
Это уже не остановить!












Это уже не остановить!
Юка себе причёску сделал. Ходит модный

Если верить Fox News, Госдеп США бессрочно приостанавливает обработку всех типов виз для граждан 75 стран, в списке которых Россия. Мол, вступят в силу 21 янв 2026 и будут действовать до тех пор, пока ведомство не завершит полную переоценку процедур проверки. Утверждается, что исключения из этого правила будут крайне редкими и возможны только после тщательного прохождения всех проверок.
Причина — стремление ужесточить борьбу с «потенциальной нагрузкой на американскую систему соцобеспечения». Консульские сотрудники должны отказывать в визах тем, кто может стать «общественной обузой» (public charge). Возраст, состояние здоровья, английский язык, финансовое положение среди критериев.
P.S Интересно почему кресел до фига. Десять минут назад я отправил Наде сообщение в iMessage (!) «давай купим кресло маме на Озоне» после того, как мы кресла с мамой по Signal обсуждали. Вроде iMessage не был замечен в сливе топиков. До этого кресла меня не интересовали от слова совсем уже много много лет. Быстро ж рекламные сети приспособились или совпадение такое, не знаю.
Сегодня с удивлением узнал, что сила Кориолиса оказывается произносится как сила КориолИса, а не кориОлиса, как нас в школе учили. Начал разбираться, а что еще не так, и выяснилось удивительное.
Оказывается, то, что у нас называлось законом Гей-Люссака, во всем остальном мире называется Законом Шарля, а то, что у нас называлось Законом Шарля, во всем мире называется Законом Гей-Люссака.
Декартова система координат тут Carthesian. Cartesius — это просто латинизированное имя Рене Декарта.
В наших учебниках закон сохранения массы называется Законом Ломоносова — Лавуазье (что вступило в хим. реакцию = массе образовавшихся веществ). Во всем остальном мире это исключительно Закон Лавуазье (Lavoisier’s Law). Ломоносов тут затесался только из-за «сколько чего у одного тела отнимется, столько присовокупится к другому».
Еще оказалось, что если на английском придется кому-то объяснить теорему Пифагора, то без подсказки вообще невозможно догадаться, что это Пайтагорас. С греческими именами вообще беда. Фалес тут произносится как Тейлиз.
Почему-то Roentgen в физике называют РентгЕном. Хотя он Рёнтген с ударением на ё.
В России трапеция — это четырехугольник, у которого две стороны параллельны, а две нет. В США наша трапеция называется Trapezoid. А словом Trapezium тут называют четырехугольник, у которого вообще нет параллельных сторон. В Великобритании же все наоборот. Наша трапеция — это Trapezium, а «кривой» четырехугольник — Trapezoid.
В русскоязычном сегменте эта новость совсем почему-то не видна, никакие медузы про нее не пишут. Вчера Джером Пауэлл, руководитель Федерального Резерва США, на официальном сайте Федерального Резерва, на главной странице, выпустил видеообращение, в котором сказал, что администрация президента на него и его систему оказывает давление, и частью этого давления является попытка его привлечь за ремонт фасада здания.
ФРС — это «банк банков» и главный печатный станок мира. С 1950-х годов в США действует негласное правило: президент не вмешивается в работу ФРС. Если ФРС начнет печатать деньги или снижать ставки просто потому, что президенту нужно «подстегнуть» экономику перед выборами, доллар обесценится, а инфляция станет неуправляемой.
Цитата:
«Я глубоко уважаю верховенство закона и подотчетность в нашей демократии. Никто, разумеется, включая председателя ФРС, не стоит выше закона, однако это беспрецедентное действие следует рассматривать в более широком контексте угроз со стороны администрации и продолжающегося давления».
«Угроза уголовного преследования является следствием того, что Федеральная резервная система устанавливает процентные ставки, исходя из нашей наилучшей оценки того, что служит общественным интересам, а не в соответствии с предпочтениями Президента. Речь идёт о том, сможет ли ФРС и дальше устанавливать процентные ставки на основе данных и экономических условий — или же денежно-кредитная политика будет определяться политическим давлением или запугиванием.»
