Доделал в лучшем виде кросс-постинг из фейсбука на два моих сайта-блога [на которые почти никто не заходит] — beinginamerica точка com и raufaliev точка com. При публикации нового поста в фейсбуке по расписанию стартует механизм перевода поста на английский, разбор приложенных картинок, генерация описаний к ним, создание заголовка на основе текста поста и описания картинок, создание тегов на их же основе, запись поста в turso db — это облачная база, бесплатная до определенных лимитов, создание эмбеддингов через openai, запись в qdrant cloud — это тоже облачная база, но уже векторная, ну и загрузка изображений в wordpress по API, и публикация поста на английском и на русском по API.
Все бы хорошо, но из всех API самый дурацкий — у фейсбука. Во-первых, для страниц как у меня, переведенных в New Experience, нет возможности использовать почти все из этого API. Точнее, есть, но нужно долго доказывать фейсбуку, что это реально надо, показывая документы на стартап, демонстрируя приложение и т.д. Очевидно, им не хочется иметь дело с чем-то уносящим контент из их системы во вне. Кроме этого, токен, который дает доступ к последним сообщениям, относительно короткоживущий (возможно, несколько недель), и получать его заново нужно через браузер только. То есть, любая автоматика требует регулярного внимания, иначе она ломается.
Если протупил и вовремя не выгрузил последние посты через этот Facebook Graph API, они просто исчезают из списка последних и все, больше по API к ним не обратиться. Единственный способ — запросить выгрузку архива у фейсбука. Эта выгрузка тоже довольно дурацкая — там нужно много трансформаций делать и убирать лишнее. Например, в файле с постами, который я обрабатываю, там почему-то хранятся ссылки, которые я отправлял в комментариях без сопроводительного текста. А комментарии там идут в отдельном файле!
Чтобы назначить теги, пришлось решить отдельный челендж. Вот есть около 10000 постов за все время. Это большой кусок, и по нему теги построить нельзя, потому что он в контекстное окно LLM не помещается. А надо. Поэтому я делал так: скрипт берет случайные посты из 10000 в таком объеме, чтобы их суммарный размер был чуть меньше указанного лимита в токенах, и в конец этого блока добавляется промпт «сгенери мне наиболее частые теги, 30 штук» (промпт привожу упрощенно). В итоге я запустил это 10 раз и получил 10 наборов тегов по 30 штук, сгенерированных для разных срезов базы. Получилось 300 тегов, из которых конечно есть полные дубликаты, а есть синонимы и близкие по смыслу. Это все скармливается LLM, и получаем список тегов и иерархию тегов. Теперь у нас есть ограниченный набор тегов, которые максимально отражают 10000 постов. Так получилось, что за почти 20 лет на фейсбуке у меня расклад такой:
Тег Постов
==================================================
#Russia 3412
#Thoughts 3146
#Tech 3105
#Culture 2765
#Hobbies 2726
#AI 1603
#Science 1367
#Software 1358
#Travel 1298
#Learning 1138
#Society 1050
#Nature 958
#Education 915
#Business 902
#Art 894
#Programming 889
#Humor 840
#History 807
#Gadgets 750
#Moscow 713
#USA 614
#Cinema 567
#Webdev 493
#Music 476
#Sports 473
#Mindset 443
#Auto 400
#Books 386
…
ну и так далее. Этот список включает как теги из ограниченного списка, так и теги, которые LLM поставила материалу просто потому, что не нашла в ограниченном ничего подходящего.
Теги из ограниченного списка стали категориями на сайте. Остальные теги + эти стали просто тегами wordpress.
