
Интересно, а существует такой агент, который получает на вход таблицу (эксель), по размерам значительно превосходящую контекстное окно, и начинает ее документировать по сути. Вот есть несколько вкладок. Вот есть на вкладке 5 табличка в миллион строк и пять столбцов. Столбцы такие-то. Берем случайные данные из таблички, так, там вроде числа, а там — фамилии. Делаем предположение, что числа там везде — пишем код, который проверяет это предположение и заодно вычисляет мин/макс и набор уникальных значений. Так, значений немного, всего пять. Запишем. Проверяем теперь фамилии. Да, это просто строки, новый сэмплинг показал, что там фамилии правда. Тут формула. Смотрим куда она указывает. И т.д. А вот эта колонка — неясного назначения. Смотрим на данные — это какие-то числа от 0 до 1. Померяем среднее и разброс. Спросим у пользователя — может, даст какие комменты. Дал. Окалось это выданный kpi этого юзера из внешней системы. Запишем. И так далее. Получается документация. Дальше, когда есть документация, можно просить сделать какие-то операции со всем этим, поскольку LLM уже понимает плюс-минус назначение данных, и их связь, и может строить какие-то гипотезы на выявление outliers и их проверять.
Метка: MachineLearning
Зачем вашему проекту надсмотрщик за качеством данных? | 2026-05-06T16:07:42
Почти в каждом проекте разработки есть выделенная команда автоматизации функционального тестирования, однако на удивление редко встречается аналогичный акцент на Data Quality. Неважно, идут ли данные из внешних интеграций, от пользователей или генерируются самой системой, часто они остаются без должного контроля просто потому, что почему-то никто не считает это важным, а потом борятся с последствиями — они накапливаются как снежный ком. Чем дольше длятся такие проблемы, тем труднее их устранить, что в итоге приводит к ситуации, когда народ просто смиряется с «непоправимым» состоянием базы. Уж насколько лучше выявлять эти проблемы в момент их возникновения, пока технический долг не стал непреодолимым, чем потом решать, как сделать так, чтобы из-за них ничего не падало;
По сути, надо внедрять постоянного «надсмотрщика» над базами данных всех типов, использующихся системой (реляционных, NoSQL, поисковых индексов или графовых БД) — по сути, это слой проверки качества данных поверх процессов. Конечно, должны быть четкие правила — что именно проверять и какими флагами отмечать конкретные аномалии.
Должен быть ответственный за процесс (кожаный мешок, не AI), который будет интегрировать эти отчеты в рабочие процессы разработки и поддержки. Многие проблемы целостности данных невозможно решить просто через интерфейс — они требуют от инженерной команды разработки скриптов для массового исправления и очистки данных.
Тут кстати еще переходит все в область детектирования аномалий (outlier detection). Машинное обучение и LLM для выявления тонких «плохих» паттернов, которые традиционные системы на основе правил могут пропустить.
Что вы об этом думаете? Внедрены ли подобные механизмы в ваши процессы?

Преобразование чата в семантический поиск вопрос-ответ | 2026-04-30T04:05:37
За вечер сделал простую утилитку, которая вытаскивает чат Natural Language Processing за полтора года — там 65 тысяч сообщений, и переводит его в пары вопрос-ответ, по которым есть семантический поиск. При клике на результат поиска (слева) открывается диалог в чате. Подсвечиваются те сообщения, которые являются ответами на вопрос. Ну и сверху подсвечивается вопрос а оригинальной формулировке.
Как работает: система предполагает, что люди в основном делают reply to на сообщения, находящиеся относительно близко в прошлом. Если на одно сообщение делается несколько reply-to, то наверняка оно полезное, и зацепило в чате других. Система берет сообщения, начиная с того, на которое многие отвечали, и заканчивая последним в цепочке reply-to — и среди таких берет те, которые имеют минимум 3 reply-to к оригинальному вопросу. То есть, по сути, она вырезает из чата кусок, начинающийся популярным вопросом так, что после нижнего отреза скорее всего уже идет нерелевантное. Такие блоки могут накладываться друг на друга — например, если кто-то спросил, пока другие отвечали на что-то еще.
То есть, если пользователь А спросил какая погода, и ему ответили «хорошая», «плохая», «дождь», и еще было пять сообщений без reply-to, а потом кто-то ответил на «дождь» вопросом «почему дождь», и на этот вопрос ответили еще пятеро, то в систему попадет первый вопрос про погоду — кусок будет заканчиваться 13 сообщениями.
