Интересно, а существует такой агент, который получает на вход таблицу (эксель), по размерам значительно превосходящую контекстное окно, и начинает ее документировать по сути. Вот есть несколько вкладок. Вот есть на вкладке 5 табличка в миллион строк и пять столбцов. Столбцы такие-то. Берем случайные данные из таблички, так, там вроде числа, а там — фамилии. Делаем предположение, что числа там везде — пишем код, который проверяет это предположение и заодно вычисляет мин/макс и набор уникальных значений. Так, значений немного, всего пять. Запишем. Проверяем теперь фамилии. Да, это просто строки, новый сэмплинг показал, что там фамилии правда. Тут формула. Смотрим куда она указывает. И т.д. А вот эта колонка — неясного назначения. Смотрим на данные — это какие-то числа от 0 до 1. Померяем среднее и разброс. Спросим у пользователя — может, даст какие комменты. Дал. Окалось это выданный kpi этого юзера из внешней системы. Запишем. И так далее. Получается документация. Дальше, когда есть документация, можно просить сделать какие-то операции со всем этим, поскольку LLM уже понимает плюс-минус назначение данных, и их связь, и может строить какие-то гипотезы на выявление outliers и их проверять.
Метка: DataScience
Зачем вашему проекту надсмотрщик за качеством данных? | 2026-05-06T16:07:42
Почти в каждом проекте разработки есть выделенная команда автоматизации функционального тестирования, однако на удивление редко встречается аналогичный акцент на Data Quality. Неважно, идут ли данные из внешних интеграций, от пользователей или генерируются самой системой, часто они остаются без должного контроля просто потому, что почему-то никто не считает это важным, а потом борятся с последствиями — они накапливаются как снежный ком. Чем дольше длятся такие проблемы, тем труднее их устранить, что в итоге приводит к ситуации, когда народ просто смиряется с «непоправимым» состоянием базы. Уж насколько лучше выявлять эти проблемы в момент их возникновения, пока технический долг не стал непреодолимым, чем потом решать, как сделать так, чтобы из-за них ничего не падало;
По сути, надо внедрять постоянного «надсмотрщика» над базами данных всех типов, использующихся системой (реляционных, NoSQL, поисковых индексов или графовых БД) — по сути, это слой проверки качества данных поверх процессов. Конечно, должны быть четкие правила — что именно проверять и какими флагами отмечать конкретные аномалии.
Должен быть ответственный за процесс (кожаный мешок, не AI), который будет интегрировать эти отчеты в рабочие процессы разработки и поддержки. Многие проблемы целостности данных невозможно решить просто через интерфейс — они требуют от инженерной команды разработки скриптов для массового исправления и очистки данных.
Тут кстати еще переходит все в область детектирования аномалий (outlier detection). Машинное обучение и LLM для выявления тонких «плохих» паттернов, которые традиционные системы на основе правил могут пропустить.
Что вы об этом думаете? Внедрены ли подобные механизмы в ваши процессы?

Преобразование чата в семантический поиск вопрос-ответ | 2026-04-30T04:05:37
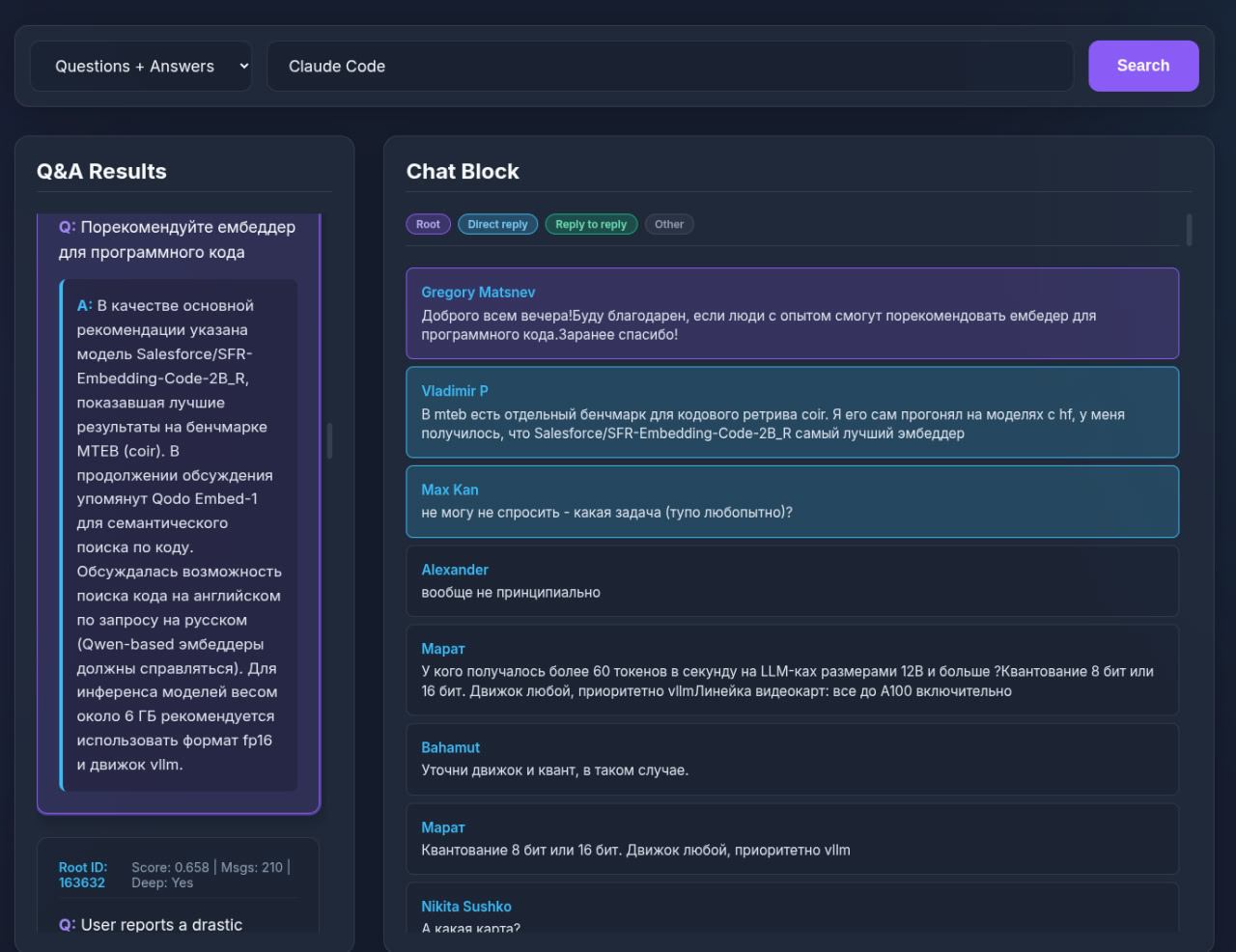
За вечер сделал простую утилитку, которая вытаскивает чат Natural Language Processing за полтора года — там 65 тысяч сообщений, и переводит его в пары вопрос-ответ, по которым есть семантический поиск. При клике на результат поиска (слева) открывается диалог в чате. Подсвечиваются те сообщения, которые являются ответами на вопрос. Ну и сверху подсвечивается вопрос а оригинальной формулировке.
