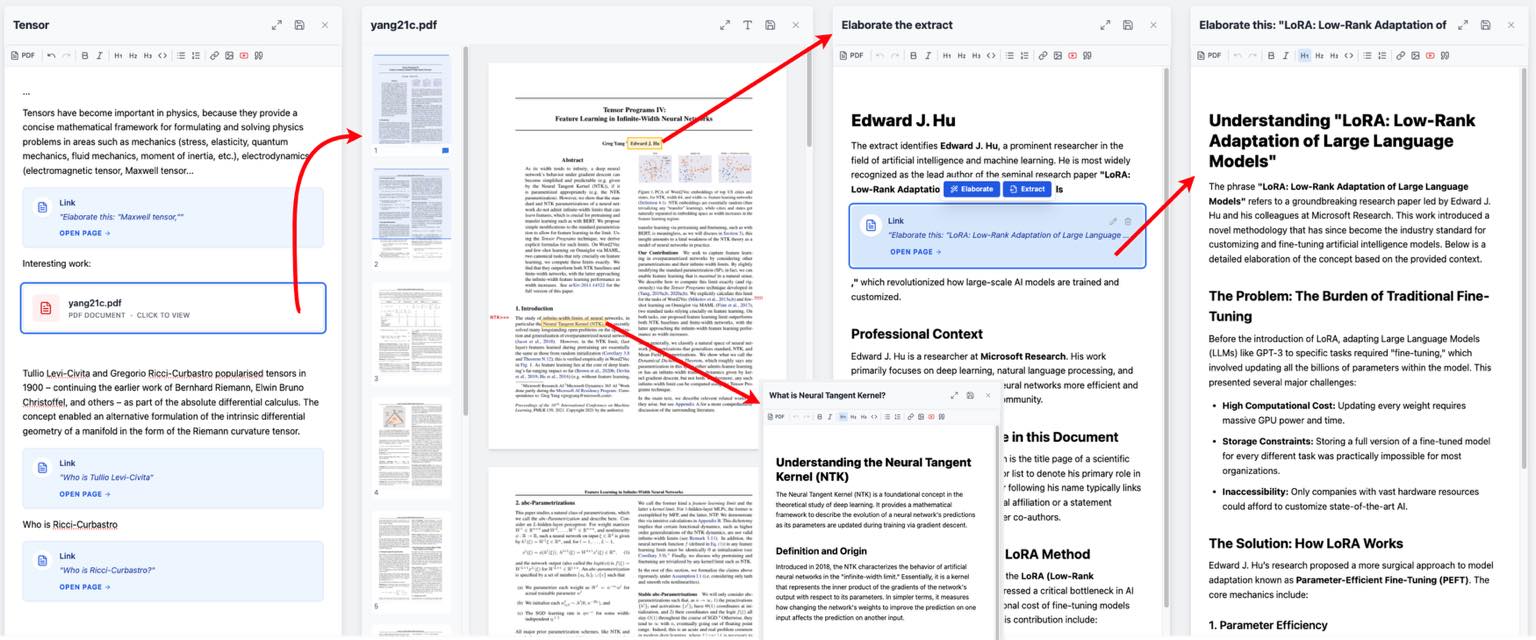
Закидываешь PDF, программа превращает её в картинки, и можно прямо на страницах выделять любые куски, чтобы оставить коммент или задать вопрос.
Если в тексте что-то непонятно, выделяешь область и жмешь «elaborate» — LLM распишет всё подробно, учитывая контекст всего документа, и объяснение останется ссылкой к выделенному фрагменту.
Можно просто вырезать кусок из PDF, а LLM вытащит оттуда чистый текст или готовую формулу.
В окне с PDF теперь есть своя панелька — там сразу видны все комментарии и разъяснения, так что можно быстро прыгать по нужным местам.
