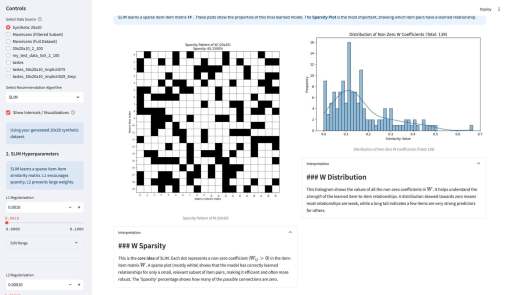
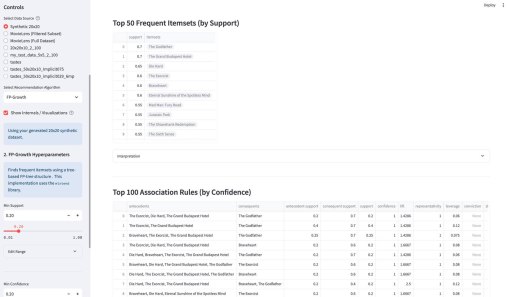
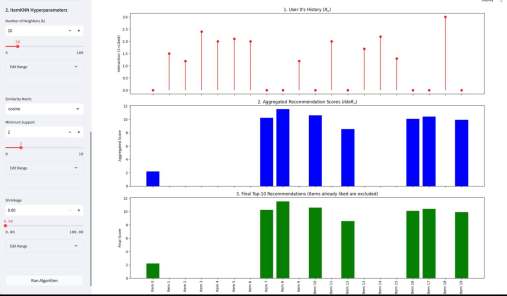
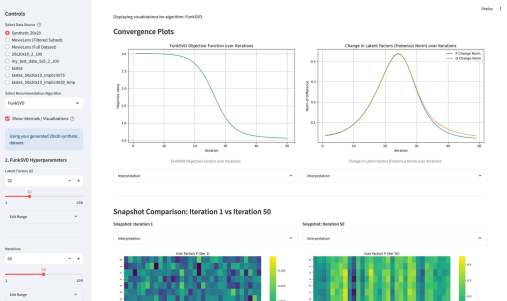
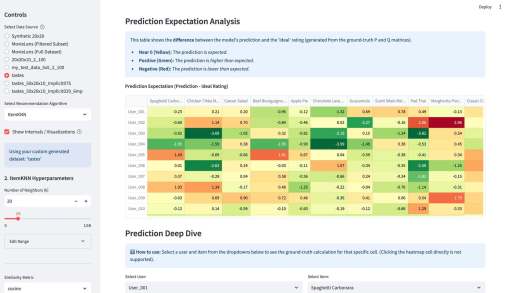
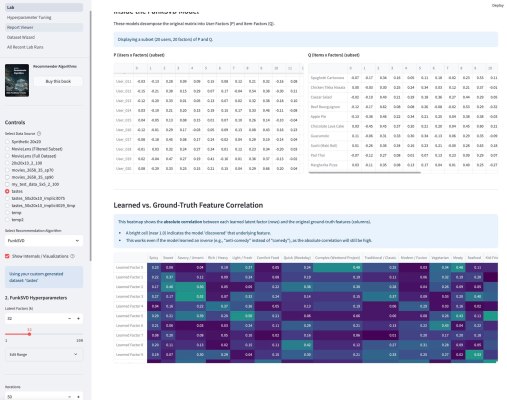
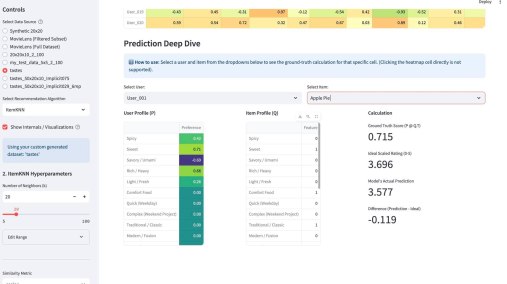
У меня вышло электронное open source приложение к моей книжке Recommender Algorithms! Это «песочница», где можно «погонять» различные алгоритмы рекомендаций с разными настройками, и по каждому алгоритму посмотреть специфичную ему визуализацию, помогающую понять как он работает. Например, для таких алгоритмов как ItemKNN, SLIM или EASE ключевой визуализацией является heatmap, выученной матрицы схожести (item-item similarity matrix). Это позволяет увидеть, какие именно пары товаров модель считает «похожими» (или «влияющими» друг на друга). Для SLIM, например, полезна «Sparsity Plot» , показывающая, что матрица схожести действительно получилась разреженной. Для алгоритмов ассоциативных правил (Apriori, FP-Growth, Eclat) визуализация — это вообще не график, а интерактивные таблицы с найденными «Частотными наборами» (Frequent Itemsets) и сгенерированными «Правилами» (Association Rules) , которые можно фильтровать и сортировать.