Как работает: система предполагает, что люди в основном делают reply to на сообщения, находящиеся относительно близко в прошлом. Если на одно сообщение делается несколько reply-to, то наверняка оно полезное, и зацепило в чате других. Система берет сообщения, начиная с того, на которое многие отвечали, и заканчивая последним в цепочке reply-to — и среди таких берет те, которые имеют минимум 3 reply-to к оригинальному вопросу. То есть, по сути, она вырезает из чата кусок, начинающийся популярным вопросом так, что после нижнего отреза скорее всего уже идет нерелевантное. Такие блоки могут накладываться друг на друга — например, если кто-то спросил, пока другие отвечали на что-то еще.
То есть, если пользователь А спросил какая погода, и ему ответили «хорошая», «плохая», «дождь», и еще было пять сообщений без reply-to, а потом кто-то ответил на «дождь» вопросом «почему дождь», и на этот вопрос ответили еще пятеро, то в систему попадет первый вопрос про погоду — кусок будет заканчиваться 13 сообщениями.
Дальше эти куски суммаризуются в вопрос-ответ.
Получается прикольно.
П. С. На скриншоте поисковый запрос не имеет отношения к результату поиска, потому что я сдуру сделал скриншот, когда запрос ещё поменял, а отправить ещё не нажал
Сравнение производительности CPU и GPU на примере создания эмбеддингов | 2026-04-11T18:08:07
Когда работаешь с определенными задачами, насколько велика разница между CPU и GPU просто поражаешься. Например, мне вот нужно создавать много (миллионы) эмбеддингов, модель BGE M3. При запуске на моем совсем не слабеньком 24-ядерном процессоре Intel Core Ultra 9 285K создание 500 эмбеддингов занимает 45.85 секунд, а при использовании GPU NVIDIA 5090 точно такая же работа выполняется за 0.36 секунды. Это настолько быстро, что я специально писал этот бенчмарк, чтобы понять, а у меня вообще GPU привлекается или нет. Просто та программа, которая шлет в TEI запросы, делает это в тестовом режиме недостаточно активно (условно пару раз в секунду), и графики GPU просто около нуля показывают загрузку.
— Testing http://localhost:8080/embed — <— CPU version
Requests completed: 500
Total time: 45.85 sec
Throughput: 10.90 req/sec
Average latency (Avg Latency): 4386.11 ms
P95 latency: 5021.88 ms
— Testing http://localhost:8090/embed — <— GPU version (NVIDIA 5090)
Requests completed: 500
Total time: 0.36 sec
Throughput: 1398.69 req/sec
Average latency (Avg Latency): 31.38 ms
P95 latency: 53.18 ms
========================================
RESULT: is 99.22% faster
Глоссарий к «Лолите» Набокова: не просто словарь, а книга-путеводитель | 2026-04-08T11:24:22
Я наконец доделал до конца книгу The Reader’s Glossary — это по сути словарь на 5200 слов по «Лолите» Набокова, но организовыванный не в алфавитном порядке, как обычные словари, а в порядке встречаемости сложных слов, с разбивкой по главам и с указанием контекста слова или фразы. Сайт — readersglossary точка com (в первом комменте). Предполагается, что им будут пользоваться в том числе при чтении оригинала как книга-компаньон. Да, она вдвое больше 🙂
Словарь получился довольно толстым — на 600-700 страниц. Он доступен на четырех языках — русском, английском, французском и немецком. Также перевод (RU, FR, DE) или разъяснение (на англ) не абстрактные, а контекстные, да еще и с учетом того, как тот или иной фрагмент переводил сам Набоков с английского («Лолита» писал сначала на английском, потом переводил на русский).
У меня на сайте есть огромные фрагменты этих словарей RU,FR,DE,EN на ознакомление (каждая — около 1/3 полного объема).
