

Метка: Data
Автоматизация документации больших данных: от анализа к действию | 2026-05-06T22:28:27
Интересно, а существует такой агент, который получает на вход таблицу (эксель), по размерам значительно превосходящую контекстное окно, и начинает ее документировать по сути. Вот есть несколько вкладок. Вот есть на вкладке 5 табличка в миллион строк и пять столбцов. Столбцы такие-то. Берем случайные данные из таблички, так, там вроде числа, а там — фамилии. Делаем предположение, что числа там везде — пишем код, который проверяет это предположение и заодно вычисляет мин/макс и набор уникальных значений. Так, значений немного, всего пять. Запишем. Проверяем теперь фамилии. Да, это просто строки, новый сэмплинг показал, что там фамилии правда. Тут формула. Смотрим куда она указывает. И т.д. А вот эта колонка — неясного назначения. Смотрим на данные — это какие-то числа от 0 до 1. Померяем среднее и разброс. Спросим у пользователя — может, даст какие комменты. Дал. Окалось это выданный kpi этого юзера из внешней системы. Запишем. И так далее. Получается документация. Дальше, когда есть документация, можно просить сделать какие-то операции со всем этим, поскольку LLM уже понимает плюс-минус назначение данных, и их связь, и может строить какие-то гипотезы на выявление outliers и их проверять.
Зачем вашему проекту надсмотрщик за качеством данных? | 2026-05-06T16:07:42
Почти в каждом проекте разработки есть выделенная команда автоматизации функционального тестирования, однако на удивление редко встречается аналогичный акцент на Data Quality. Неважно, идут ли данные из внешних интеграций, от пользователей или генерируются самой системой, часто они остаются без должного контроля просто потому, что почему-то никто не считает это важным, а потом борятся с последствиями — они накапливаются как снежный ком. Чем дольше длятся такие проблемы, тем труднее их устранить, что в итоге приводит к ситуации, когда народ просто смиряется с «непоправимым» состоянием базы. Уж насколько лучше выявлять эти проблемы в момент их возникновения, пока технический долг не стал непреодолимым, чем потом решать, как сделать так, чтобы из-за них ничего не падало;
По сути, надо внедрять постоянного «надсмотрщика» над базами данных всех типов, использующихся системой (реляционных, NoSQL, поисковых индексов или графовых БД) — по сути, это слой проверки качества данных поверх процессов. Конечно, должны быть четкие правила — что именно проверять и какими флагами отмечать конкретные аномалии.
Должен быть ответственный за процесс (кожаный мешок, не AI), который будет интегрировать эти отчеты в рабочие процессы разработки и поддержки. Многие проблемы целостности данных невозможно решить просто через интерфейс — они требуют от инженерной команды разработки скриптов для массового исправления и очистки данных.
Тут кстати еще переходит все в область детектирования аномалий (outlier detection). Машинное обучение и LLM для выявления тонких «плохих» паттернов, которые традиционные системы на основе правил могут пропустить.
Что вы об этом думаете? Внедрены ли подобные механизмы в ваши процессы?

Преобразование чата в семантический поиск вопрос-ответ | 2026-04-30T04:05:37
За вечер сделал простую утилитку, которая вытаскивает чат Natural Language Processing за полтора года — там 65 тысяч сообщений, и переводит его в пары вопрос-ответ, по которым есть семантический поиск. При клике на результат поиска (слева) открывается диалог в чате. Подсвечиваются те сообщения, которые являются ответами на вопрос. Ну и сверху подсвечивается вопрос а оригинальной формулировке.
Как работает: система предполагает, что люди в основном делают reply to на сообщения, находящиеся относительно близко в прошлом. Если на одно сообщение делается несколько reply-to, то наверняка оно полезное, и зацепило в чате других. Система берет сообщения, начиная с того, на которое многие отвечали, и заканчивая последним в цепочке reply-to — и среди таких берет те, которые имеют минимум 3 reply-to к оригинальному вопросу. То есть, по сути, она вырезает из чата кусок, начинающийся популярным вопросом так, что после нижнего отреза скорее всего уже идет нерелевантное. Такие блоки могут накладываться друг на друга — например, если кто-то спросил, пока другие отвечали на что-то еще.
То есть, если пользователь А спросил какая погода, и ему ответили «хорошая», «плохая», «дождь», и еще было пять сообщений без reply-to, а потом кто-то ответил на «дождь» вопросом «почему дождь», и на этот вопрос ответили еще пятеро, то в систему попадет первый вопрос про погоду — кусок будет заканчиваться 13 сообщениями.