Дальше эти куски суммаризуются в вопрос-ответ.
Получается прикольно.
П. С. На скриншоте поисковый запрос не имеет отношения к результату поиска, потому что я сдуру сделал скриншот, когда запрос ещё поменял, а отправить ещё не нажал
Противоестественная интуиция высоких размерностей | 2026-04-13T23:17:35
Я сейчас много работаю с векторами большой размерности, и некоторые штуки, которые раньше не осознавал до конца, начинают реально щекотать мозг. Наша 3D-интуиция там не просто не работает — она врет.
Оказывается, любые два случайных вектора в пространстве высокой размерности с огромной вероятностью будут почти перпендикулярны друг другу. Почти всё пространство — это один сплошной «экватор».
Собственно, на этом во многом и построено машинное обучение. Если ваши эмбеддинги внезапно показывают высокую косинусную близость (например, 0.8 — это не статистическая погрешность, а мощнейший сигнал. В 1000-мерном мире «случайно» так сойтись почти невозможно.
В таких пространствах почти вся масса данных сосредоточена в экстремально тонком поверхностном слое. «Внутренности» объектов математически пусты.
Это легко проверить на таком воображаемом примере. Возьмем «кожуру» многомерного шара толщиной всего в 1% от радиуса. Объем шара пропорционален радиусу в степени размерности.
• В трехмерном пространстве мякоть (0.99 радиуса) занимает 97% объема, возводите 0.99 в куб.
• В 1000D мякоть занимает всего 0.000043%.
Можно ещё по другому понять. Чтобы точка оказалась ближе к началу координат, нужно, чтобы по всем осям координаты были близко к началу координат. Стоит одной оси иметь большое значение, и все, точка улетела. Если брать точки случайно, то просто вероятность того, что они все разом будут ниже любого значения падает с ростом размерности, причём падает быстро.
Всё «мясо» данных всегда оказывается в кожуре. Любая выборка в High-D — это, по сути, набор граничных значений.
Для белого шума в высокой размерности расстояние между самым близким и самым дальним соседом становится почти одинаковым. Понятие «близости» просто деградирует.
Глоссарий к «Лолите» Набокова: не просто словарь, а книга-путеводитель | 2026-04-08T11:24:22
Я наконец доделал до конца книгу The Reader’s Glossary — это по сути словарь на 5200 слов по «Лолите» Набокова, но организовыванный не в алфавитном порядке, как обычные словари, а в порядке встречаемости сложных слов, с разбивкой по главам и с указанием контекста слова или фразы. Сайт — readersglossary точка com (в первом комменте). Предполагается, что им будут пользоваться в том числе при чтении оригинала как книга-компаньон. Да, она вдвое больше 🙂
Словарь получился довольно толстым — на 600-700 страниц. Он доступен на четырех языках — русском, английском, французском и немецком. Также перевод (RU, FR, DE) или разъяснение (на англ) не абстрактные, а контекстные, да еще и с учетом того, как тот или иной фрагмент переводил сам Набоков с английского («Лолита» писал сначала на английском, потом переводил на русский).
У меня на сайте есть огромные фрагменты этих словарей RU,FR,DE,EN на ознакомление (каждая — около 1/3 полного объема).
Также полноценный интерактивный словарь на сайте, где можно вбить слово и посмотреть перевод или разъяснение. В словаре собраны в основном сложные слова, но мы знаем, что сложность для каждого имеет свое определение, поэтому все слова разбиты на три категории и выделены разными рамочками. Наверное, для начитанного англофона первая категория (пунктиром) вообще бесполезная (это около 50% словаря), для неначитанного, наверное, процентов 20 бесполезны. Но я решил дальше не резать, потому что книга не только для англофонов, но и для тех, кому английский второй язык, и там эти рамочки пунктирные очень даже кстати.
В целом, я это делал «для себя и друзей», just for fun, а не как коммерческий проект. Поэтому я совершенно трезво понимаю, что аудитория у нее супернишевая, и если хотя бы раз в неделю будет появляться кто-то, кому она может быть полезна, уже приятно.
Несмотря на то, что это было что-то типа хобби, времени книжки потребовали много. Для того, чтобы получить то, что получилось, я разработал с десяток приложений/скриптов, из которых пара имеют свой интерактивный UI, в котором я в общей сложности за два месяца работы провел много часов. И конечно, во многом разобрался, собственно, это и есть главный фан от процесса.