Можно вырезать схему или график из PDF, скопировать как картинку и вставить в свой текст. Она сама обрежется «на лету» и сохранится в базу, но не как копия, а как ссылка на страницу с параметрами кропа.
Если удалил ссылку на страницу в тексте, она не пропадет совсем, а попадет в специальный список, откуда её можно привязать в другое место или удалить окончательно. Один и тот же документ можно вставить в несколько мест. Если добавил в него коммент, он обновится везде, где этот документ прилинкован.
Математика поддерживается полностью — формулы на LaTeX можно не только смотреть, но и кликнуть, чтобы подправить их в редакторе.
Можно генерировать формулы по описанию. Просто пишешь словами, что за формула тебе нужна (например, «биномиальное распределение»), и система сама выдает готовый код формулы.
Теперь есть система плагинов — по сути это изолированные от главной программы экспериментальные функции. Например, есть плагин, который рекурсивно собирает все-все дочерние странички в один длинный документ — удобно, если надо всё сразу прочитать или распечатать.
Или вот плагин «Чистка транскриптов YouTube». Если есть грязный текст лекции с YouTube, плагин сам расставит знаки препинания, параграфы и сделает красивые заголовки.
Если вставишь ссылку на сайт, он откроется в колонке рядом — можно читать источник и одновременно делать свои заметки. При этом некоторые сайты не разрешают себя встраивать в чужие страницы. Система такие сайты опознает, и они открываются в новой вкладке.
Левую панель со списком страниц можно скрывать или менять её размер мышкой, чтобы она не отъедала место на экране.
Можно просто скопипастить изображение или скриншот, и он не просто вставится, а еще и зааплоадится в базу данных.
Поддерживается работа с мобильного телефона. На телефоне интерфейс переключается в режим одной колонки, чтобы было удобно читать и комментировать на ходу.
Поддерживаются несколько баз данных — можно переключаться. Можно подключать разные базы данных и разные LLM и переключаться между ними.
Читаю Набокова и решил отвлечься и сделать удобную программку «Словарь Набокова» и подумываю продавать его на Амазоне как книгу. По сути, выглядит это так (см скриншот) — определения сложных слов на английском, русском, немецком и французском, идущих в том же порядке, в каком они идут в оригинальной книге.
Вы бы купили такую книжку?
Для того, чтобы корректно сделать их определения, я также написал aligner — программу, которая сопоставляет предложения и абзацы на английском с их переводами (набоковским) на русский. И когда создается определение слова, используется не только знание LLM, но и перевод на русский автора. Отдельно стоит рассказать, как работает алгоритм (я его сам придумал, потому что все, что нашел в сети, не работало как мне надо). Он находит сначала длинные предложения, и находит для самых длинных предложений их пару через косинусное сходство embedding-векторов, созданных через модель multilingual e5. Эти предложения становятся якорями. Затем, предполагая, что для длинных предложений ошибка почти исключена, находится самое длинное предложение уже между якорями, и все повторяется заново рекурсивно. Там много ситуаций, когда у предложения на русском нет аналога на английском и наоборот, когда предложение разбито на два, или наоборот два слиты в одно. Алгоритм как может это обрабатывает. Результат — очень неплохое качество выравнивания. До такой степени, что ошибки выравнивания уже не получается находить (но наверняка они есть). Так или иначе, оно нужно только для контекста для перевода слов, даже если там и есть редкие ошибки, то не страшно.
Вы бы купили такую книжку?