Дальше эти куски суммаризуются в вопрос-ответ.
Получается прикольно.
П. С. На скриншоте поисковый запрос не имеет отношения к результату поиска, потому что я сдуру сделал скриншот, когда запрос ещё поменял, а отправить ещё не нажал
Противоестественная интуиция высоких размерностей | 2026-04-13T23:17:35
Я сейчас много работаю с векторами большой размерности, и некоторые штуки, которые раньше не осознавал до конца, начинают реально щекотать мозг. Наша 3D-интуиция там не просто не работает — она врет.
Оказывается, любые два случайных вектора в пространстве высокой размерности с огромной вероятностью будут почти перпендикулярны друг другу. Почти всё пространство — это один сплошной «экватор».
Собственно, на этом во многом и построено машинное обучение. Если ваши эмбеддинги внезапно показывают высокую косинусную близость (например, 0.8 — это не статистическая погрешность, а мощнейший сигнал. В 1000-мерном мире «случайно» так сойтись почти невозможно.
В таких пространствах почти вся масса данных сосредоточена в экстремально тонком поверхностном слое. «Внутренности» объектов математически пусты.
Это легко проверить на таком воображаемом примере. Возьмем «кожуру» многомерного шара толщиной всего в 1% от радиуса. Объем шара пропорционален радиусу в степени размерности.
• В трехмерном пространстве мякоть (0.99 радиуса) занимает 97% объема, возводите 0.99 в куб.
• В 1000D мякоть занимает всего 0.000043%.
Можно ещё по другому понять. Чтобы точка оказалась ближе к началу координат, нужно, чтобы по всем осям координаты были близко к началу координат. Стоит одной оси иметь большое значение, и все, точка улетела. Если брать точки случайно, то просто вероятность того, что они все разом будут ниже любого значения падает с ростом размерности, причём падает быстро.
Всё «мясо» данных всегда оказывается в кожуре. Любая выборка в High-D — это, по сути, набор граничных значений.
Для белого шума в высокой размерности расстояние между самым близким и самым дальним соседом становится почти одинаковым. Понятие «близости» просто деградирует.
Smartfolio.me: Революция в организации знаний | 2026-03-19T04:01:04
Мое творение — инструмент для организации знаний Smartfolio.me — обросло новыми фичами. Прилагаю видос пятиминутный с обзором.
Это как гугл докс, но документы можно вкладывать друг в друга, создавая целую сеть связанных знаний, и такими документами могут быть и PDF, и обычные тексты.
Закидываешь PDF, программа превращает её в картинки, и можно прямо на страницах выделять любые куски, чтобы оставить коммент или задать вопрос.
Если в тексте что-то непонятно, выделяешь область и жмешь «elaborate» — LLM распишет всё подробно, учитывая контекст всего документа, и объяснение останется ссылкой к выделенному фрагменту.
Можно просто вырезать кусок из PDF, а LLM вытащит оттуда чистый текст или готовую формулу.
В окне с PDF теперь есть своя панелька — там сразу видны все комментарии и разъяснения, так что можно быстро прыгать по нужным местам.
Можно вырезать схему или график из PDF, скопировать как картинку и вставить в свой текст. Она сама обрежется «на лету» и сохранится в базу, но не как копия, а как ссылка на страницу с параметрами кропа.
Если удалил ссылку на страницу в тексте, она не пропадет совсем, а попадет в специальный список, откуда её можно привязать в другое место или удалить окончательно. Один и тот же документ можно вставить в несколько мест. Если добавил в него коммент, он обновится везде, где этот документ прилинкован.
Математика поддерживается полностью — формулы на LaTeX можно не только смотреть, но и кликнуть, чтобы подправить их в редакторе.
Можно генерировать формулы по описанию. Просто пишешь словами, что за формула тебе нужна (например, «биномиальное распределение»), и система сама выдает готовый код формулы.
Теперь есть система плагинов — по сути это изолированные от главной программы экспериментальные функции. Например, есть плагин, который рекурсивно собирает все-все дочерние странички в один длинный документ — удобно, если надо всё сразу прочитать или распечатать.
Или вот плагин «Чистка транскриптов YouTube». Если есть грязный текст лекции с YouTube, плагин сам расставит знаки препинания, параграфы и сделает красивые заголовки.
Если вставишь ссылку на сайт, он откроется в колонке рядом — можно читать источник и одновременно делать свои заметки. При этом некоторые сайты не разрешают себя встраивать в чужие страницы. Система такие сайты опознает, и они открываются в новой вкладке.