Итак, приходите на сайт — readersglossary точка ком. Ссылка в комментариях
P.S. На русском языке — только как PDF пока. Amazon не дает продавать книги на русском, только на небольшом количестве европейских языков в дополнение к английскому. Французская и немецкая версии словаря выйдут на Амазоне через неделю где-то.

Лексическая карта «Лолиты» Набокова | 2026-04-02T15:56:00
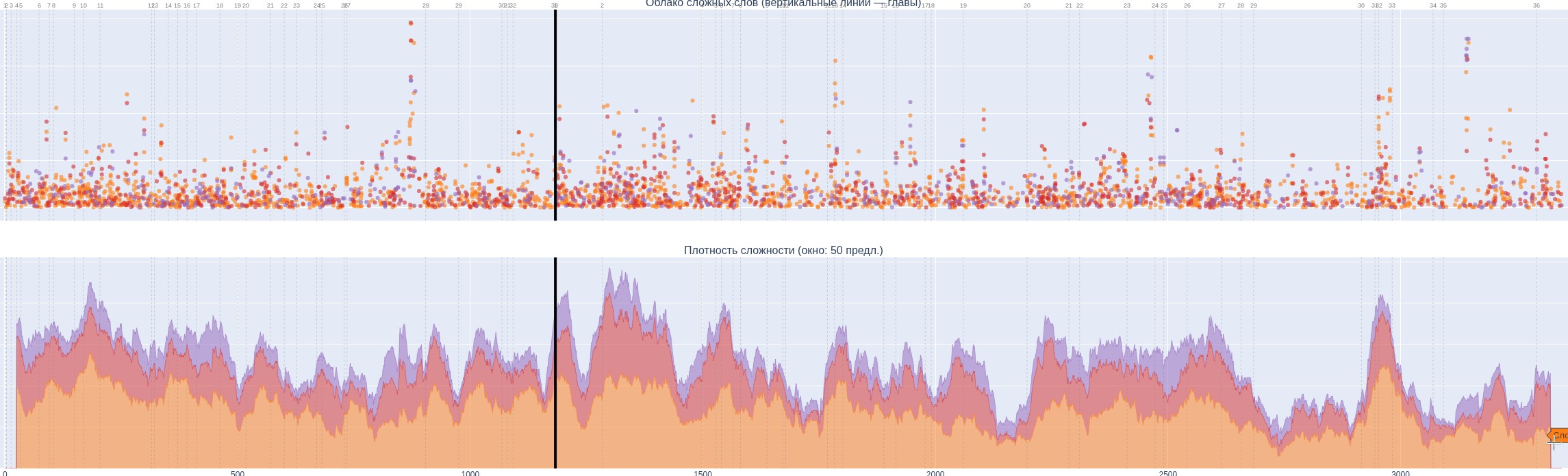
Доделал первую версию книги-словаря по «Лолите» Набокова. На графике показано как распределяется сложность лексики по страницам книги. Нижний график усредняет 25 предложений, по вертикали — число сложных слов, цвета означают сложность/редкость (фиолетовые — самые сложные, красные — менее сложные, желтые — еще менее). Но это я уже убрал еще два уровня, и в целом для иностранца там все пять уровней непростые. В книге пунктиром отмечается уровень 3, простой рамкой — уровень 4, а двойной — уровень 5. Всего сейчас 5794 слова, из которых 541 пятого уровня, 1070 — четвертого, 1883 — третьего, 1393 — второго и 54 — первого (самые простые). Учитывая, что в первой версии получилось 1148 страниц, нужно будет очень сильно подчищать словарь, убирая оттуда то, без чего можно обойтись. Это в существенной степени слова первого и второго уровней, и отдельные из третьего и четвертого. Редкость слов рассчитывается тремя способами : через LLM, и через два списка частот слов англ языка в корпусе текстов (300К слов).
Не все слова сложные. Например, в предложении «With the ebb of lust, an ashen sense of awfulness, abetted by the realistic drabness of a gray neuralgic day, crept over me and hummed within my temples.» наверняка знающему неплохо английский не знакомы слова ebb, abet, drabness, а все остальное знакомо, но чуть снизь требования к читателю, и словарь может быть уже не очень полезным для таких.
