Сейчас экспериментирую с обучением простых нейросетей — главным образом для доведение до автоматизма имеющегося инструментария и некоторые штуки просто создают впечатление магии.
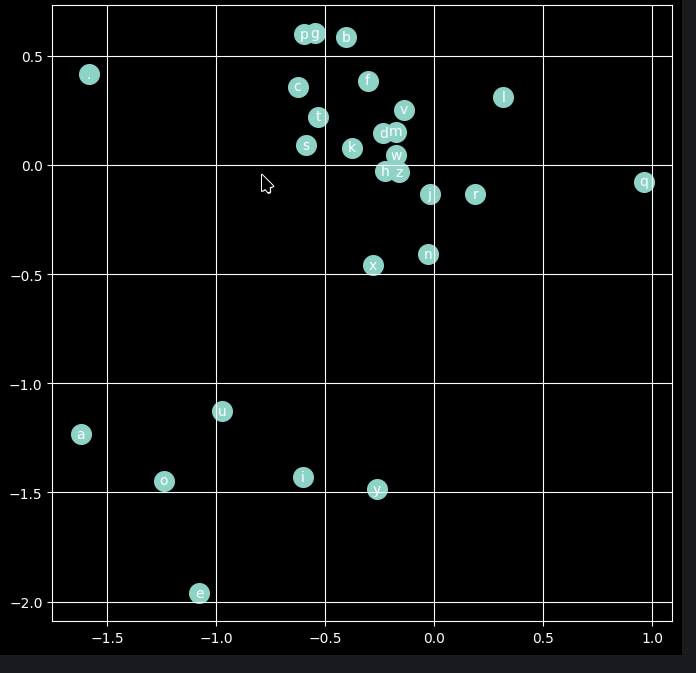
Есть база из 32000 имен. Есть нейросеть, заполеннная случайными числами. Запускаю тренировку, на входе — только этот список имен. Первый слой нейросети — эмбеддинги, и я выставляю число измерений 2, чтобы было легко визуализировать. И после 200000 итераций обучения система четко разделяет гласные от согласных, и почему-то чуть в стороне от других согласных ставит букву «q». Похоже, это потому, что буква ‘q’ почти исключительно предсказывает букву ‘u’ (Queen, Quincy, Quentin).
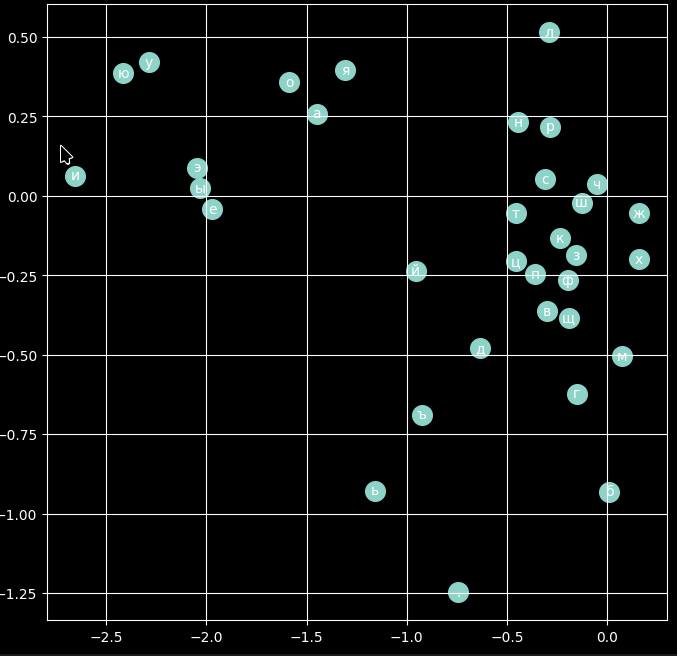
На русских именах тоже очень надежно разделяет гласные и согласные. В русских именах буквы б и л почему-то поодаль от остальных согласных, как и мягкий и твердый знаки (ну с ними понятно).
Интересно, как ж оно работает. Если на нормальном корпусе текстов натренировать, разница будет совсем четкая. Почему отделяются гласные от согласных? Видимо, с точки зрения математики сети, ‘а’ и ‘о’ выполняют одинаковую функцию: они «триггерят» предсказание согласной, следующей за ними, то есть виной всему чередование гласных и согласных. Но черт побери интересно 🙂
Ну и поскольку моделька умеет предсказывать следующие буквы, можно попробовать запустить ее на русском. На модели с эмбеддингами 30 измерений вот такие имена придумывает: бякетта, афсена, еракей, засбат, дарая, гайомахад, раин, ражул, гжаций, ребен, вуреб, дуродира, туружул, регравгава, разсан, габила, авганжа, рахси, халебкохорта, ратхер. Модель — для тех, кто разбирается — такая: вход 6х33 символа (потому что берем до 6 символов контекста), закодированных эмбеддингами в 60, идут на слой в 100 нейронов, а с них обратно на 33 символа. Фигня какая-то, но по крайней мере понятно как это все работает на всех уровнях.