Левую панель со списком страниц можно скрывать или менять её размер мышкой, чтобы она не отъедала место на экране.
Можно просто скопипастить изображение или скриншот, и он не просто вставится, а еще и зааплоадится в базу данных.
Поддерживается работа с мобильного телефона. На телефоне интерфейс переключается в режим одной колонки, чтобы было удобно читать и комментировать на ходу.
Поддерживаются несколько баз данных — можно переключаться. Можно подключать разные базы данных и разные LLM и переключаться между ними.
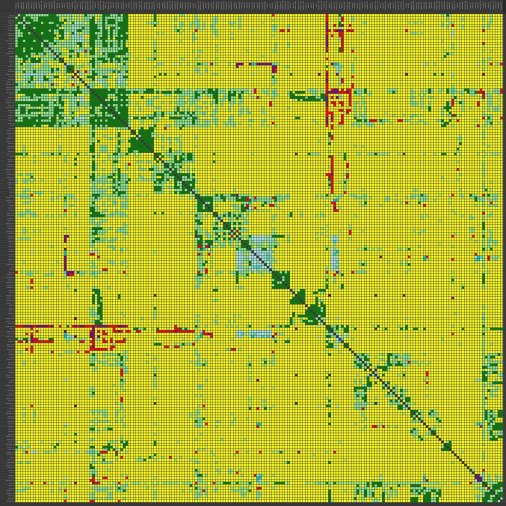
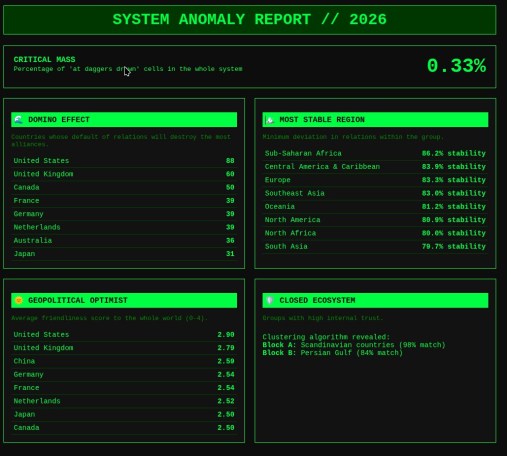
Геополитический расклад: анализ отношений между странами | 2026-03-12T03:29:28
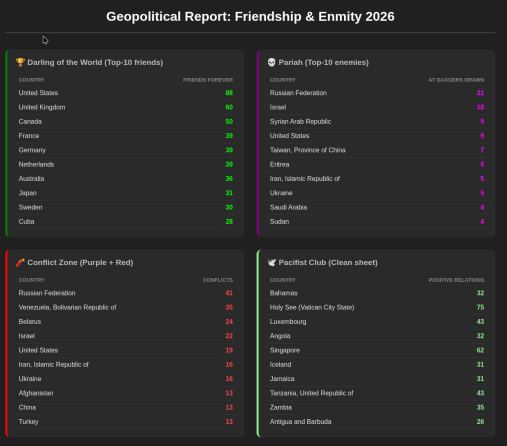
Ради развлечения решил сделать матрицу кто с кем друг и кто с кем враг. Для каждой пары страна-страна я спрашивал у Gemini, в какую из пяти категорий попадают отношения: «на ножах» (фиолетовые), «преимущественно недобрые» (красным), «никакие» (желтым), преимущественно добрые» (голубым), «друзья» (зеленым). Лиза сказала, что «никакие» должны быть фиолетовыми. В целом, качество оценок Gemini неплохое.
Из всех стран выделяются три красные линии. Это страны, у которых не очень с очень много кем. Ну Россию вы правильно угадали. А что за вторая страна? Израиль? Нет, это Беларусь и Венесуэла.
В пятерку стран, с которыми все дружат и которые много с кем дружат, LLM включил США, Великобританию, Канаду, Францию и Германию. Есть антирейтинг — это страны, у которых много с кем очень не ладится («на ножах»). В этом рейтинге на первом месте Россия с 21 страной, и на втором месте Израиль с 18 недругами. Дальше с большим отрывом идут Сирия и США с 9 недругами. Есть отдельный рейтинг Conflict zone — это по сумме красных с фиолетовыми. Россия, Венесуэла, Беларусь, Израиль, США, Иран, Украина.
