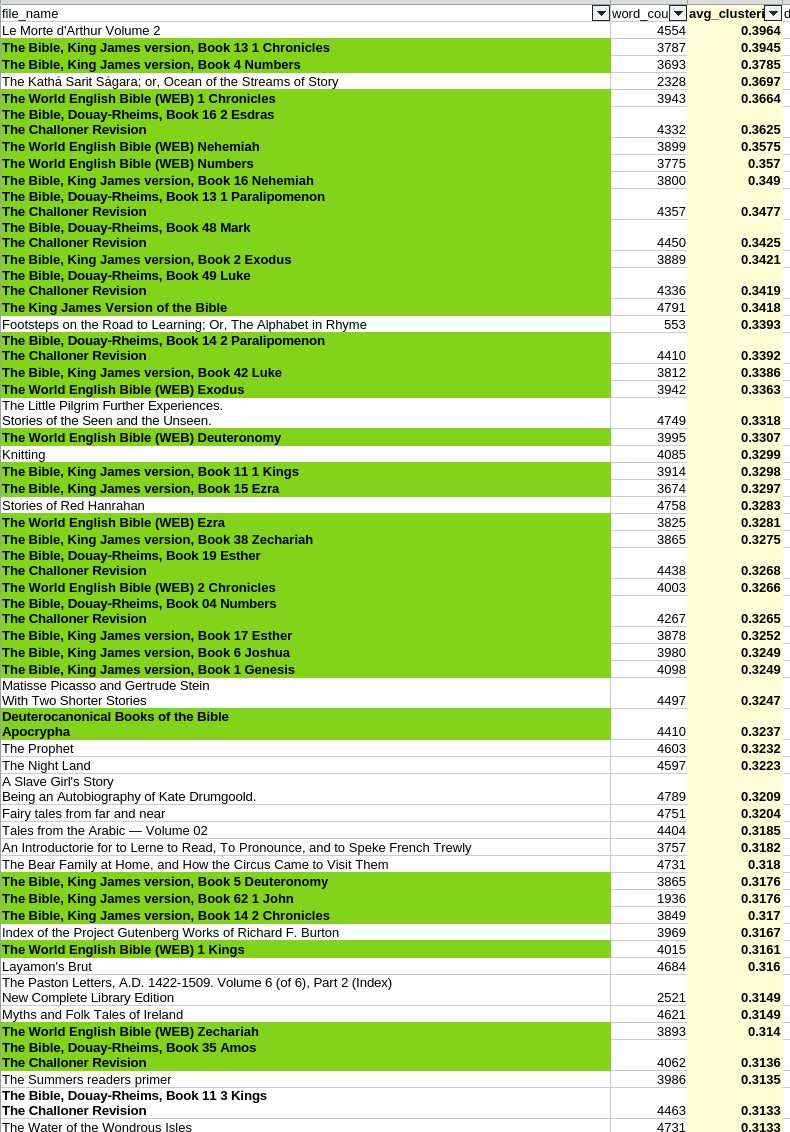
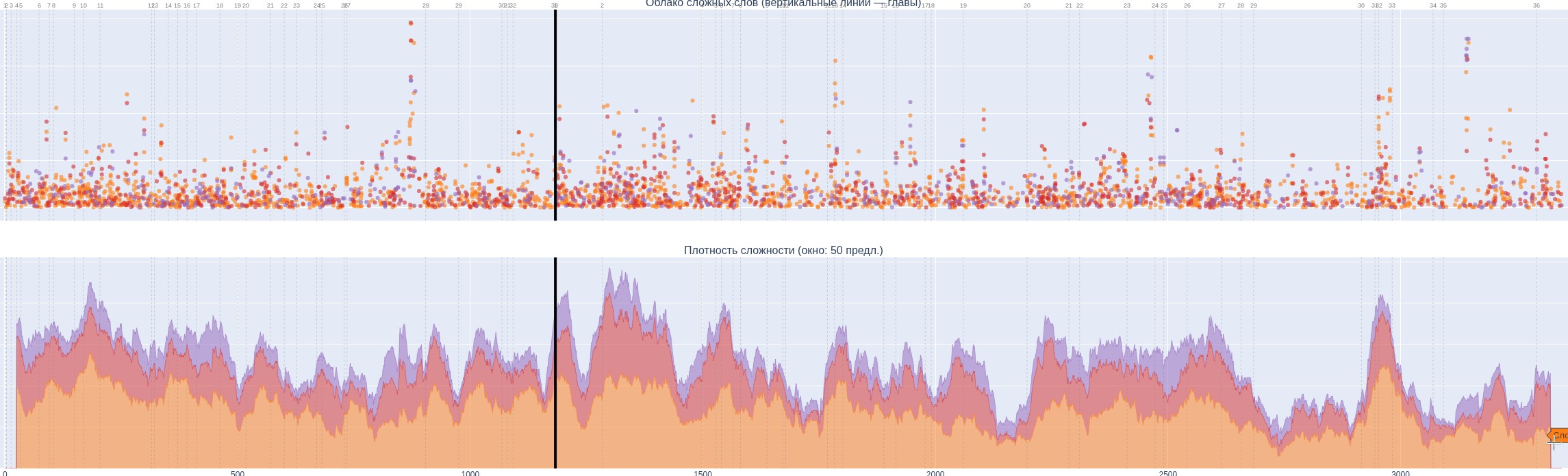
Интересно, что если взять 8000 книг из библиотеки Гутенберга, и по каждой построить по словам граф, чтобы посмотреть, насколько «дружны» слова — если слово А часто встречается с Б, а Б с В, то как часто А встречается с В — для этого есть метрика — средний коэфициент кластеризации, а затем просто отсортировать книги по уменьшению этого коэфициента, то процентов 70 топа будут составлять религиозные книги — библии, книга мормонов, Коран. Ну хорошо, часть из них являются дубликатами в каком-то смысле, потому что Библия в разных вариантах остается Библией. Но тут явно сгруппированы ее разные части, то есть, они явно имеют общность в этих треугольных словах.
Но что объединяет вообще все книги этого топа — это то, что они написаны много лет назад или, как в случае The Night Land, написаны относительно недавно в том же стиле, как много лет назад.
Кстати, среди этих книг светится An Introductorie for to Lerne to Read, To Pronounce, and to Speke French Trewly. Это учебник по французскому языку, написанный на английском языке времен Тюдоров (примерно 1530-е годы). Soverayn lorde kyng Henry the Eight. Написал его Жиль дю Гез (Gilles Du Guez) — учитель французского языка при английском дворе. Этот конкретный учебник был составлен для принцессы Марии (будущей королевы Марии I, известной как «Кровавая Мэри»), дочери Генриха VIII. Зацените страничку из учебника. Очень прикольный английский 🙂 …ye must pronounce it letyng your lippes jointe close, so that there be but a lyttell hole in the middes.
Так вот, я вчитался в этот учебник. Там упоминается фрукт под названием «openarses». Как вы понимаете, это «открытые задницы» по-английски. Так в тюдоровской Англии называли мушмулу (medlar). Если вы погуглите, как выглядит мушмула, у вас не будет вопросов почему это openarses 😉
В анатомическом разделе (MEMBRES LONGYNG TO MANNES BODY) автор рядом с глазами и ушами упоминает «the nether beerde» (дословно — «нижняя борода»).