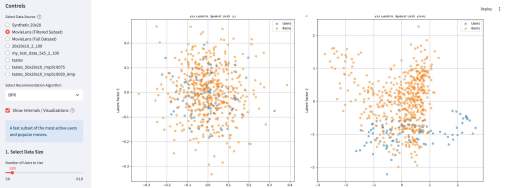
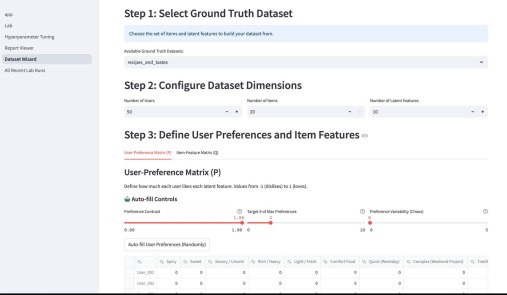
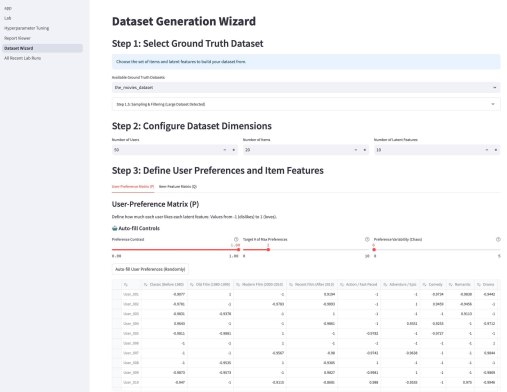
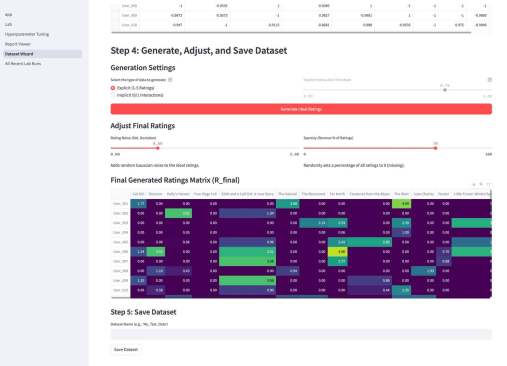
Кроме этого, там есть параметрический механизм создания «игрового датасета» — Dataset Wizard. Работает он так — есть шаблонные датасеты, которые описывают items через характеристики. Например, рецепты через вкусы. Или фильмы через жанры. Система генерирует случайных пользователей со случайным набором характеристик из того же набора — причем там много ползунков, позволяющих это распределение сделать более контрастным или сложным. Далее создается уже матрица оценок пользователями айтемов — условно если совпадают характеристики пользователя и айтема, то оценка будет выше, так как «совпадают вкусы» и наоборот, если различаются, то оценка будет ниже. Тут тоже ползунки, добавляющие шум и scarcity — рандомно удаляется часть матрицы. На вход алгоритму рекомендаций характеристики товаров и пользователей не подаются, они скрыты, но они используются для визуализации результатов.
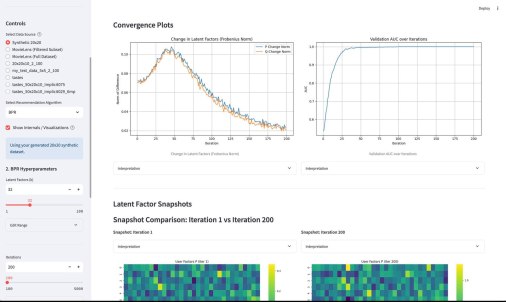
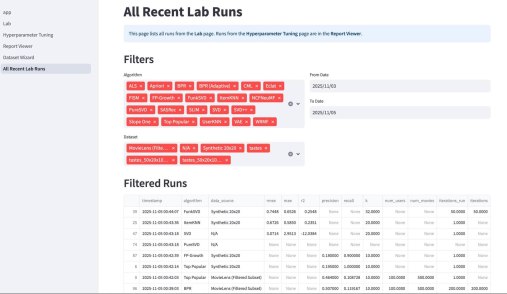
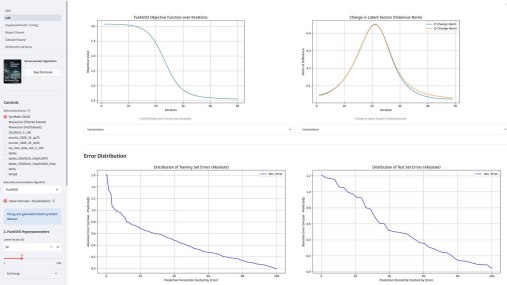
Третьим компонентом приложения является подбор гиперпараметров. По сути, это автоконфигуратор под конкретный датасет. Там используется итеративный подход, который намного эффективнее, чем полный перебор (Grid Search) или случайный поиск (Random Search). Если говорить кратко, система анализирует историю прошлых запусков (trials) и строит вероятностную «карту» (суррогатную модель) того, какие параметры, скорее всего, дадут лучший результат. Затем она использует эту карту, чтобы по-умному выбрать следующую комбинацию для проверки. Этот метод называется Последовательная оптимизация на основе суррогатных моделей (SMBO).
Код свободный, будет еще дополняться новыми алгоритмами и новыми визуализациями.
Ссылочка на код в комментариях.
Ссылочка на сайтик, где код развернут и где можно посмотреть на приложение, тоже в комментариях.