Мучаю свой суперкомпьютер. Иллюстрация того, что GPU — не только для машинного обучения и какой-то сложной математики.
Мой скрипт берет толстый словарь английского языка (Webster) и множит его 30 раз, получается список из 12 млн слов. Далее алгоритм просматривает все 12 млн слов и заменяет все гласные буквы на звездочки через regex. Далее чтобы добавить нагрузки, добавляется колонка «длина слова», и затем берем слова длиннее 10 букв и ищем самые частые (top5).
То есть, на питоне это
df[‘masked’] = df[‘text’].str.replace(r'[aeiou]’, ‘*’, regex=True)
df[‘len’] = df[‘masked’].str.len()
res = df[df[‘len’] > 10][‘masked’].value_counts().head(5)
и вот этот код выполняется сначала через основной процессор, а затем через GPU.
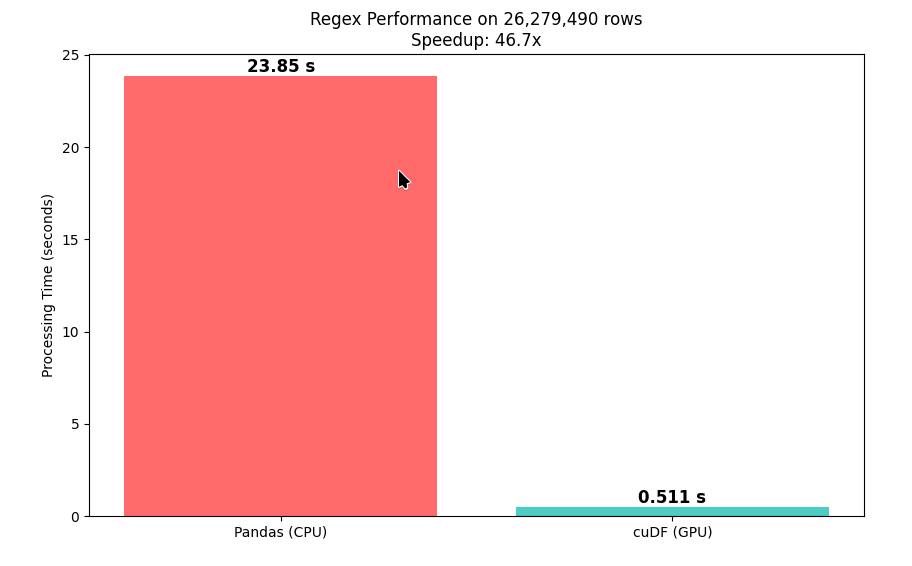
Основной процессор (у меня это топовый Intel i9 285k) выполняет эту задачу за 24 секунды, а Nvidia RTX 5090 — за 0.51 секунд. То есть, разница в 46 раз!
[Pandas CPU] Top Patterns:
masked
s*r w. sc*tt. 23280
s*r t. br*wn*. 23220
j*r. t*yl*r. 16140
bl*ckst*n*. 10860
b***. & fl. 10830
Name: count, dtype: int64
[Pandas CPU] Computation Time: 23.5596 sec.
Transferring data to GPU…
Transfer complete in 1.16s
— Running Benchmark: cuDF GPU —
[cuDF GPU] Top Patterns:
masked
s*r w. sc*tt. 23280
s*r t. br*wn*. 23220
j*r. t*yl*r. 16140
bl*ckst*n*. 10860
b***. & fl. 10830
Name: count, dtype: int64
[cuDF GPU] Computation Time: 0.5108 sec.
TOTAL SPEEDUP: 46.12x