Также полноценный интерактивный словарь на сайте, где можно вбить слово и посмотреть перевод или разъяснение. В словаре собраны в основном сложные слова, но мы знаем, что сложность для каждого имеет свое определение, поэтому все слова разбиты на три категории и выделены разными рамочками. Наверное, для начитанного англофона первая категория (пунктиром) вообще бесполезная (это около 50% словаря), для неначитанного, наверное, процентов 20 бесполезны. Но я решил дальше не резать, потому что книга не только для англофонов, но и для тех, кому английский второй язык, и там эти рамочки пунктирные очень даже кстати.
В целом, я это делал «для себя и друзей», just for fun, а не как коммерческий проект. Поэтому я совершенно трезво понимаю, что аудитория у нее супернишевая, и если хотя бы раз в неделю будет появляться кто-то, кому она может быть полезна, уже приятно.
Несмотря на то, что это было что-то типа хобби, времени книжки потребовали много. Для того, чтобы получить то, что получилось, я разработал с десяток приложений/скриптов, из которых пара имеют свой интерактивный UI, в котором я в общей сложности за два месяца работы провел много часов. И конечно, во многом разобрался, собственно, это и есть главный фан от процесса.
Итак, приходите на сайт — readersglossary точка ком. Ссылка в комментариях
P.S. На русском языке — только как PDF пока. Amazon не дает продавать книги на русском, только на небольшом количестве европейских языков в дополнение к английскому. Французская и немецкая версии словаря выйдут на Амазоне через неделю где-то.

Лексическая карта «Лолиты» Набокова | 2026-04-02T15:56:00
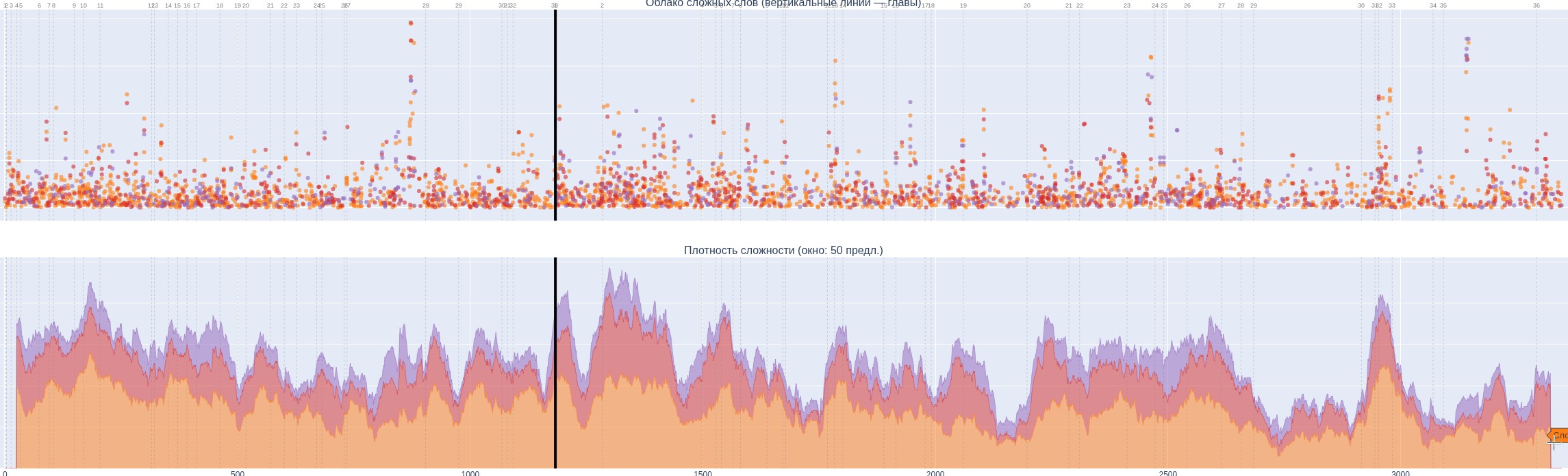
Доделал первую версию книги-словаря по «Лолите» Набокова. На графике показано как распределяется сложность лексики по страницам книги. Нижний график усредняет 25 предложений, по вертикали — число сложных слов, цвета означают сложность/редкость (фиолетовые — самые сложные, красные — менее сложные, желтые — еще менее). Но это я уже убрал еще два уровня, и в целом для иностранца там все пять уровней непростые. В книге пунктиром отмечается уровень 3, простой рамкой — уровень 4, а двойной — уровень 5. Всего сейчас 5794 слова, из которых 541 пятого уровня, 1070 — четвертого, 1883 — третьего, 1393 — второго и 54 — первого (самые простые). Учитывая, что в первой версии получилось 1148 страниц, нужно будет очень сильно подчищать словарь, убирая оттуда то, без чего можно обойтись. Это в существенной степени слова первого и второго уровней, и отдельные из третьего и четвертого. Редкость слов рассчитывается тремя способами : через LLM, и через два списка частот слов англ языка в корпусе текстов (300К слов).
Не все слова сложные. Например, в предложении «With the ebb of lust, an ashen sense of awfulness, abetted by the realistic drabness of a gray neuralgic day, crept over me and hummed within my temples.» наверняка знающему неплохо английский не знакомы слова ebb, abet, drabness, а все остальное знакомо, но чуть снизь требования к читателю, и словарь может быть уже не очень полезным для таких.
Или вот предложение:
Homo pollex of science, with all its many sub-species and forms; the modest soldier, spic and span, quietly waiting, quietly conscious of khaki’s viatric appeal; the schoolboy wishing to go two blocks; the killer wishing to go two thousand miles; the mysterious, nervous, elderly gent, with brand-new suitcase and clipped mustache; a trio of optimistic Mexicans; the college student displaying the grime of vacational outdoor work as proudly as the name of the famous college arching across the front of his sweatshirt; the desperate lady whose battery has just died on her; the clean-cut, glossy-haired, shifty-eyed, white-faced young beasts in loud shirts and coats, vigorously, almost priapically thrusting out tense thumbs to tempt lone women or sadsack salesmen with fancy cravings.