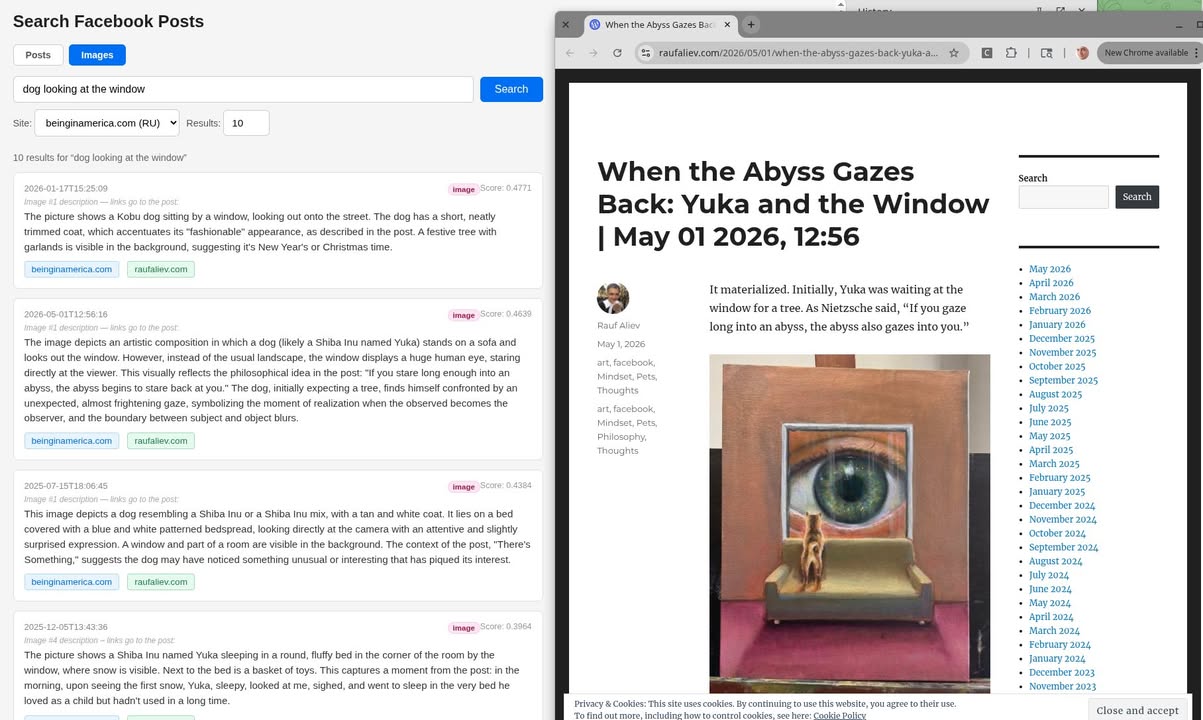
Поиск по картинкам. У меня было две идеи как его сделать. Первая — OpenCLIP. Это довольно просто, но требует хостинга модели где-нибудь. На своей машине легко, но каждый раз ее запускать неудобно, плюс я планировал переносить мигратор на дешевый сервер в амазон. В облачных моделях тоже нормально считать, но хоть немного за это надо платить, а это еще одна dependency. Но главное — что и без этого неплохо работает. Я с помощью OpenAI , который и так используется для перевода на английский, генерю описания к картинкам, и дальше по этим описаниям делаю embeddings с помощью large модели. Пока что все тесты на поиск проходят на ура. Особенно, когда на картинке есть текст, и большой вопрос разобрал бы ли его OpenCLIP.
В итоге:
1) вордпресс raufaliev точка com — бесплатный
2) вордпресс beinginamerica точка com — бесплатный
3) turso db где хранятся все посты — бесплатный
4) qdrant cloud где хранятся эмбеддинги — бесплатный
5) openai для перевода и описания картинок — не бесплатный, но недорогой (обработка постов за год потребовала 30 баксов).