Есть «клуб пацифистов». Эти те, у которых вообще нет врагов с сортировкой по числу друзей. Рейтинг: Багамы, Ватикан, Люксембург, Ангола, Сингапур, Исландия, Ямайка, Танзания, Замбия.
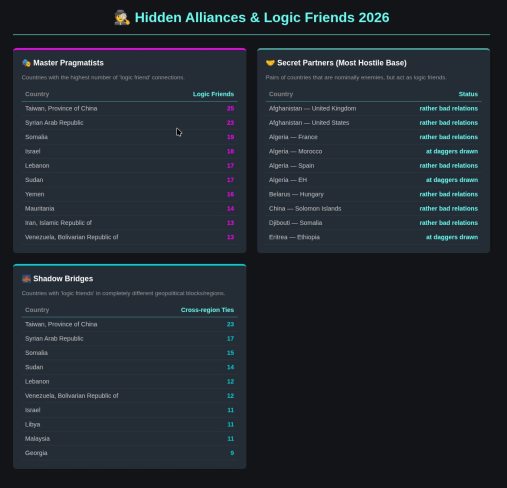
Мне было интересно, а что если применить формулу: враг моего врага — мой друг? Что поменяется? Это привело к новым краскам на матрице — logic friends.
Самым неожиданным лидером рейтинга Master Pragmatists стал Тайвань (25 логических связей). Почему так? В логике LLM, Тайвань — это страна, которая официально признана немногими, но из-за глобального противостояния с Китаем она автоматически становится «логическим другом» для всех, у кого с Пекином натянутые отношения. Это подтверждается и в разделе Shadow Bridges: у Тайваня 23 связи за пределами своего региона. Он буквально «сшивает» разные части света через общую проблему.
Отчет «Тайные партнеры» — список геополитических оксюморонов. Это пары, которые в официальных новостях «на ножах», но по расчету Gemini вынуждены дружить. Например, Афганистан — США/Великобритания. Несмотря на статус «rather bad relations», логика Gemini видит в них «логических друзей». Вероятно, из-за общих региональных угроз (например, ИГИЛ) или зависимости от гуманитарных и теневых каналов. Или вот странный союз «Беларусь — Венгрия». Номинально — разные лагеря, фактически — схожий стиль риторики и общие «недруги» в Брюсселе. Эритрея — Эфиопия: Статус «на ножах», но при этом они попали в логические друзья.
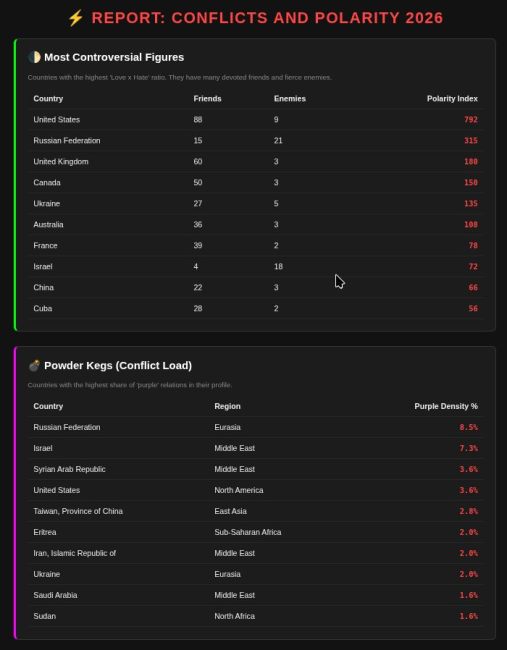
В отчете «наиболее противоречивые» первые места занимают США, и потом с большим отрывом Россия, и еще с большим — Великобритания, Канада, Украина. Это страны с наибольшим значением произведения Love x Hate. То есть, у которых одновременно много и друзей, и врагов.
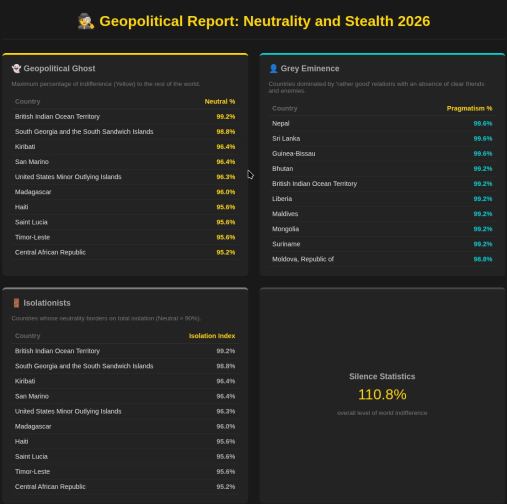
Еще один отчет — пофигисты. Про них LLM не смогла много что сказать, видимо, потому, что они никого не волнуют (как в прямом, так и в переносном смысле). Там например Магадаскар и Гаити.