Или вот предложение:
Homo pollex of science, with all its many sub-species and forms; the modest soldier, spic and span, quietly waiting, quietly conscious of khaki’s viatric appeal; the schoolboy wishing to go two blocks; the killer wishing to go two thousand miles; the mysterious, nervous, elderly gent, with brand-new suitcase and clipped mustache; a trio of optimistic Mexicans; the college student displaying the grime of vacational outdoor work as proudly as the name of the famous college arching across the front of his sweatshirt; the desperate lady whose battery has just died on her; the clean-cut, glossy-haired, shifty-eyed, white-faced young beasts in loud shirts and coats, vigorously, almost priapically thrusting out tense thumbs to tempt lone women or sadsack salesmen with fancy cravings.
У меня даже браузер подчеркивает тут четыре слова.
У меня есть определения слов на английском, немецком, французском, русском. Я столкнулся с тем, что для разных языков разные слова из текста считаются сложными, а они у меня единые. Так что придется отдельно помечать, например, французские слова в английском тексте, чтобы не включались во французскую версию, так как там читатель знает, например, что такое quel mot.
В общем, на выходных буду убирать, видимо, половину, в ручном режиме, и тогда можно делать обложку и выставлять на Amazon.

Словарь Набокова: Мультиязычное путешествие по текстам писателя | 2026-03-15T18:30:39
Читаю Набокова и решил отвлечься и сделать удобную программку «Словарь Набокова» и подумываю продавать его на Амазоне как книгу. По сути, выглядит это так (см скриншот) — определения сложных слов на английском, русском, немецком и французском, идущих в том же порядке, в каком они идут в оригинальной книге.
Вы бы купили такую книжку?
Для того, чтобы корректно сделать их определения, я также написал aligner — программу, которая сопоставляет предложения и абзацы на английском с их переводами (набоковским) на русский. И когда создается определение слова, используется не только знание LLM, но и перевод на русский автора. Отдельно стоит рассказать, как работает алгоритм (я его сам придумал, потому что все, что нашел в сети, не работало как мне надо). Он находит сначала длинные предложения, и находит для самых длинных предложений их пару через косинусное сходство embedding-векторов, созданных через модель multilingual e5. Эти предложения становятся якорями. Затем, предполагая, что для длинных предложений ошибка почти исключена, находится самое длинное предложение уже между якорями, и все повторяется заново рекурсивно. Там много ситуаций, когда у предложения на русском нет аналога на английском и наоборот, когда предложение разбито на два, или наоборот два слиты в одно. Алгоритм как может это обрабатывает. Результат — очень неплохое качество выравнивания. До такой степени, что ошибки выравнивания уже не получается находить (но наверняка они есть). Так или иначе, оно нужно только для контекста для перевода слов, даже если там и есть редкие ошибки, то не страшно.
Вы бы купили такую книжку?

Искусственный интеллект и нейроморфные процессоры: аналогии в обучении языку | 2026-02-15T15:41:53
Некоторые мысли по поводу LLM и искусственного интеллекта в целом. И в конце про нейроморфные процессоры и Intel Loihi.
Как вы все знаете, фундаментально LLM работают по принципу «предлагай вероятное следующее слово, используя контекст из предыдущих N слов», и затем слово попадает в контекст, и повторяется все заново для следующего слова. Ну еще и контекст там обрабатывается с учетом важности слов.
А теперь задумаемся, как в первобытных обществах учили языкам детей. Никаких азбук не было, как и грамматики. Но вот сама грамматика, по оценкам, была довольно сложной — по наблюдениям за малыми языками малых народов. Простая грамматика — это современное, когда язык распространился на миллионы и миллиарды.
То есть, мозг ребенка должен реконструировать в своих нейронах грамматику просто на потоке речи от окружающих и через тестирование на понимание сказанного. Возможно, ребенка поправляли, если он говорил неправильно, но как-то эта грамматика и звукоизвлечение должны были улечься в мозг — и вот тут используется тот же механизм, что и в LLM: какие слова/звуки идут рядом в каком контексте определяется латентными и не интерпретируемыми правилами, которые каждый человек в детстве создает в своем мозгу на свой лад. То есть, грубо говоря, тренирует модель ML каждый раз с нуля на потоке речи от окружающих. Ребенок не знает, что такое «падеж», но чувствует, какое окончание статистически более вероятно в данном контексте.
Собственно, современная когнитивистика (теория Карла Фристона) утверждает, что мозг — это буквально «машина предсказания». Мы постоянно генерируем гипотезы о следующем звуке или слове и корректируем их при несовпадении (ошибка предсказания).
