Напоминаю, что у меня есть группа Инженерный дзен в фейсбуке и телеге. За последнее время там вышло про:
— Британский план построить авианосец… изо льда. Длиной 600 метров — крупнейший корабль в истории. Материаловеды нашли добавку, делающую лёд прочным как бетон. Прототип реально построили — его остатки до сих пор лежат на дне канадского озера.
— То, что никто до сих пор толком не знает, почему велосипед не падает. Полтора века в учебниках было два красивых объяснения — пока в 2011-м не построили велосипед, у которого оба эффекта выключены. По всем законам он обязан падать. А он едет.
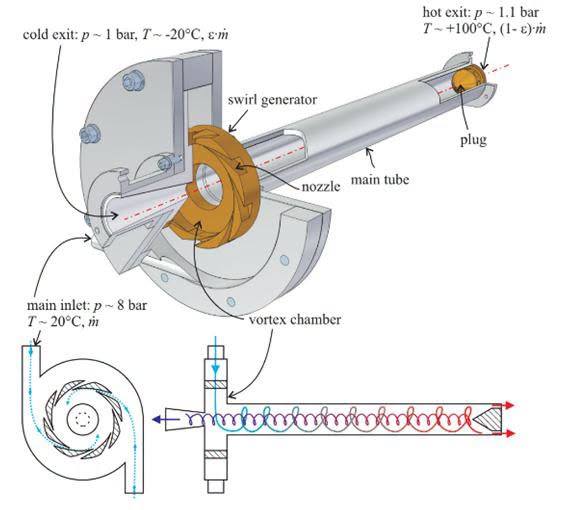
— Как военные разговаривают с подлодками сквозь толщу солёной воды, куда радиоволны не проходят. Американцы едва не превратили в антенну 40% штата Висконсин, а у советской системы антенной работала сама земная кора. КПД — мегаватты на входе, пара ватт на выходе. И этого хватает почти на весь земной шар.
— Ту самую вертушку с лопастями за стеклом, которую сто пятьдесят лет объясняют неправильно. Сам Максвелл сначала обрадовался — а потом заметили, что она крутится не в ту сторону. Правильный ответ гораздо хитрее, и для него нужен именно «неидеальный» вакуум.
— Почему магнитик на холодильник липнет только одной стороной, а другой — почти нет. Оказалось, это тот же фокус, которым фокусируют пучки в ускорителях частиц. И у него очень неочевидная «изнанка».
— «Кремниевую лотерею»: чипы с одного конвейера получаются разными, и ваш процессор, возможно, — это неудачный экземпляр старшей модели с отключёнными блоками. А в 90-х был сопроцессор, который при установке просто выключал основной процессор и работал за него целиком.
— Подводные кабели, по которым живёт весь интернет: толщиной с садовый шланг, под 20 киловольтами, усиливают свет прямо светом — без электричества. И почему трейдеры готовы платить за то, что свет в волокне «слишком медленный».
— Плотину Гувера, внутри которой спрятана почти 1000 км труб — иначе бетон застывал бы 125 лет и её разорвало бы трещинами. Остужали её с помощью завода льда прямо на стройплощадке.
— И на закуску — то, что троллейбус, электромобиль, факс, дрон, видеозвонки и даже робот-гуманоид намного старше, чем вы думаете. Один из роботов ходил, говорил 700 слов, считал на пальцах и курил. В 1939-м. Мы просто пыль сдули, похоже.
Присоединяйтесь, чтобы не пропустить ещё много интересного.
«Инженерный дзен», Инженерный дзен и в телеге t.me / engineersdzen