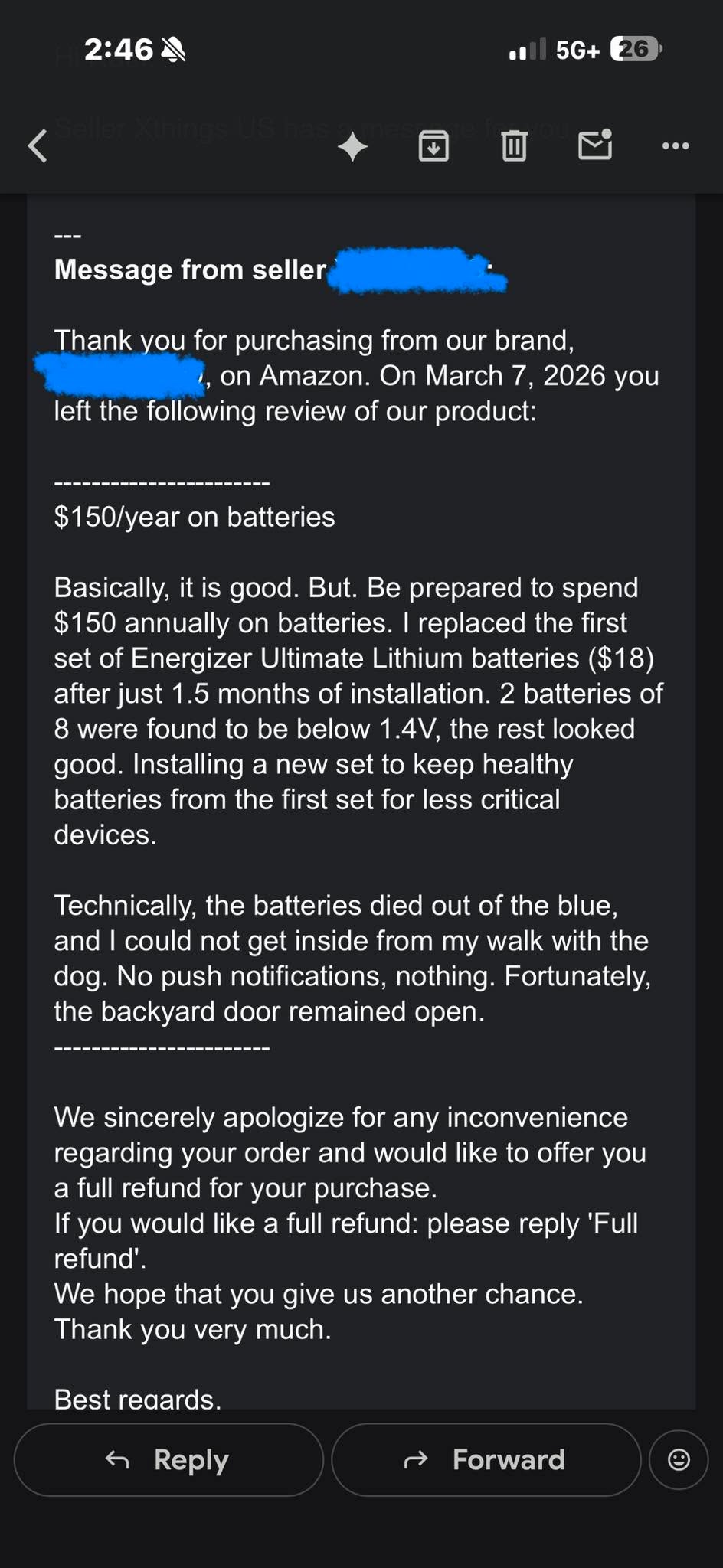
В начале года купил умный замок NFC на входную дверь, за 170 баксов, недавно написал на Амазон отзыв, что батареек хватило на полтора месяца, и если так дальше будет, то почти столько же заплачу за год, и производитель написал, что вернут деньги. Отзыв удалять не просят, да я даже не знаю, можно ли это сделать.
Ищу альфа-тестеров. В рамках R&D и для собственных задач я написал тул для продуктивности (вообще я об этом в прошлом посте писал, но фейсбук сказал, что из-за того, что я ссылку в пост поставил, меня всего 12% увидели). Сейчас хочу проверить, будет ли он полезен кому-то еще. Если идея вам откликнется — дайте знать, и я поделюсь доступом.
