
Смотрю какие у нас в каунти есть открытые данные для поиграться с анализом данных на выходных, и обнаружил, что есть, например, открытая база данных всех 1.5 млн деревьев графства. На скриншоте очень маленькая часть вокруг моего дома
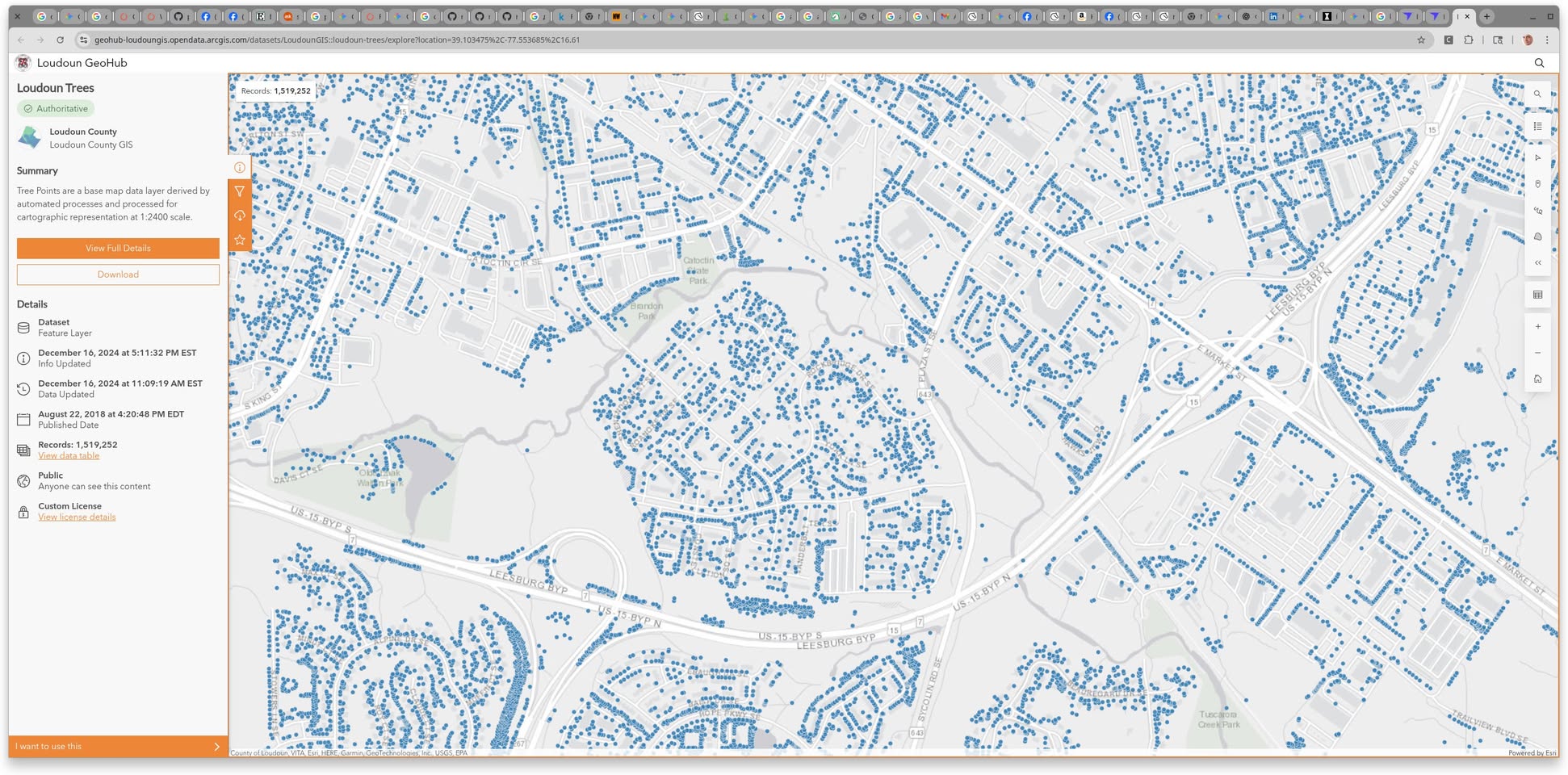
Смотрю какие у нас в каунти есть открытые данные для поиграться с анализом данных на выходных, и обнаружил, что есть, например, открытая база данных всех 1.5 млн деревьев графства. На скриншоте очень маленькая часть вокруг моего дома
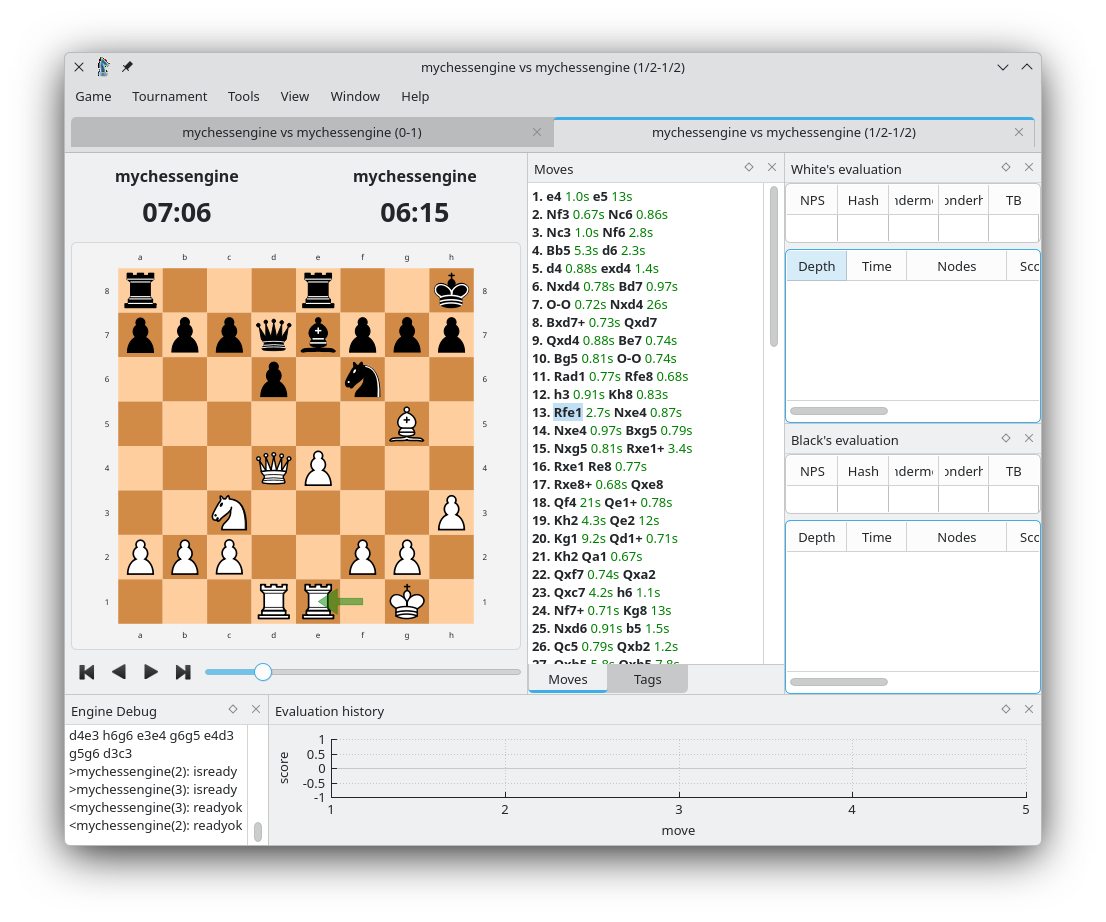
Пока разбирался с нейросетями, решил придумать себе игровую задачку. А что если я найду где-то готовые партии, и обучу нейросетку предсказывать ход по ситуации на доске. Сказано — сделано. Конечно, код быстрее генерить с помощью LLM, но задание подробное писал сам и архитектуру придумывал сам. Через 40 минут (!) от идеи до результата: у меня уже было работающее решение, которое ну по крайней мере в первой половине партии не очень сильно косячит.
На скриншоте CuteChess — он работает с любым шахматным движком, и в моем случае это простой скрипт на питоне. Скрипт берет ситуацию на доске и скармливает ее модели. Выбирает топ 5 ходов, и только эти топ 5 просматривает вглубь на несколько ходов вперед и оценивает позицию. То есть, нейросеть у меня предлагает возможные ходы на основе анализа 20000 партий (534453 позиций). Из того, что получается, выбирается лучшее. Там используется для этого алгоритм minimax, если это кому-то что-то говорит (мне не очень говорило, поэтому Gemini тут мне помог)
Как тренируется модель. На сайте lichess можно скачать партии, там сотни гигабайт. Я взял файлик с 800000 сыгранными партиями за 2014 год. Из этих 800000 я отбираю 20000, а именно скриптом ищу партии, где результат не ничья (1-0 или 0-1). Далее считаю разницу (Рейтинг_Победителя минус Рейтинг_Проигравшего). Это не самая лучшая метрика, но лучше, чем ничего. Чем больше эта разница, тем «увереннее» должен быть выигрыш (сильный наказывает слабого). Итого получается 20000 таких партий.
