Заумный пост сегодня. Пока писал книгу по RecSys, поймал себя на мысли, что современный data science — это, по сути, алхимия 21 века. За половиной «лучших практик» в алгоритмах нет хорошего математического аппарата. Это набор эвристик, которые «просто работают». Причем как в 17 веке смешивали все подряд, так и сейчас смешивают, и если что-то сработало лучше, все остальные начинают делать так же. Ответа на вопрос «почему» просто нет.
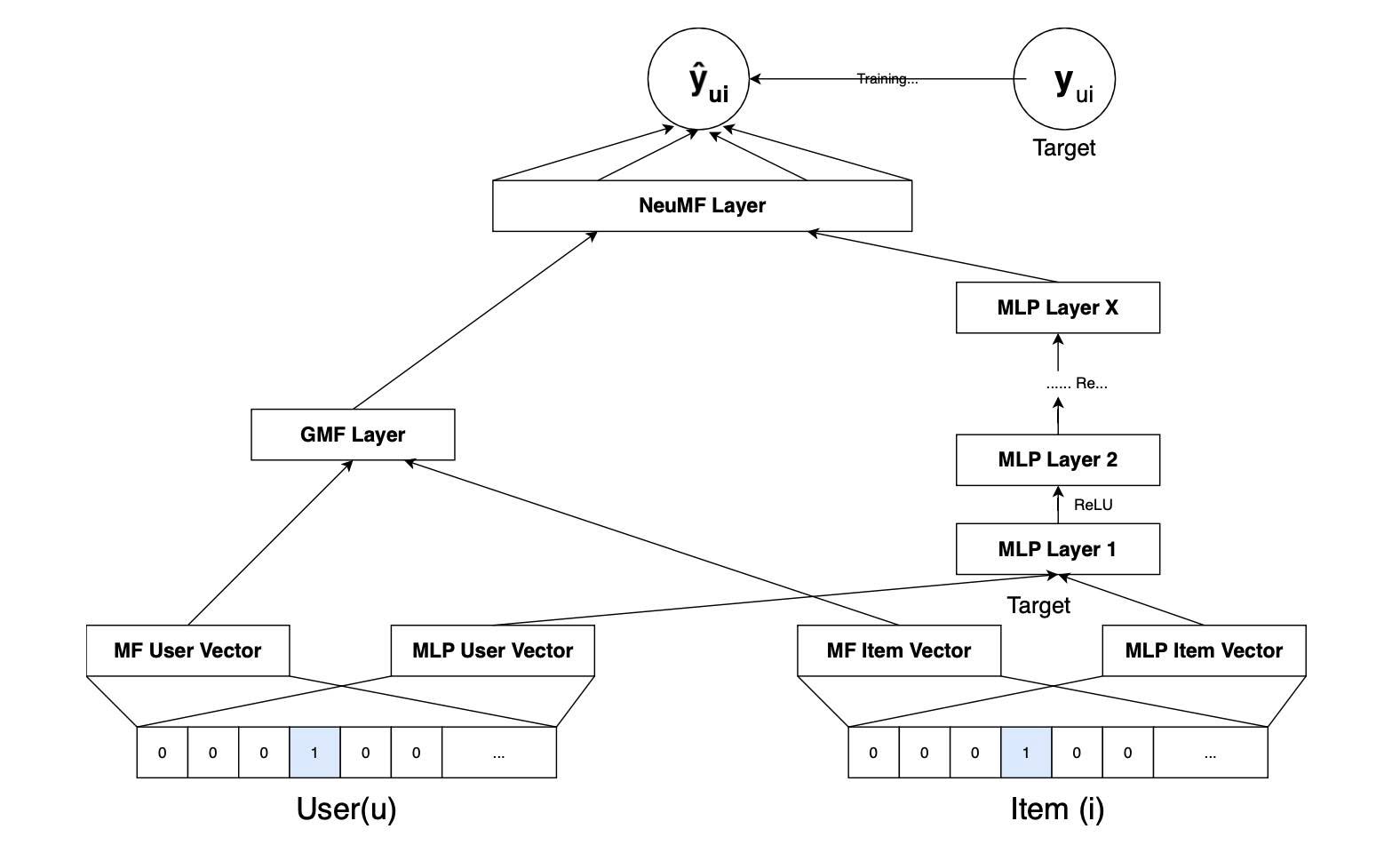
Возьмем, к примеру, алгоритм NCF/NeuMF (Neural Collaborative Filtering). Там такая логика. Есть, скажем, миллион оценок пользователями фильмов. И 100 миллионов оценок пользователями еще на даны — пользователи ж не могут посмотреть все фильмы на свете. Но из этих 100 миллионов для конкретного пользователя надо выбрать кандидатов для рекламы. У алгоритма, конечно, есть фаза тренировки, когда рассчитываются веса, и стадия предсказания, когда эти веса используются на входящих данных.
(Что делает алгоритм. Там по сути ансамбль из три подалгоритмов, два из которых генерят каждый свое заключение, а потом их решения поступают на новую нейронку, третий алгоритм, который дает финальную рекомендацию. По-умному это гибрид GMF (матричная факторизация) и MLP (многослойный персептрон) Первый из этих двух основан на разложении матриц, а второй представляет собой нейронную сеть из нескольких слоев. На тренировочных данных подбираются веса.)
На один позитивный пример он берет 4 негативных. Потому четыре? Да просто это «не много и не мало». Будет ли 8 лучше? Неизвестно, но учиться будет точно дольше.
Почему размерность эмбеддингов 32? или 64? Нет никакой формулы. Это «золотая середина» между «тупой» моделью (мало k) и «переобученной» (много k).
Теперь про нейронку. Почему MLP-блок строят «башней» (64 -> 32 -> 16)? Почему не (50 -> 25 -> 10)? Почему между ними ReLU (а не tanh например)? Чистая эмпирика. Число слоев в башне тоже подбирается.
Почему у GMF и MLP-частей разные эмбединги на входе? Потому что авторы статьи попробовали, и так «получилось лучше». Мат. доказательства нет. Почему на финальный слой они идут с равными весами? Потому что потому.
Почему выходы двух путей «склеиваются» (concat), а не складываются или перемножаются? «Опыт показал, что так результат точнее».
И так во всем, вплоть до выбора оптимизатора Adam или «магического» learning_rate=0.001, хотя с этими по крайней мере понятен матаппарат.
То есть, у одного алгоритма как минимум с десяток параметров подобрано эмпирически, при этом однозначной уверенности, что они независимые друг от друга — нет. Зато многие из них зависят от датасета, но никто не знает как 😉
В общем, алхимия.