Сайт smartfolio точка me. В чем основная идея?
Это онлайн-блокнот для работы с текстом и PDF, организованный в виде графа. Внешне он напоминает Google Docs, но есть важное отличие: вы можете прикреплять «дочерние» документы к конкретным частям основного текста, чтобы раскрыть детали или прояснить концепции. Эти «комментарии» сами по себе являются полноценными документами и могут иметь свои собственные вложенные ветки.
Если в тексте есть непонятный фрагмент, вы можете попросить систему его объяснить (для этого понадобится ваш ключ Google Gemini API).
Система использует полный контекст документа для генерации ответа.
Объяснения навсегда привязываются к конкретному месту в тексте.
Это супер-удобно при чтении сложных научных статей. Например, можно выделить фамилии авторов в PDF и мгновенно получить бэкграунд по ним — информация прикрепится прямо к этому фрагменту на странице.
Типичный воркфлоу
Загружаете сложный текст и читаете его прямо в приложении хоть с мобилы хоть с компа. По ходу дела добавляете ручные или сгенерированные AI заметки к важным или непонятным разделам на будущее.
Я не храню на своих серверах ваши документы, PDF, картинки или API-ключи. Все данные хранятся в Turso DB (SaaS, бесплатно до 5 ГБ).
Лучше всего о проекте расскажут скриншоты — они есть на главной странице сайта.
Как попробовать?
Для регистрации в приложении нужен инвайт-код. Просто напишите мне в комментарии или в личные сообщения, и я его пришлю.
Сайт смартфолио-точка-me
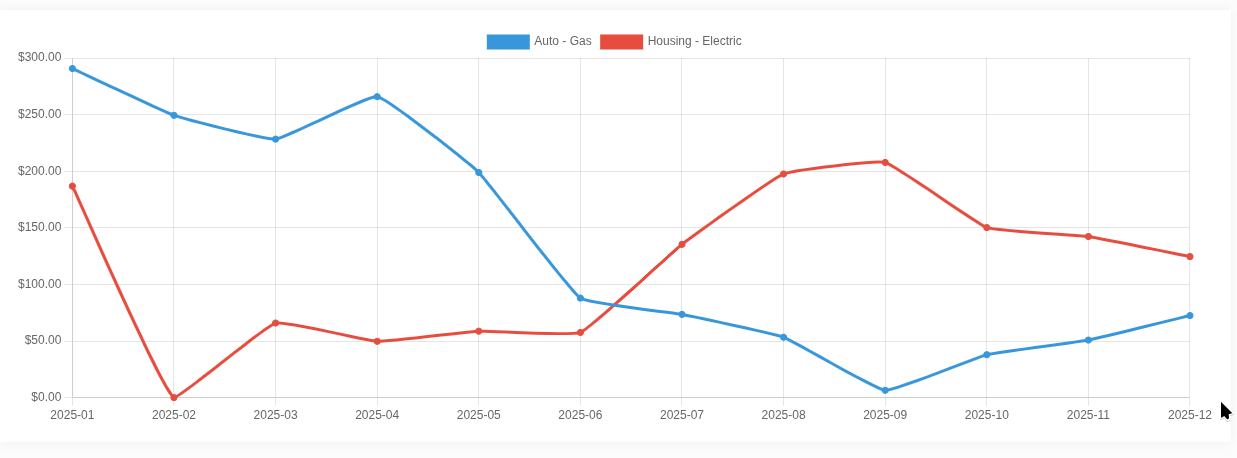
Это мы в середине 2025 купили Теслу — расходы на бензин vs расходы на электроэнергию.
Если выделять только зарядку Теслы, то статистика отдельная. С момента покупки вышло 5000 кВт*ч на $738 долл — пробег 13,550 миль. То есть, проехать 18 миль (28 км) стоит 1 доллар. На Toyota RAV4 за потраченный на заправке доллар проезжаю 10 миль (16 км).