«Игнорирование ходов слабого» (чтобы модель не учить плохому) реализуется на этапе тренировки модели. Фактически, логика такая: «Если сейчас ход белых, и белые выиграли эту партию — учимся. Если сейчас ход черных, и черные проиграли — пропускаем и не учим сеть этому ходу» .
Нейросеть тренируется батчами по 128 позиций за раз. Сеть получает на вход позицию на доске и выдает 4096 — оценку вероятности для каждого возможного хода.
Отбор партий занимает минут 5. Тренировка модели у меня на компе занимает минут 10 для 20000 игр. Можно оставить как-нибудь потренироваться на 100К или на миллионе, будет точно лучше. Только уже не надо — я разобрался 🙂
Партию можно посмотреть тут:
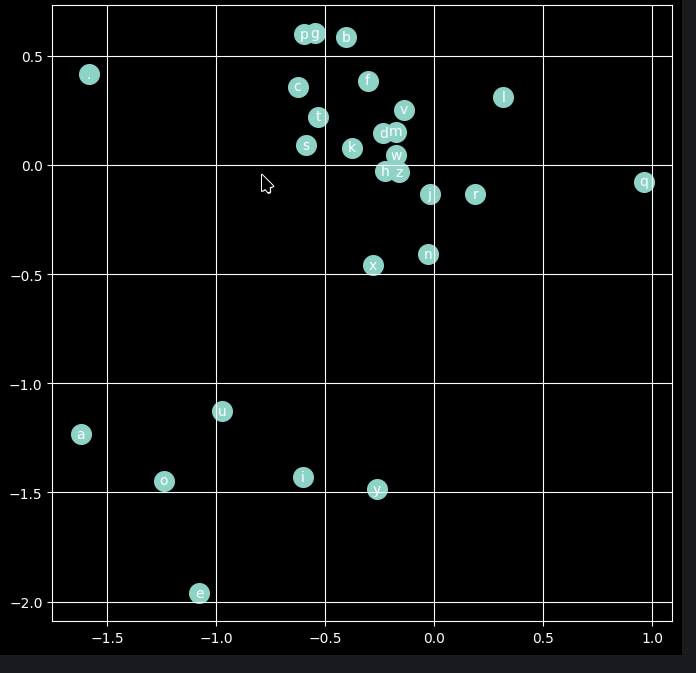
Сейчас экспериментирую с обучением простых нейросетей — главным образом для доведение до автоматизма имеющегося инструментария и некоторые штуки просто создают впечатление магии.
Есть база из 32000 имен. Есть нейросеть, заполеннная случайными числами. Запускаю тренировку, на входе — только этот список имен. Первый слой нейросети — эмбеддинги, и я выставляю число измерений 2, чтобы было легко визуализировать. И после 200000 итераций обучения система четко разделяет гласные от согласных, и почему-то чуть в стороне от других согласных ставит букву «q». Похоже, это потому, что буква ‘q’ почти исключительно предсказывает букву ‘u’ (Queen, Quincy, Quentin).
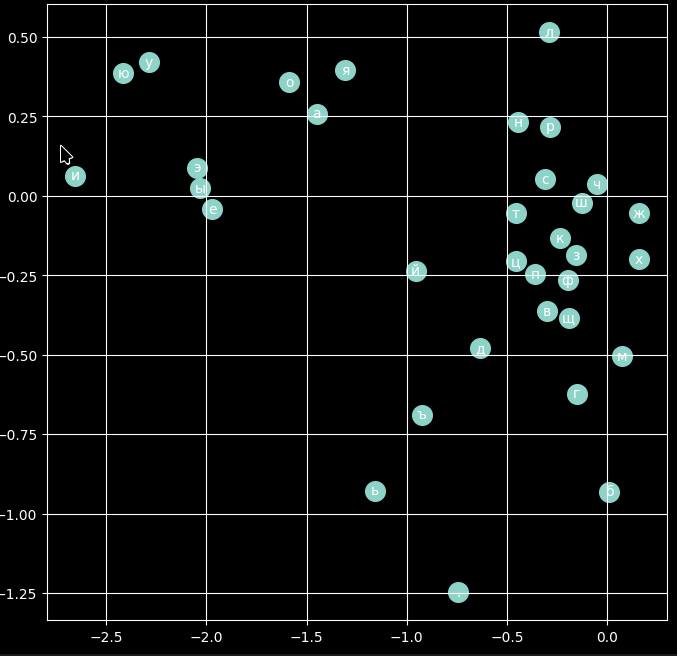
На русских именах тоже очень надежно разделяет гласные и согласные. В русских именах буквы б и л почему-то поодаль от остальных согласных, как и мягкий и твердый знаки (ну с ними понятно).