У меня даже браузер подчеркивает тут четыре слова.
У меня есть определения слов на английском, немецком, французском, русском. Я столкнулся с тем, что для разных языков разные слова из текста считаются сложными, а они у меня единые. Так что придется отдельно помечать, например, французские слова в английском тексте, чтобы не включались во французскую версию, так как там читатель знает, например, что такое quel mot.
В общем, на выходных буду убирать, видимо, половину, в ручном режиме, и тогда можно делать обложку и выставлять на Amazon.

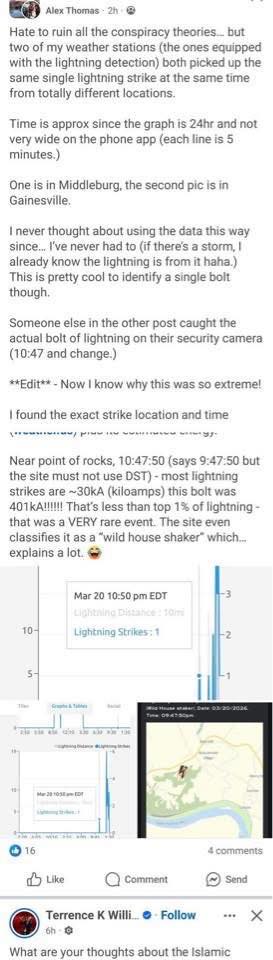
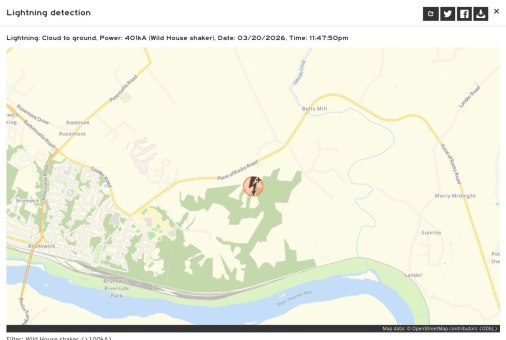
Молния Wild House Shaker: Раритетные 401 kA | 2026-03-21T12:55:02
У нас вчера ночью была гроза. Весь каунти на ушах, потому что все думают, что незадолго от полуночи что-то взорвалось. В соцсетях по несколько сообщений подряд. Короче, это был гром. Но несколько более редкий, чем нормальный. Вызван молнией 401 kA, таким присваивается имя Wild House Shaker. Типичная молния — 30 kA. Если цифрам можно верить, то 401 kA — это прямо очень дохрена. Наверняка скажут, что такой молнии не было десятки лет у нас.
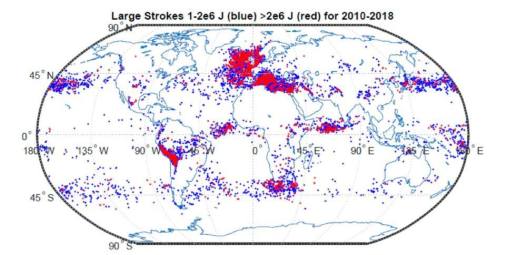
Прикладываю интересную карту.
Точки на карте показывают суперболты — молнии с энергией не менее 1М Дж. Красные точки — особенно мощные суперболты с энергией более 2М Дж. То есть, чаще всего суперболты происходят в северо-восточной части Атлантики и в Средиземном море, а также реже — в Андах, у берегов Японии и возле Южной Африки.
вот что рассказывает та страничка, с которой я взял карту (перевод):
«Новая работа показывает, что суперболты чаще всего возникают над Средиземным морем, северо-восточной Атлантикой и над Андами, а также в меньших количествах — к востоку от Японии, в тропических океанах и у южной оконечности Африки. В отличие от обычных молний, суперболты чаще бьют над водой.
«Девяносто процентов молний происходит над сушей», — сказал Холцворт (это главный чувак по молниям, в универе Вашингтона).
«Но суперболты возникают в основном над водой, вплоть до самой береговой линии. Например, в северо-восточной Атлантике на картах распределения суперболтов хорошо видны очертания берегов Испании и Англии».
«Средняя энергия разряда над водой выше, чем над сушей — это мы знали», — сказал он. «Но это касается обычных уровней энергии. Мы не ожидали такой резкой разницы».
Время года для суперболтов также не совпадает с обычными закономерностями молний. Обычные молнии чаще всего возникают летом — три основных так называемых «дымохода молний» совпадают с летними грозами над Америкой, Африкой к югу от Сахары и Юго-Восточной Азией. Однако суперболты, которые чаще встречаются в Северном полушарии, происходят в обоих полушариях в период с ноября по февраль.
Причина такого распределения пока остаётся загадкой. В некоторые годы суперболтов значительно больше, чем в другие: конец 2013 года стал рекордным, а конец 2014 — вторым по величине, тогда как в другие годы таких событий было намного меньше.
«Мы предполагаем, что это может быть связано с солнечными пятнами или космическими лучами, но оставим это для будущих исследований», — сказал Холцворт.
«Пока что мы лишь показываем, что существует ранее неизвестная закономерность».