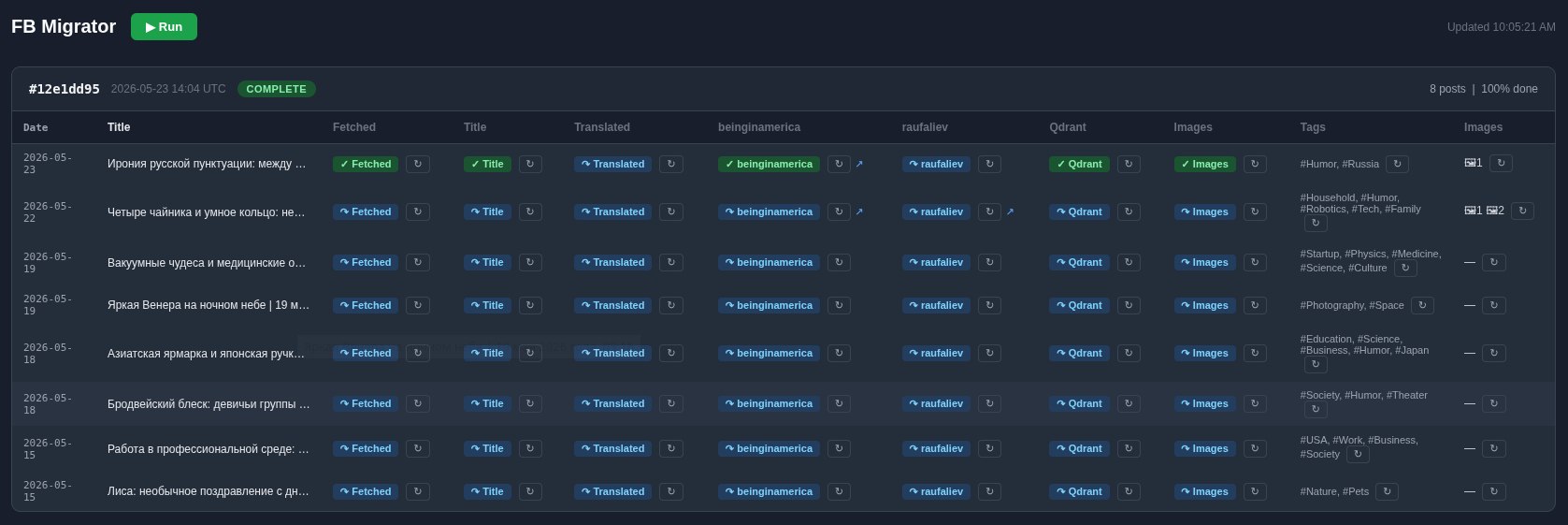
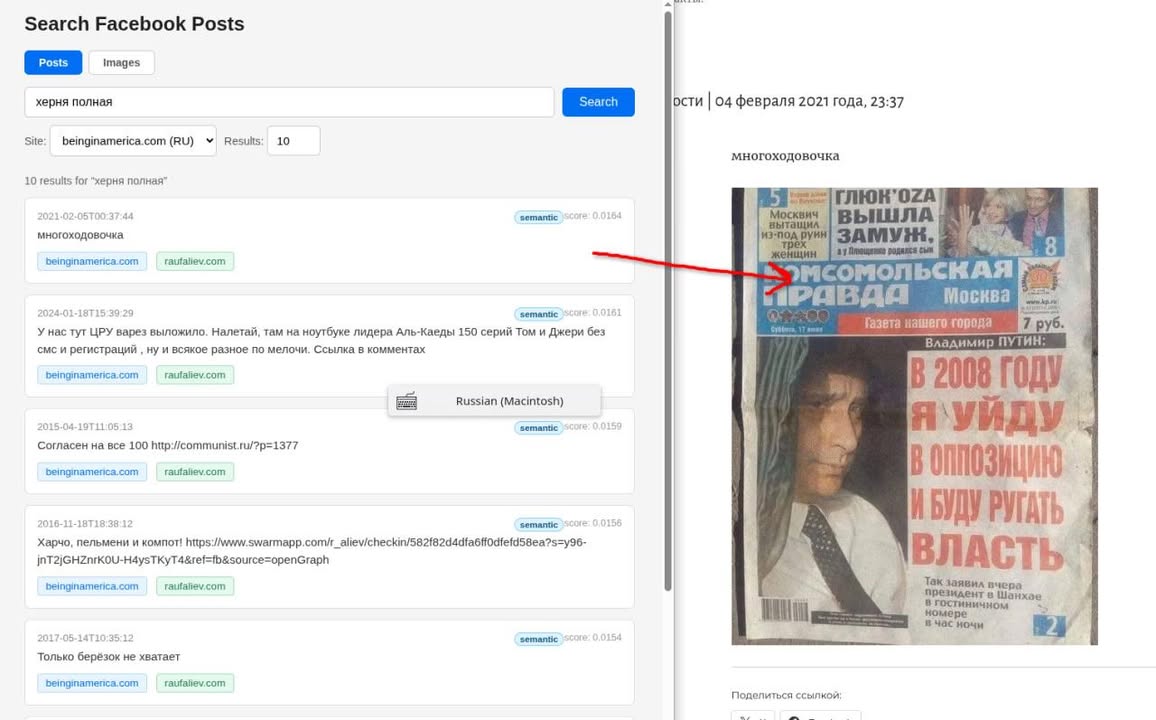
Прикладываю два скриншота — как работает поиск по изображениям, и по текстам, а также дашборд мигратора.