Интересно, как ж оно работает. Если на нормальном корпусе текстов натренировать, разница будет совсем четкая. Почему отделяются гласные от согласных? Видимо, с точки зрения математики сети, ‘а’ и ‘о’ выполняют одинаковую функцию: они «триггерят» предсказание согласной, следующей за ними, то есть виной всему чередование гласных и согласных. Но черт побери интересно 🙂
Ну и поскольку моделька умеет предсказывать следующие буквы, можно попробовать запустить ее на русском. На модели с эмбеддингами 30 измерений вот такие имена придумывает: бякетта, афсена, еракей, засбат, дарая, гайомахад, раин, ражул, гжаций, ребен, вуреб, дуродира, туружул, регравгава, разсан, габила, авганжа, рахси, халебкохорта, ратхер. Модель — для тех, кто разбирается — такая: вход 6х33 символа (потому что берем до 6 символов контекста), закодированных эмбеддингами в 60, идут на слой в 100 нейронов, а с них обратно на 33 символа. Фигня какая-то, но по крайней мере понятно как это все работает на всех уровнях.
Интересное исследование попалось на глаза, аж 2009 года. Согласно ему, современный человек действительно читает значительно больше, чем в прошлом, хотя формат этого чтения изменился. Согласно ему, на 2008 год, среднестатистический амеканец потребляет около 100000 слов в день (примерно чертверть «Войны и мира») — это приблизительное количество слов, которые прошли через сознание за день (через уши или глаза), рассчитанное на основе хронометража активности. Это на 140% больше, чем в 1980 году.
Таким образом, вопреки мифу о деградации чтения, как минимум в 2008 мы обрабатывали в 2.4 раза больше текстовой информации, чем поколение наших родителей. Причем исследование учитывало только информацию, потребляемую вне работы (дома, в пути, на отдыхе) .
Структура чтения — если в 1960 году 26% слов приходило с бумаги, то к 2008 году эта доля упала до 9%. Однако цифровые носители (интернет, электронная почта, соцсети) не только компенсировали этот спад, но и утроили общее время чтения. Причина — интернет, так как это преимущественно текстовая среда (веб-серфинг, email)
Но интересно, что Интернет обеспечивает 25% потребляемых слов, но лишь 2% байтов (так как видео в интернете в 2008 году было низкого качества). То есть, они там прикинули информационный поток с разных каналов и перевели его в байты 🙂 Радио занимало 19% времени, но генерировало лишь 0,3% байтов (аудио требует мало данных). Голосовая связь (телефон) — это всего 5% слов и ничтожная доля байтов, но это единственный полностью интерактивный канал до эпохи интернета. ТВ оставалось на 2008 год главным источником информации по времени (41% всех часов) и количеству слов (45%), однако по объему данных (байтам) телевидение занимало только второе место (35%), уступая компьютерным играм.
Вот с играми интересно. Главная находка отчета: Игры генерируют (или генерировали в 2008) 55% всех «байтов», потребляемых домохозяйствами. При этом они занимают лишь 8% времени пользователя. Это довольно спорная штука в их отчете.
Те 100500 слов — это оценка реальных слов, которые человек либо прочитал, либо услышал. Это не метафорический «эквивалент», а попытка подсчитать именно вербальную информацию. Они взяли время потребления каждого медиа и умножили на среднюю скорость поступления слов для этого канала. Чтение (книги, газеты, интернет-тексты): 240 слов в минуту. Электронная почта и веб-серфинг — 240 слов в минуту. Телевидение (диалоги в шоу/фильмах): 153 слова в минуту. Радио: 80 слов в минуту (меньше, так как много пауз и музыки). Музыка: 41 слово в минуту (тексты песен).
Ссылка в комментах

У меня долго крутилась реклама AI language tutor, на которую я не реагировал, и система не недельку про меня забыла и вернулась с тьютором заметно постарше.
Но вообще интересно, как скоро видеореклама для нас станет персонифицированной? Ну там в одной и той же рекламе ньюйоркцы будут видеть свой город, чернокожие — чернокожих, утром главная героиня будет пить кофе, а на фоне будет мелькать машина с логотипом родного университета?