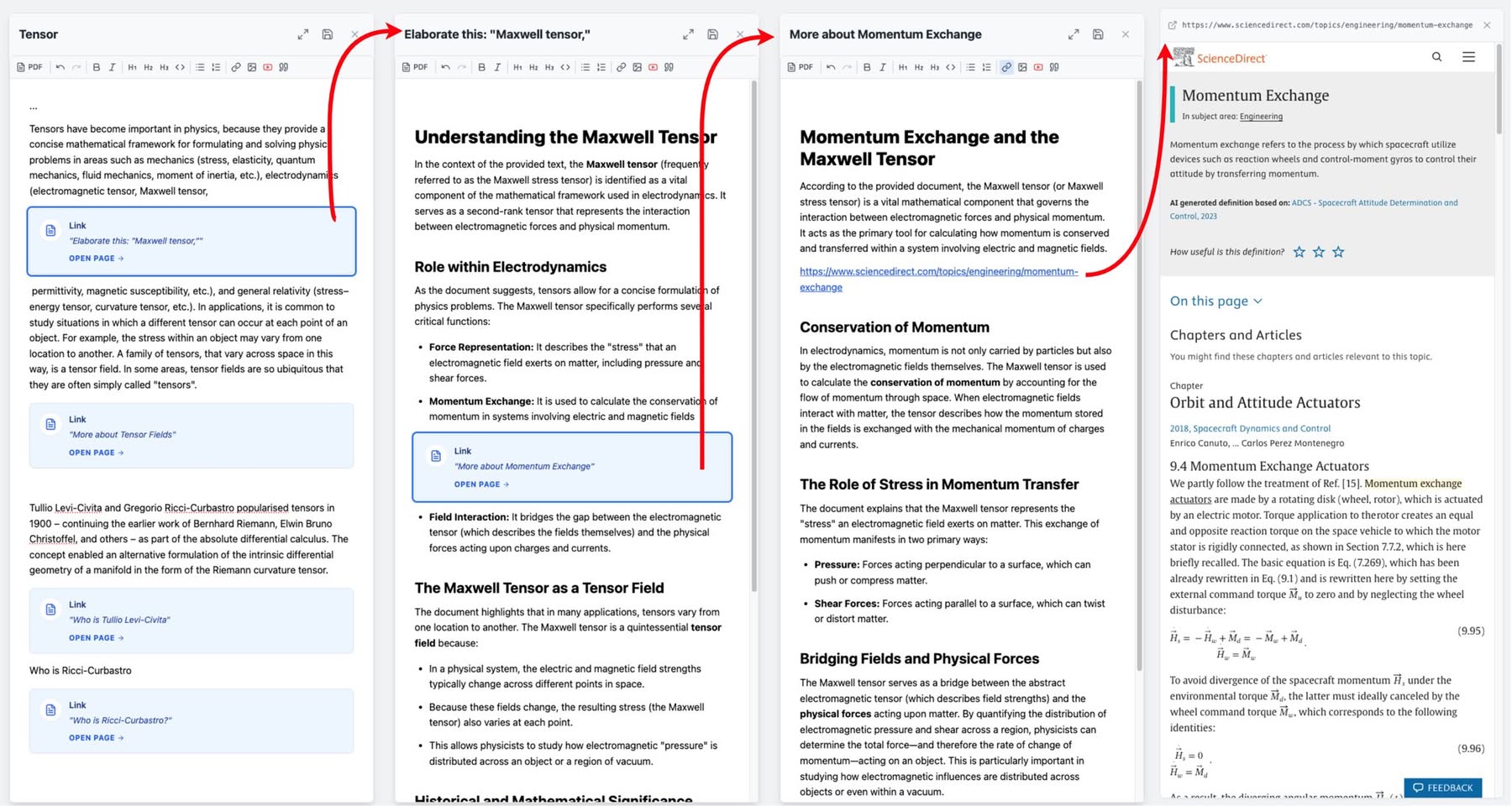
Smartfolio.me: Революция в организации знаний | 2026-03-19T04:01:04
Мое творение — инструмент для организации знаний Smartfolio.me — обросло новыми фичами. Прилагаю видос пятиминутный с обзором.
Это как гугл докс, но документы можно вкладывать друг в друга, создавая целую сеть связанных знаний, и такими документами могут быть и PDF, и обычные тексты.
Закидываешь PDF, программа превращает её в картинки, и можно прямо на страницах выделять любые куски, чтобы оставить коммент или задать вопрос.
Если в тексте что-то непонятно, выделяешь область и жмешь «elaborate» — LLM распишет всё подробно, учитывая контекст всего документа, и объяснение останется ссылкой к выделенному фрагменту.
Можно просто вырезать кусок из PDF, а LLM вытащит оттуда чистый текст или готовую формулу.
В окне с PDF теперь есть своя панелька — там сразу видны все комментарии и разъяснения, так что можно быстро прыгать по нужным местам.
Можно вырезать схему или график из PDF, скопировать как картинку и вставить в свой текст. Она сама обрежется «на лету» и сохранится в базу, но не как копия, а как ссылка на страницу с параметрами кропа.
Если удалил ссылку на страницу в тексте, она не пропадет совсем, а попадет в специальный список, откуда её можно привязать в другое место или удалить окончательно. Один и тот же документ можно вставить в несколько мест. Если добавил в него коммент, он обновится везде, где этот документ прилинкован.
Математика поддерживается полностью — формулы на LaTeX можно не только смотреть, но и кликнуть, чтобы подправить их в редакторе.
Можно генерировать формулы по описанию. Просто пишешь словами, что за формула тебе нужна (например, «биномиальное распределение»), и система сама выдает готовый код формулы.