Если давление продолжится или Пауэлл будет смещен/арестован, то есть большой шанс, что потеря независимости ФРС может привести к резкому падению курса доллара и росту цен на золото и другие активы.
Как говорил Николай Чапаев в учебном пособии «Введение в курс «Философия и история образования»», «Не дай вам бог жить в эпоху перемен»…
Узнал сегодня, что сейчас есть и активно используется технология навигации по магнитному полю Земли. Используется как замена или как расширение GPS.
Например, есть скандинавский паром Express 5 компании Bornholmslinjen, который страхуется от проблем с GPS (а они происходят) тем, что использует навигацию MagNav. В отличие от GPS, магнитное поле Земли невозможно заглушить или подменить — оно просто существует. Паром ездит по одному и тому же маршруту, и в целом, там можно навигацию даже через бытовые рыболовные эхолокаторы сделать.
Но вот есть несколько стартапов, которые используют эту технологию для навигации внутри помещения, куда сигнал от GPS не пробивается. Утверждается, что точность навигации — 1 метр. Вот это интереснее.
GiPStech, Oriient, Mapsted.
В основе этой технологии лежит процесс, называемый магнитным фингерпринтингом. Инженеры или роботы-картографы обходят здание со смартфоном, записывая уникальные искажения магнитного поля в каждой точке. Эти искажения создаются стальным каркасом здания, арматурой в стенах и крупным электрооборудованием. Формируется база данных, где каждой координате (x, y, z) соответствует свой уникальный вектор магнитного поля (интенсивность, наклон, отклонение).
Собранные данные загружаются в облачную платформу компании-провайдера. Там они проходят очистку от шумов и «сшиваются» с цифровым планом этажа (Floor Plan). Когда пользователь идет по ТЦ, его смартфон в реальном времени считывает данные со встроенного магнитометра. Специальное ПО (SDK) сравнивает текущие показания с теми, что хранятся в базе данных. Чтобы точность была 1–2 метра, система не полагается только на магниты. Она использует сенсорную фузию — объединяет данные магнитного поля с инерциальными датчиками (акселерометр считает шаги, гироскоп определяет повороты) и иногда сигналами Wi-Fi/Bluetooth для грубой привязки к зоне.
Для дронов эта технология наверняка сейчас активно внедряется. Главная техническая сложность там — собственные помехи и учет того, что магнитное поле меняется, и нужно постоянно обновлять карты. Электрика, двигатели создают сильные магнитные поля, которые «забивают» естественный фон Земли. Но пишут, что используются всякие алгоритмы фильтрации (включая нейросети), которые в реальном времени «вычитают» помехи от моторов из общих показаний датчика. Как я также понимаю, на большой высоте (километры) магнитное поле более «гладкое», поэтому точность ниже (около 1–5 км). Но если дронов несколько летит и они обмениваются сигналами, то в целом они вместе могут дать очень хорошую точность каждого. Кроме того, группа дронов может измерять градиент (скорость изменения) магнитного поля в пространстве, и привязывать местонахождение не к абсолютным значениям, а относительным. По сути, использование группы дронов превращает навигационную систему из набора отдельных приемников в распределенную фазированную антенную решетку, способную фильтровать глобальные помехи и работать с гораздо более слабыми полезными сигналами. Учитывая, что небольшие дроны, способные долго находиться в воздухе, могут выпускаться в воздух сотнями (и стоить копейки), это довольно перспективная область для военных.
Есть интересный стартап, Zerokey. Они выпускают QUANTUM RTLS 2.0. Эта штука дает пространственную точность в 1.5мм. Используется на производстве, например. Их ролик например показывает «часы» на руках рабочего, которые следят за корректностью сборки чего-то там на столе. Тут уже ультразвуковой принцип, и понятно, что к этим «часам» даются стационарные датчики и дальше мультилатерация.

