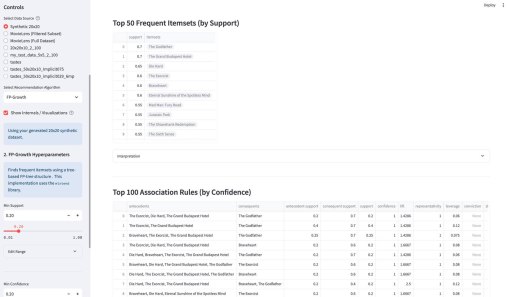
Меня занесло в тему стекла и столько всего интересного узнал, делюсь. Все началось с того, что я прочитал про суперкритическое состояние вещества — оказалось, что линия, разделяющая жидкое и газообразное состояние на графике давления и температуры в какой-то момент обрывается, и дальше находится состояние вещества, которое ни то, ни сё. Начал читать про состояния (фазы) веществ, и наткнулся на то, что стекло это по сути состояние между жидким и твердым. Мол, оно течет, просто медленно. Этот миф популярен благодаря наблюдениям за средневековыми окнами, где стекло часто толще внизу, что приписывали «течению» под действием гравитации, и он даже упоминался в школьных учебниках. На самом деле стекло — это аморфное твёрдое тело с чрезвычайно высокой вязкостью при комнатной температуре, и оно не течёт заметно даже за миллиарды лет; неравномерная толщина старых стёкол объясняется технологиями производства, когда более толстый край устанавливали вниз для устойчивости.
Дальше полез почитать про стекло еще. Оказалось, что причина, по которой стекло может быть прозрачным коренится в квантовой механике, конкретно в электронной структуре материала, а не из-за плотности частиц. Суть в том, что для поглощения фотона электрон должен перейти с одного энергетического уровня на другой, но в диоксиде кремния ширина запрещённой зоны (band gap) настолько велика, что энергии фотонов видимого света физически не хватает для совершения этого «прыжка». В результате свет просто не может взаимодействовать с электронами и проходит сквозь материал насквозь, в то время как более высокоэнергетичное ультрафиолетовое излучение уже способно преодолеть этот барьер и поэтому поглощается стеклом.
Еще оказалось, что расплавленное стекло проводит ток. Причем механизм проводимости принципиально отличается от того, как проводят ток металлы. В медном проводе ток — это поток свободных электронов. В холодном стекле (изоляторе) электроны жестко связаны, а ионы заблокированы в твердой решетке.Но когда вы нагреваете стекло до расплавленного состояния (обычно выше 1000 градусов для силикатных), тепловая энергия разрушает жесткие связи решетки и стекло становится жидкостью, и ионы получают свободу передвижения. Ток в расплавленном стекле — это физическое перемещение заряженных атомов (ионная проводимость), а не просто «перетекание» электронов.
Зеленый оттенок, который вы видите с торца обычного стекла (как на картинке приложенной), оказывается, вызван ионами железа, присутствующими в виде примесей (~0.1%). Песок — это природный материал, и «вычистить» из него железо до нуля сложно и дорого. Осветленное стекло, где в десятки раз меньше ионов железа, оказывается, используют в солнечных панелях, и не для того, чтобы оно просто было прозрачнее. Железо жадно поглощает инфракрасный спектр (тепловую энергию), снижая КПД панели. Убирая железо, мы позволяем максимуму энергии дойти до кремниевых ячеек.
Ну и напоследок, самое «взрывающее мозг» (в буквальном смысле). Существуют так называемые «Батавские слёзки» (Prince Rupert’s drops). Если капнуть расплавленным стеклом в ледяную воду, внешняя оболочка капли остывает и затвердевает мгновенно, в то время как внутренняя часть всё ещё остаётся жидкой. Остывая, сердцевина пытается сжаться, но застывшая корка ей не дает. В итоге внутри капли консервируется колоссальное механическое напряжение (до 700 МПа).
Физика этого процесса создает парадокс: «головку» такой капли можно бить молотком, и она выдержит, так как сжатие поверхности делает её невероятно прочной (тот же принцип используется в закаленном стекле смартфонов). Но стоит лишь надломить тонкий хвостик, как баланс сил нарушается, и волна разрушения проходит по капле со скоростью пули (около 1,5 км/с), превращая её в стеклянную пыль прямо в руках.