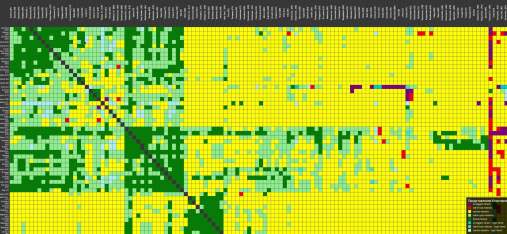
Еще я попробовал кластеризовать по силе друзей и получил четыре группы стран.
Самый масштабный кластер. Ядро: Китай, Россия, Иран, Индия и страны БРИКС+, а также почти весь африканский континент (от Египта до ЮАР) и значительная часть Ближнего Востока (ОАЭ, Саудовская Аравия, Катар).
Во второй кластер попали главным образом европейские страны. Ядро: Франция, Германия, Великобритания. Сюда алгоритм определил Украину и Израиль. Это логично: их выживание зависит от «преимущественно добрых отношений» с европейским ядром. В этом же клубе находятся Армения, Грузия и Сербия. Видимо, несмотря на все политические качели, их связи с Европой Gemini считает более фундаментальными, чем любые другие.
В третий кластер попали США, Канада, Бразилия, Мексика, а также, например, Тайвань. Официально он может быть «логическим другом» для всех врагов Китая, но по «силе друзей» он намертво пришит к американскому блоку. Сюда же попал Ватикан, что делает этот клуб не только экономическим, но и в некотором роде «ценностным».
В четвертый, самый компактный и специализированный клуб, попали страны Океании и Юго-Восточной Азии. Лидеры: Австралия, Япония, Новая Зеландия, Сингапур. Это получился клуб стран, которые пытаются балансировать в самом сложном регионе планеты. Здесь же находятся почти все островные государства (Фиджи, Самоа, Тонга).
Что еще можно попробовать вытащить из этой информации?
Альтруизм гигантов: миф или реальность? | 2026-03-04T19:00:11
Я не верю в альтруизм гигантов. Когда речь заходит о больших государствах или корпорациях-миллиардерах, верить в то, что они руководствуются «принципами добра» и «всеобщим благом» на мой взгляд, это либо наивность, либо опасный самообман.
Реальная цель всегда остается в тени. Почему? Потому что, если все поймут истинные намерения, достигать их станет в разы сложнее и дороже. Точнее, их и так все понимают, просто круг этих понимающих небольшой.
Возьмем «освободительные войны». Когда диктатуре несут демократию на штыках — это не про права человека. Это способ внедриться в чужую систему и показать, кто здесь «альфа-самец». В этом государстве всегда есть конкретные интересы. Проще говоря, это создание геополитической «крыши». В определенных культурах тебя уважают только за силу. Если ты не показал доминантность — тебя не слушают. А если показал — тебя пускают в «совет старейшин» и просят «порешать вопросики».
Если корпорация вдруг начинает неистово заботиться о планете — ищите второе дно. Скорее всего, старое производство стало слишком дорогим в обслуживании, и его пора менять. Но под соусом «уменьшения выбросов» модернизация заходит на ура. Бонусом идут налоговые льготы, гранты и возможность заработать на господрядах. Экология — это просто красивый фасад для оптимизации расходов.
Часто инициатива идет не изнутри системы, а снаружи. Пример: В районе строят роскошный парк со скамейками и уточками. Забота о людях? Относительно. Главные интересанты — девелоперы. Квартиры в домах у парка стоят на 20-30% дороже и продаются в два раза быстрее. Бизнес или политик просто поддерживает идею, которая приносит прибыль (финансовую или электоральную) конкретным группам.
Даже святая святых — наука — держится не только на любопытстве и желании создать лучшее будущее для людей. Огромная часть открытий движима банальным тщеславием. Ученому важно оставить имя в веках, подняться на ступеньку выше в иерархии или хотя бы чувствовать себя «рок-звездой» на профильной конференции. Личные амбиции двигают прогресс эффективнее, чем абстрактное желание помочь человечеству.