Теперь есть система плагинов — по сути это изолированные от главной программы экспериментальные функции. Например, есть плагин, который рекурсивно собирает все-все дочерние странички в один длинный документ — удобно, если надо всё сразу прочитать или распечатать.
Или вот плагин «Чистка транскриптов YouTube». Если есть грязный текст лекции с YouTube, плагин сам расставит знаки препинания, параграфы и сделает красивые заголовки.
Если вставишь ссылку на сайт, он откроется в колонке рядом — можно читать источник и одновременно делать свои заметки. При этом некоторые сайты не разрешают себя встраивать в чужие страницы. Система такие сайты опознает, и они открываются в новой вкладке.
Левую панель со списком страниц можно скрывать или менять её размер мышкой, чтобы она не отъедала место на экране.
Можно просто скопипастить изображение или скриншот, и он не просто вставится, а еще и зааплоадится в базу данных.
Поддерживается работа с мобильного телефона. На телефоне интерфейс переключается в режим одной колонки, чтобы было удобно читать и комментировать на ходу.
Поддерживаются несколько баз данных — можно переключаться. Можно подключать разные базы данных и разные LLM и переключаться между ними.
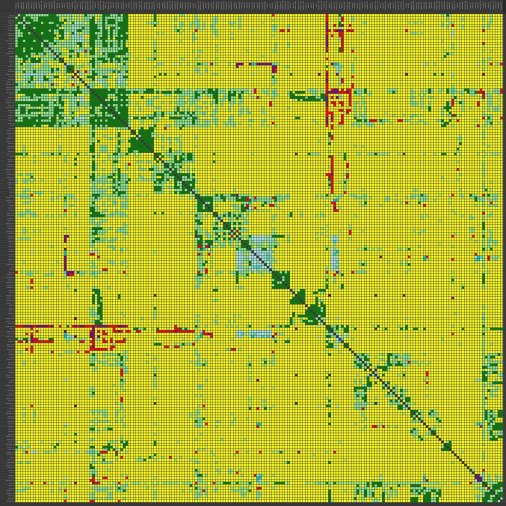
Геополитический расклад: анализ отношений между странами | 2026-03-12T03:29:28
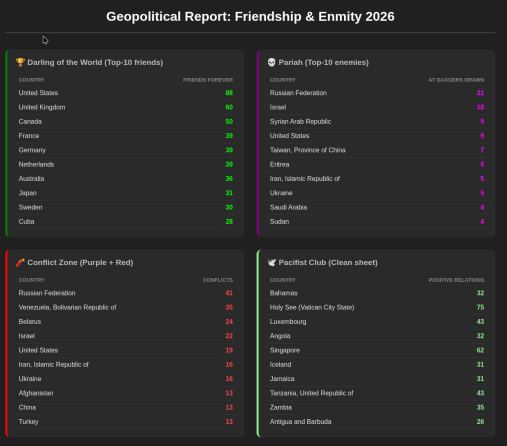
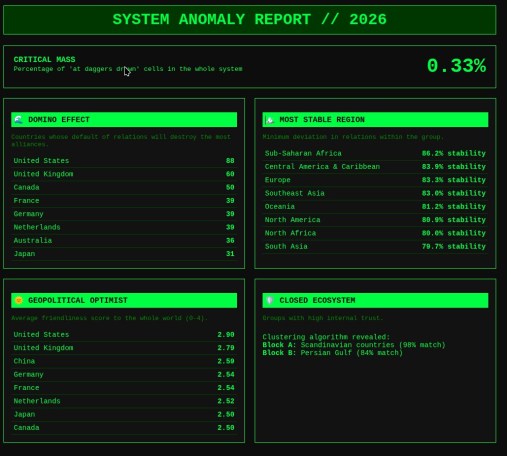
Ради развлечения решил сделать матрицу кто с кем друг и кто с кем враг. Для каждой пары страна-страна я спрашивал у Gemini, в какую из пяти категорий попадают отношения: «на ножах» (фиолетовые), «преимущественно недобрые» (красным), «никакие» (желтым), преимущественно добрые» (голубым), «друзья» (зеленым). Лиза сказала, что «никакие» должны быть фиолетовыми. В целом, качество оценок Gemini неплохое.
Из всех стран выделяются три красные линии. Это страны, у которых не очень с очень много кем. Ну Россию вы правильно угадали. А что за вторая страна? Израиль? Нет, это Беларусь и Венесуэла.
В пятерку стран, с которыми все дружат и которые много с кем дружат, LLM включил США, Великобританию, Канаду, Францию и Германию. Есть антирейтинг — это страны, у которых много с кем очень не ладится («на ножах»). В этом рейтинге на первом месте Россия с 21 страной, и на втором месте Израиль с 18 недругами. Дальше с большим отрывом идут Сирия и США с 9 недругами. Есть отдельный рейтинг Conflict zone — это по сумме красных с фиолетовыми. Россия, Венесуэла, Беларусь, Израиль, США, Иран, Украина.
Есть «клуб пацифистов». Эти те, у которых вообще нет врагов с сортировкой по числу друзей. Рейтинг: Багамы, Ватикан, Люксембург, Ангола, Сингапур, Исландия, Ямайка, Танзания, Замбия.