«Как обманчива природа!» — сказал ёжик… Интересное у нас встречается, если отступить с тропинки


Как понять, что хозяйка машины- женщина? Вероятно, периодически ещё и не очень трезвая;)

В советское время была хорошая школа анимации, на протяжении многих десятков лет она была ведущая в мире. Если сейчас набрать в youtube «Вовка в тридевятом царстве», то выдаются практически только реставрации 🤮 причем заодно выдаются такие же блевотные реставрации и кучи других мультиков, сделанные в том же духе (векторизацией, черные контуры). Если зайти на википедию, то там будет скриншот именно с реставрации, а не с оригинального мультика 1965 года. Оригинал можно найти например по запросу «вовка в тридевятом царстве мадина газиева», а вот по запросу «вовка в тридевятом царстве союзмультфильм 1965» не показывается он вообще.
Вообще поломали интернет.
P.S. Кстати, двое из ларца, исполняющие желания, и «так сойдет» очень резонирует с ChatGPT сегодняшнего дня 😉
Мучаю свой суперкомпьютер. Иллюстрация того, что GPU — не только для машинного обучения и какой-то сложной математики.
Мой скрипт берет толстый словарь английского языка (Webster) и множит его 30 раз, получается список из 12 млн слов. Далее алгоритм просматривает все 12 млн слов и заменяет все гласные буквы на звездочки через regex. Далее чтобы добавить нагрузки, добавляется колонка «длина слова», и затем берем слова длиннее 10 букв и ищем самые частые (top5).
То есть, на питоне это
df[‘masked’] = df[‘text’].str.replace(r'[aeiou]’, ‘*’, regex=True)
df[‘len’] = df[‘masked’].str.len()
res = df[df[‘len’] > 10][‘masked’].value_counts().head(5)
и вот этот код выполняется сначала через основной процессор, а затем через GPU.
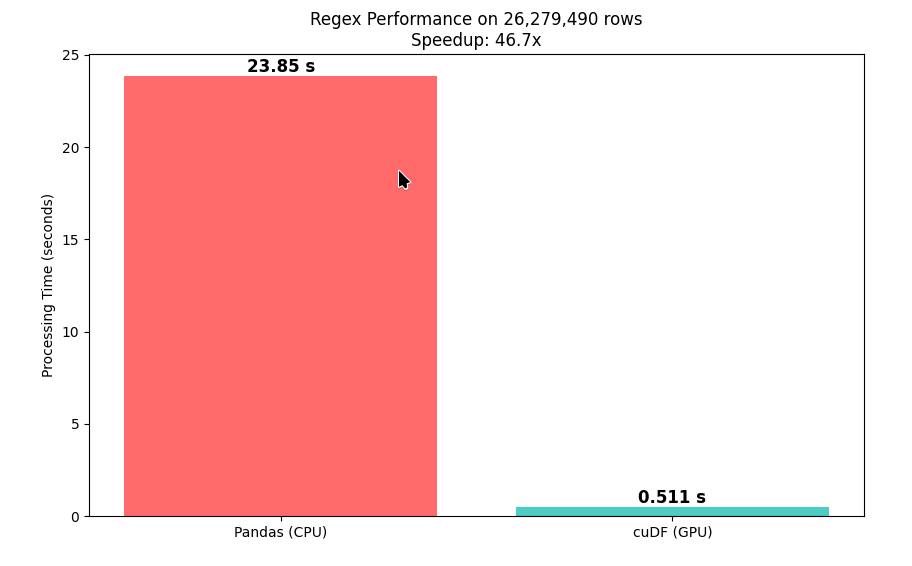
Основной процессор (у меня это топовый Intel i9 285k) выполняет эту задачу за 24 секунды, а Nvidia RTX 5090 — за 0.51 секунд. То есть, разница в 46 раз!
[Pandas CPU] Top Patterns:
masked
s*r w. sc*tt. 23280
s*r t. br*wn*. 23220
j*r. t*yl*r. 16140
bl*ckst*n*. 10860
b***. & fl. 10830
Name: count, dtype: int64
[Pandas CPU] Computation Time: 23.5596 sec.
Transferring data to GPU…
Transfer complete in 1.16s
— Running Benchmark: cuDF GPU —
[cuDF GPU] Top Patterns:
masked
s*r w. sc*tt. 23280
s*r t. br*wn*. 23220
j*r. t*yl*r. 16140
bl*ckst*n*. 10860
b***. & fl. 10830
Name: count, dtype: int64
[cuDF GPU] Computation Time: 0.5108 sec.
TOTAL SPEEDUP: 46.12x
Просто на поржать. Я спросил у Gemini как можно выгрузить всю конфигурацию AWS для локального анализа и тот порекомендовал использовать команду aws-nuke для безвозратного удаления вообще всего, но если добавить ключик dry-run, то получите конфигурацию.. и вот кто-то же следует таким рекомендациям 🙂 и мы потом удивляемся