Особенность LLM в том, что для нее учителя — это тексты и картинки, а для мозга ребенка — это живой мир вокруг, и если все тексты, которые он слышит, оцифровать, то объема не хватит даже на тренировку очень слабой модели. LLM видит слово «яблоко» рядом со словом «красное». Ребенок видит яблоко, чувствует его запах, вкус, вес и одновременно слышит звук. Эта «сшивка» разных сенсорных каналов позволяет выстраивать нейронные связи в тысячи раз быстрее, чем на чистом тексте. То есть, LLM современные берут брутфорсом — просто наблюдают за речью миллиардов, а не только своего ближайшего окружения. Хороший вопрос как мозг человека умудряется научиться на относительно маленьком датасете. Правда, большой вопрос маленький ли это датасет — например, движения губ, мимика, контекст дают очень много для построения этой нейронной сети в биологическом мозгу.
Про контекст: в отличие от LLM, ребенок понимает намерение говорящего. Если мама смотрит на чашку и говорит «горячо», мозг ребенка ограничивает пространство поиска смыслов одной чашкой. И если он не понял, то обожжется и запомнит.
Можно, конечно, предположить, что мозг уже при рождении имеет готовую сеть. Оно так, но наука пока это не может нормально объяснить. Вся наша генная программа насчитывает порядка 20 000 генов, кодирующих белки, и эти 20000 отвечают вообще за все — где и как должны быть построены легкие, сердце, кости, кровь, и сами по себе что ни возьми, все имеет запредельную сложность, и где-то среди 3 млрд нуклеотидов и 20 тыс генов эта информация должна быть записана.
Судя по всему, гены кодируют не карту, а алгоритм самосборки. Фактически, архитектура нейронной сети строится динамически, и начинается этот процесс задолго до рождения. Далее она калибруется по всем сигналам, которые принимает еще не родившийся ребенок, и к моменту рождения в мозгу уже есть как-то настроенная сеть.
Вероятно, что мозг ребенка — это миллионы нейросетей разных «архитектур», которые эволюционно усложняются, объединяются в процессе обучения. В отличие от LLM, где обучение и использование жестко разделены во времени. Но самое главное — мозг хоть и самый энергозатратный в организме, но в абсолютных значения он крайне мало потребляет энергии, особенно, если сравнивать с текущими «кандидатами на заменители в железе».
Последние годы активно идут разработки в области нейроморфных систем (например, процессоры старенький IBM TrueNorth и активно разивающийся Intel Loihi). В обычном AI нейроны передают числа (0.15, 0.88…). В нейроморфных системах они передают «спайки» (импульсы) — как в живом мозгу (и архитектура называется Spiking Neural Network — SNN). Несколько лет назад Intel выпустила Loihi 2. Полностью программируемая. Нейроны на Loihi могут менять свои связи (синапсы) прямо во время работы. Поддерживает пластичность — тот самый биологический механизм, когда связь между нейронами усиливается, если они часто «срабатывают» вместе. Но главное — потребляет очень мало.
В этой архитектуре модель может дообучаться «на лету» прямо во время работы, не забывая старые данные (Continual Learning). Кроме этого — экстремальная энергоэффективность.
Loihi 2 не умеет перемножать матрицы как это делают современные GPU, поэтому для них нужно вообще с нуля писать софт (и движется это очень медленно). Никакого PyTorch или Tensorflow — для Loihi есть только фреймворк Lava на сегодня. Ну и 1 млн нейронов от Loihi 2 для LLM очень мало. Поэтому Intel создает системы вроде Hala Point — это массив из 1152 процессоров Loihi 2. Он содержит до 1,15 миллиарда нейронов. Теоретически, по своей эффективности при работе с AI-моделями такая система может превосходить классические GPU в 10–50 раз по показателю «производительность на ватт».
На Loihi 2 уже запускают экспериментальные LLM (например, модели на 370 млн параметров). Они пока не заменят ChatGPT в облаке, но теоретически они — будущее для «умных» роботов и гаджетов, которым нужно понимать человеческую речь, работая от маленькой батарейки.
Понаблюдаем. Может оказаться пшиком, а может быть еще одной большой революцией.
Планы на 2026: от Галапагосских островов до PhD | 2026-01-20T04:44:36
Мой план на 2026:
— Уехать на неделю на Галапагоссы, в Эквадор (лето)
— Дописать и выпустить книжку по Information Retrieval (тоже лето, идет медленно, пара первых глав уже написана. Уже потратил на эту тему часов 50-100, то, что шло легко)
— Выпустить как минимум одну научную статью, видимо по Data Mining (весна). В идеале засабмиттить куда-нибудь в журнал (сложно). Уже потратил на эту тему часов 30, осталось еще дохрена.