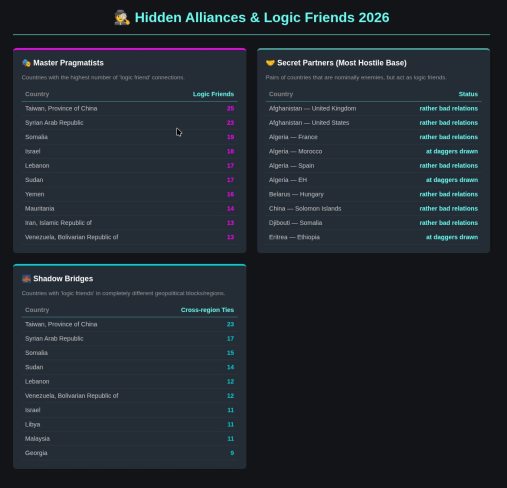
Мне было интересно, а что если применить формулу: враг моего врага — мой друг? Что поменяется? Это привело к новым краскам на матрице — logic friends.
Самым неожиданным лидером рейтинга Master Pragmatists стал Тайвань (25 логических связей). Почему так? В логике LLM, Тайвань — это страна, которая официально признана немногими, но из-за глобального противостояния с Китаем она автоматически становится «логическим другом» для всех, у кого с Пекином натянутые отношения. Это подтверждается и в разделе Shadow Bridges: у Тайваня 23 связи за пределами своего региона. Он буквально «сшивает» разные части света через общую проблему.
Отчет «Тайные партнеры» — список геополитических оксюморонов. Это пары, которые в официальных новостях «на ножах», но по расчету Gemini вынуждены дружить. Например, Афганистан — США/Великобритания. Несмотря на статус «rather bad relations», логика Gemini видит в них «логических друзей». Вероятно, из-за общих региональных угроз (например, ИГИЛ) или зависимости от гуманитарных и теневых каналов. Или вот странный союз «Беларусь — Венгрия». Номинально — разные лагеря, фактически — схожий стиль риторики и общие «недруги» в Брюсселе. Эритрея — Эфиопия: Статус «на ножах», но при этом они попали в логические друзья.
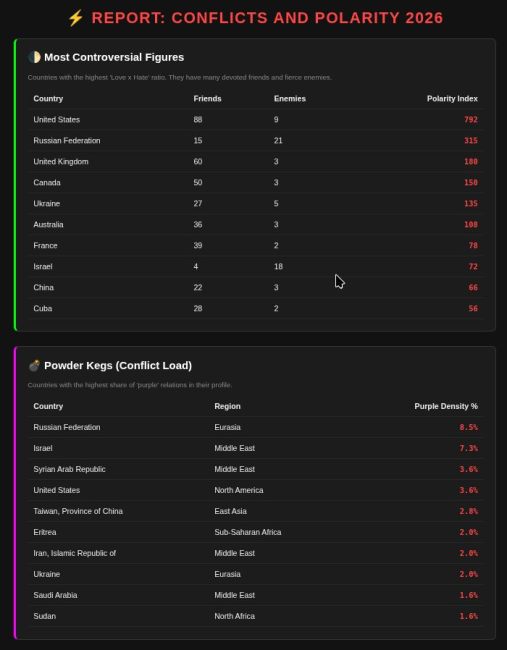
В отчете «наиболее противоречивые» первые места занимают США, и потом с большим отрывом Россия, и еще с большим — Великобритания, Канада, Украина. Это страны с наибольшим значением произведения Love x Hate. То есть, у которых одновременно много и друзей, и врагов.
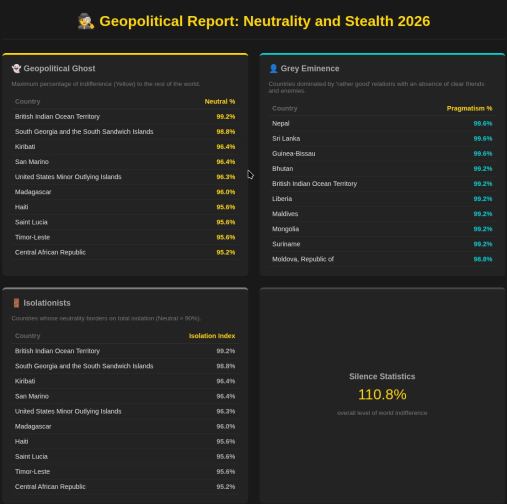
Еще один отчет — пофигисты. Про них LLM не смогла много что сказать, видимо, потому, что они никого не волнуют (как в прямом, так и в переносном смысле). Там например Магадаскар и Гаити.
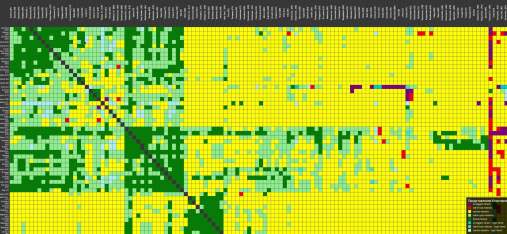
Еще я попробовал кластеризовать по силе друзей и получил четыре группы стран.
Самый масштабный кластер. Ядро: Китай, Россия, Иран, Индия и страны БРИКС+, а также почти весь африканский континент (от Египта до ЮАР) и значительная часть Ближнего Востока (ОАЭ, Саудовская Аравия, Катар).
Во второй кластер попали главным образом европейские страны. Ядро: Франция, Германия, Великобритания. Сюда алгоритм определил Украину и Израиль. Это логично: их выживание зависит от «преимущественно добрых отношений» с европейским ядром. В этом же клубе находятся Армения, Грузия и Сербия. Видимо, несмотря на все политические качели, их связи с Европой Gemini считает более фундаментальными, чем любые другие.
В третий кластер попали США, Канада, Бразилия, Мексика, а также, например, Тайвань. Официально он может быть «логическим другом» для всех врагов Китая, но по «силе друзей» он намертво пришит к американскому блоку. Сюда же попал Ватикан, что делает этот клуб не только экономическим, но и в некотором роде «ценностным».