Когда технологические гиганты запускают бесплатный спутниковый интернет или раздают дешевые смартфоны в развивающихся странах (Африка, Индия), это подается как «миссия по соединению мира». Реальный интерес — рынки золотого миллиарда перенасыщены. Единственный способ расти — создавать новых потребителей. Давая человеку «бесплатный» доступ, корпорация подсаживает его на свою экосистему, получает доступ к биометрии и поведенческим данным миллионов людей, которые еще не защищены законами о конфиденциальности. Это колонизация цифрового пространства 21 века.
Крупнейшие филантропические организации часто тратят миллиарды на борьбу с болезнями или голодом. Реальный интерес — Налоговая оптимизация и «мягкая сила». Перевод активов в фонд позволяет избежать налога на наследство или прирост капитала. При этом основатель сохраняет контроль над средствами через совет директоров. Бонусом идет статус «неприкасаемого» в медиа: критиковать человека, который «спасает детей», — значит совершить репутационное самоубийство. Это лучшая страховка от антимонопольных расследований.
Массовое внедрение «повестки» в Голливуде часто воспринимается как торжество либеральных ценностей. Реальный интерес — минимизация рисков и расширение аудитории. Киностудии — это огромные бюрократические машины. Для них «разнообразие» — это чек-лист, который страхует от бойкотов и скандалов (которые стоят денег). Кроме того, добавляя персонажа определенной этнической группы, студия автоматически открывает для себя локальный рынок этой группы по всему миру. Это чистая математика охватов.
Миром правит не доброта, а интересы и иерархия. И, пожалуй, это даже хорошо — по крайней мере, это предсказуемо и логично. Это все было про альтруизм гигантов. А вот в альтруизм отдельных людей я очень даже верю.

Инновационный веб-блокнот с AI и PDF: переосмысление работы с информацией | 2026-02-19T16:19:37
Еще доработал новый тул для себя для работы с информацией и её организации. Основная идея — это веб-блокнот для исследований, изучения темы, работой над ней, интегрированный с AI и поддержкой PDF.
Главная проблема обычных PDF-ридеров и заметок заключается в том, что контекст теряется, как только вы переключаетесь на новую вкладку. В моем инструменте каждый фрагмент текста или PDF становится узлом в «живом» гипертекстовом дереве, к которому я могу доступиться с нескольких компов в любое время.
Процесс работы:
— Контекстный AI. Я могу просить AI разъяснить сложные пассажи прямо внутри документа. Объяснение остается именно там, где был задан вопрос. При этом оно является отдельным документом, привязанным к конкретному месту в источнике. При клике вы видите на экране одновременно и оригинал, и пояснение.
— Панели вместо окон. Если само объяснение требует уточнений, справа открывается новая панель. Это позволяет выстраивать бесконечную цепочку запросов, ни разу не теряя места в исходном тексте. То есть, вы видите сразу несколько панелей, ненужные можно закрыть.
— Поддержка PDF. Я могу загрузить PDF, выделить область на странице (например, сложную диаграмму или список авторов), и LLM мгновенно извлечет данные, дополнит или объяснит их. Объяснение прицепится к месту, где его просили, как и в случае не-PDF.
— Вложенные аннотации. Мои комментарии — это не просто статичный текст. Они могут содержать собственные PDF, ссылки и дальнейшие подзадачи для AI, поддерживая глубину вложенности, которая отражает то, как мы мыслим на самом деле.
Это не просто система хранения файлов, а «движок» для построения знаний.
Инструмент отлично подходит мне лично, но, возможно, он решает только мои специфические задачи. Как вы думаете, будет ли нечто подобное полезно другим? Было бы это полезно вам? Стоит ли развивать проект до полноценного продукта и давать его на тест другим пользователям?
Интерактивные врезки для понимания текста: новый инструмент объяснений | 2026-02-12T16:11:10
Запилил буквально за час такую штуку. Как думаете, она кому-то кроме меня нужна?
Идея такая. Берем любой текст — статья, например, википедии. Выделяем любой фрагмент, например, что непонятно. LLM нам дает объяснение, и тут же в текст втыкает врезку. На которую можно кликнуть, и откроется объяснение. В этом объяснении может быть тоже что-то непонятно. Выделяем мышью уже из этого, и там тоже появляется врезка. И так, пока не разберемся. Все врезки остаются в тексте, так что всегда можно к ним вернуться. Как бы идея, раз мне тут было непонятно, может и другим не будет, и тогда им очень кстати будет готовая ссылка с разъяснениями. Результат можно зашарить с коллегами.
Для разъяснения конечно используется не только фрагмент, но и контекст. Например, иначе бы выделенное слово Terrier выдавало бы текст про собак, а не про про поисковую систему.