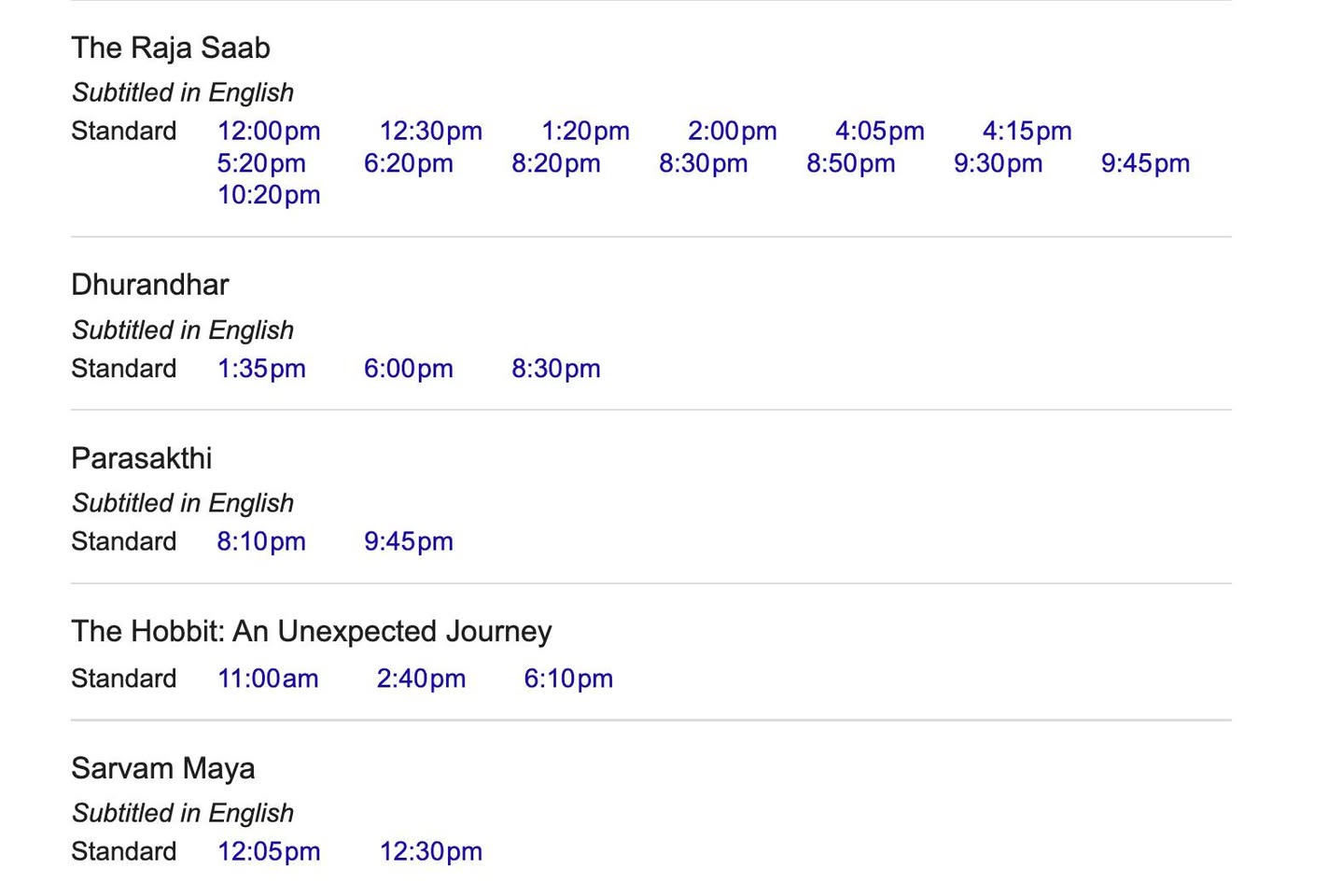
Обратил внимание, что в нашем кинотеатре огромное скопление индусов, и оказывается, что это потому, что кинотеатры и местная индийская диаспора нашли общий язык. Сегодня было 13 показов The Raja Saab на трех языках — тамильском (на нем снят фильм), телугу и хинди. Жанр- fantasy horror comedy. Еще сегодня же были два сеанса Parasakthi на тамильском и два Sarvam Maya на языке малаялам.
Причем только мужчины. Погуглил почему. У таких суперзвезд, как Прабхас (The Raja Saab), есть огромные организованные фан-клубы. В индийской культуре «премьерная ночь» и первые утренние сеансы — это территория хардкорных фанатов — а они преимущественно молодые мужчины. Они приходят, чтобы шуметь, свистеть, танцевать у экрана и выкрикивать всякое разное по ходу. Многие индийские семьи и женщины предпочитают избегать этой «безумной» атмосферы первых сеансов, выбирая более спокойные показы в субботу или воскресенье.
Купили в нашем тайском массажном салоне Origin Thai Spa сегодня вот это все за $20. ломтиками — чай матум, Bael Fruit Tea. Левее него — пандановый чай. Там же перед покупкой попробовали с hand-made тортиками (вкуснотища!).
В салоне работают тайки, все в возрасте, многие плохо говорят по-английски, но все очень хорошо знают своё массажное дело. Мы там постоянные клиенты с мембершипом, местным очень рекомендую салон. Тайский массаж на любителя, впрочем, потому что когда его делают правильно, он довольно больный в процессе (но полезный и ощущение, что заряжает все внутренние батарейки).

Вот интересно было бы иметь камеру где-нибудь в торце телефона, чтобы можно было бы снимать более-менее скрытно.

По поводу Гренландии трампу надо сказать, что в случае сделки Маск туда переедет со своей Теслой. Грин лэнд ж