В четвертый, самый компактный и специализированный клуб, попали страны Океании и Юго-Восточной Азии. Лидеры: Австралия, Япония, Новая Зеландия, Сингапур. Это получился клуб стран, которые пытаются балансировать в самом сложном регионе планеты. Здесь же находятся почти все островные государства (Фиджи, Самоа, Тонга).
Что еще можно попробовать вытащить из этой информации?
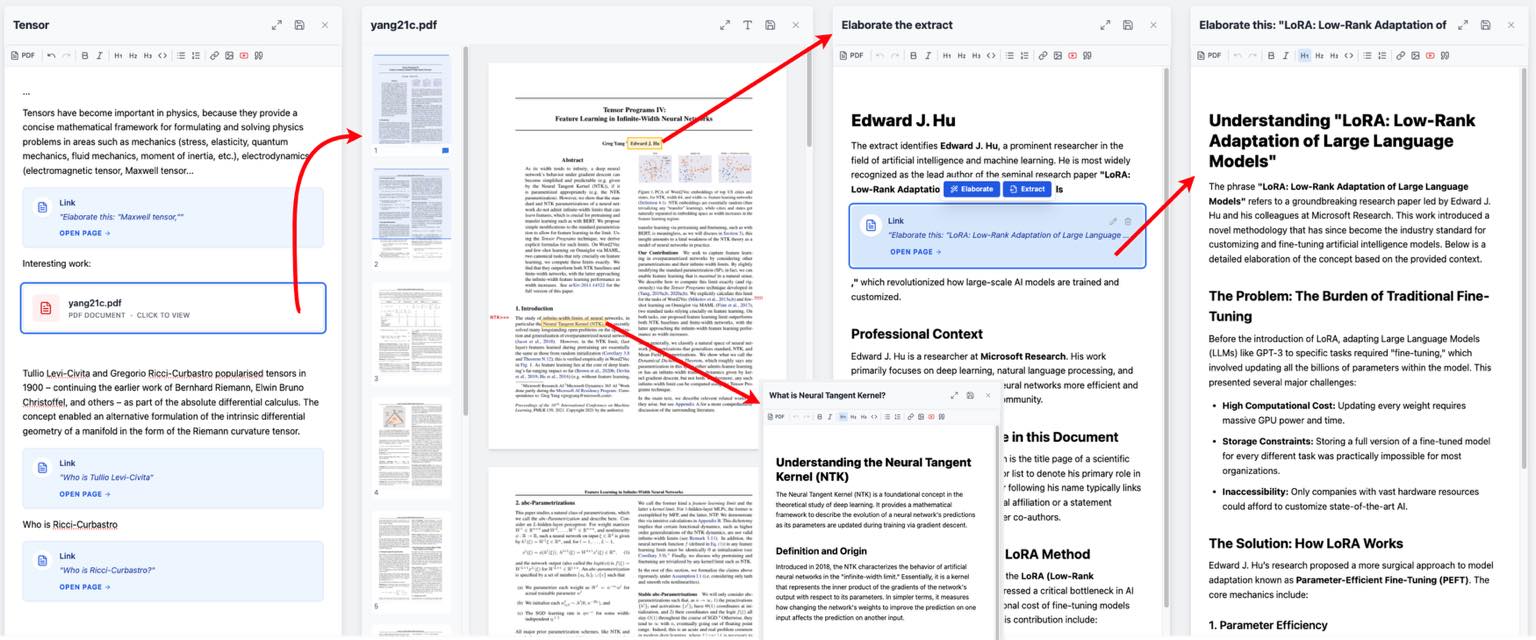
Присоединяйтесь к альфа-тестированию Smartfolio: Графовый блокнот для текста и PDF | 2026-03-03T03:02:14
Ищу альфа-тестеров. В рамках R&D и для собственных задач я написал тул для продуктивности (вообще я об этом в прошлом посте писал, но фейсбук сказал, что из-за того, что я ссылку в пост поставил, меня всего 12% увидели). Сейчас хочу проверить, будет ли он полезен кому-то еще. Если идея вам откликнется — дайте знать, и я поделюсь доступом.
Сайт smartfolio точка me. В чем основная идея?
Это онлайн-блокнот для работы с текстом и PDF, организованный в виде графа. Внешне он напоминает Google Docs, но есть важное отличие: вы можете прикреплять «дочерние» документы к конкретным частям основного текста, чтобы раскрыть детали или прояснить концепции. Эти «комментарии» сами по себе являются полноценными документами и могут иметь свои собственные вложенные ветки.
Если в тексте есть непонятный фрагмент, вы можете попросить систему его объяснить (для этого понадобится ваш ключ Google Gemini API).
Система использует полный контекст документа для генерации ответа.
Объяснения навсегда привязываются к конкретному месту в тексте.
Это супер-удобно при чтении сложных научных статей. Например, можно выделить фамилии авторов в PDF и мгновенно получить бэкграунд по ним — информация прикрепится прямо к этому фрагменту на странице.
Типичный воркфлоу
Загружаете сложный текст и читаете его прямо в приложении хоть с мобилы хоть с компа. По ходу дела добавляете ручные или сгенерированные AI заметки к важным или непонятным разделам на будущее.
Я не храню на своих серверах ваши документы, PDF, картинки или API-ключи. Все данные хранятся в Turso DB (SaaS, бесплатно до 5 ГБ).
Лучше всего о проекте расскажут скриншоты — они есть на главной странице сайта.
Как попробовать?
Для регистрации в приложении нужен инвайт-код. Просто напишите мне в комментарии или в личные сообщения, и я его пришлю.
Сайт смартфолио-точка-me