А еще в физике есть понятие «металлические стёкла» (amorphous metals). Если охладить расплавленный металл со скоростью миллион градусов в секунду, атомы не успеют выстроиться в кристаллическую решетку и застынут в хаосе. Такой «стеклянный металл» обладает уникальной магнитной проницаемостью и прочнее титана, потому что в нём нет дефектов кристаллической решетки, по которым обычно идет разрушение. Так что стекло — это гораздо более широкое понятие, чем просто прозрачная субстанция в наших окнах 🙂
Единственный пример штучки из этого материала, аморфного металла, Liquidmetal, который я встречал — не поверите , скрепка iPhone.
Кстати, та самая аморфная структура стекла, о которой я писал выше, даёт ему неожиданное преимущество — сверхъестественную остроту. Если взять скальпель из лучшей хирургической стали и посмотреть на него под электронным микроскопом, его лезвие будет похоже на рваную пилу. Это неизбежно: сталь состоит из кристаллических зерен, и заточить её ровнее размера зерна невозможно.
А вот обсидиан (вулканическое стекло) при раскалывании дает кромку толщиной всего в 3 нанометра (это примерно 1/30000 толщины человеческого волоса). В этом нет магии, просто у стекла нет кристаллической решетки, которая мешала бы сделать идеально ровный скол вплоть до молекулярного уровня. Поэтому обсидиановые скальпели до сих пор используют в сложнейших операциях на глазах — разрез получается настолько чистым, что клетки ткани травмируются минимально, и заживление идет быстрее.
И еще один мощный инженерный кейс — витрификация (остекловывание). Именно стекло человечество выбрало как самый надежный «сейф» для ядерных отходов. Жидкие радиоактивные отходы смешивают со специальными добавками, плавят и остужают в блоках. Хитрость в том, что опасные изотопы не просто залиты внутрь, они химически встраиваются в атомную сетку стекла. Стекло химически инертно, оно не ржавеет, как металл, и не разлагается тысячи лет. Это, пожалуй, единственный материал, которому инженеры доверяют хранение опасных веществ на геологических масштабах времени. Да, на разложение выброшенной вами бутылки уйдет где-то миллион лет.
Ну и последнее. Если копнуть в историю, выясняется, что римляне занимались нанотехнологиями за 1600 лет до того, как мы придумали само это слово. В Британском музее стоит «Кубок Ликурга» (IV век н.э.). Если смотреть на него при обычном освещении — он зеленоватый и непрозрачный. Но если поместить источник света внутрь кубка, стекло вспыхивает ярко-красным рубиновым цветом.
До 1990-х годов ученые не могли понять, как это сделано. Электронный микроскоп показал: римские мастера добавили в стекло золото и серебро, размолотые до наночастиц размером около 50 нанометров (это в 1000-1800 раз тоньше волоса). Именно такой размер частиц запускает квантовый эффект поверхностного плазмонного резонанса: электроны в металле начинают колебаться так, что поглощают одни длины волн и пропускают другие в зависимости от угла падения света. Самое смешное, что римляне сделали это эмпирически, «на глаз», а мы только сейчас научились повторять это сознательно в фотонике. Ну насколько можно на глаз оперировать золотой пылью 50 нм. Этот момент потребовал дополнительного гуглежа.
Римляне вряд ли могли механически размолоть металл до 50 нанометров — у них не было таких жерновов.
Вероятнее всего, они добавляли золото и серебро в виде солей или фольги в расплавленную стеклянную массу. Наночастицы образовывались не путем дробления, а путем кристаллизации и осаждения из расплава при очень точном температурном режиме («наводке» стекла). Это еще более сложная химия, чем просто помол.
Самое поразительное не то, что они это сделали, а то, что пропорция золота к серебру была выдержана идеально. Если изменить концентрацию золота всего на 1%, цвет уже не будет таким чистым рубиновым. Это говорит о том, что мастера владели технологией невероятно точно, хотя, вероятно, не понимали механизма. Ну и то, что у них было дохрена времени на всякую ерунду;) видимо, много поколений положили на это жизнь экспериментов. Потому что непонятно зачем это все.
Существует красивая гипотеза (не доказанная, но популярная), что кубок мог использоваться как детектор. Если налить в него другую жидкость (например, спирт с примесями или яд), коэффициент преломления меняется, и цвет «вспышки» может измениться.