— Сделать шаг к PhD. Найти профессоров, посетить универы, понять цену вопроса и оценить свои возможности и ресурсы.
— Продолжить изучать фундаментальную математику и не умереть (линейная алгебра, матанализ, тервер, статистика, классическое ML). В 2025 потратил на эту тему часов 200-400.
— Продолжить изучать Deep Learning и дойти до уровня «могу преподавать». В 2025 потратил на эту тему часов 100-200.
— Продолжить изучать Data Mining/NLP.
— Актуализировать мою книжку по RecSys, выпустив версию 2.0 включив обновления и исправления (осень 2026)
— Добиться видимого прогресса в живописи и игре на фортепиано. Конкретно, доучить серенаду Шуберта (Ständchen, D 889) и сделать хотя бы один холст, который не стыдно подарить.
Навигация по магнитному полю: технология будущего | 2026-01-10T17:41:09
Узнал сегодня, что сейчас есть и активно используется технология навигации по магнитному полю Земли. Используется как замена или как расширение GPS.
Например, есть скандинавский паром Express 5 компании Bornholmslinjen, который страхуется от проблем с GPS (а они происходят) тем, что использует навигацию MagNav. В отличие от GPS, магнитное поле Земли невозможно заглушить или подменить — оно просто существует. Паром ездит по одному и тому же маршруту, и в целом, там можно навигацию даже через бытовые рыболовные эхолокаторы сделать.
Но вот есть несколько стартапов, которые используют эту технологию для навигации внутри помещения, куда сигнал от GPS не пробивается. Утверждается, что точность навигации — 1 метр. Вот это интереснее.
GiPStech, Oriient, Mapsted.
В основе этой технологии лежит процесс, называемый магнитным фингерпринтингом. Инженеры или роботы-картографы обходят здание со смартфоном, записывая уникальные искажения магнитного поля в каждой точке. Эти искажения создаются стальным каркасом здания, арматурой в стенах и крупным электрооборудованием. Формируется база данных, где каждой координате (x, y, z) соответствует свой уникальный вектор магнитного поля (интенсивность, наклон, отклонение).
Собранные данные загружаются в облачную платформу компании-провайдера. Там они проходят очистку от шумов и «сшиваются» с цифровым планом этажа (Floor Plan). Когда пользователь идет по ТЦ, его смартфон в реальном времени считывает данные со встроенного магнитометра. Специальное ПО (SDK) сравнивает текущие показания с теми, что хранятся в базе данных. Чтобы точность была 1–2 метра, система не полагается только на магниты. Она использует сенсорную фузию — объединяет данные магнитного поля с инерциальными датчиками (акселерометр считает шаги, гироскоп определяет повороты) и иногда сигналами Wi-Fi/Bluetooth для грубой привязки к зоне.
Для дронов эта технология наверняка сейчас активно внедряется. Главная техническая сложность там — собственные помехи и учет того, что магнитное поле меняется, и нужно постоянно обновлять карты. Электрика, двигатели создают сильные магнитные поля, которые «забивают» естественный фон Земли. Но пишут, что используются всякие алгоритмы фильтрации (включая нейросети), которые в реальном времени «вычитают» помехи от моторов из общих показаний датчика. Как я также понимаю, на большой высоте (километры) магнитное поле более «гладкое», поэтому точность ниже (около 1–5 км). Но если дронов несколько летит и они обмениваются сигналами, то в целом они вместе могут дать очень хорошую точность каждого. Кроме того, группа дронов может измерять градиент (скорость изменения) магнитного поля в пространстве, и привязывать местонахождение не к абсолютным значениям, а относительным. По сути, использование группы дронов превращает навигационную систему из набора отдельных приемников в распределенную фазированную антенную решетку, способную фильтровать глобальные помехи и работать с гораздо более слабыми полезными сигналами. Учитывая, что небольшие дроны, способные долго находиться в воздухе, могут выпускаться в воздух сотнями (и стоить копейки), это довольно перспективная область для военных.
Есть интересный стартап, Zerokey. Они выпускают QUANTUM RTLS 2.0. Эта штука дает пространственную точность в 1.5мм. Используется на производстве, например. Их ролик например показывает «часы» на руках рабочего, которые следят за корректностью сборки чего-то там на столе. Тут уже ультразвуковой принцип, и понятно, что к этим «часам» даются стационарные датчики и дальше мультилатерация.

