Никогда бы не подумал, что мне будет в кайф работать на одном месте целое десятилетие. В чем секрет? В EPAM я не застаиваюсь: проекты сменяют друг друга, не давая заскучать.
Сейчас я на проекте в компании-гиганте: более 100 тысяч сотрудников и выручка за 30 миллиардов долларов. До этого был автопром — махина со штатом в 175 тысяч человек и оборотом в 150 миллиардов. Где-то around был контракт с компанией на 80 тысяч сотрудников и 35 миллиардов дохода. Настоящие масштабы и по-настоящему серьезные вызовы. А еще раньше были косметические бренды, биотех и «нефтянка». В общей сложности — больше 20 проектов самого разного калибра. При том, что у меня была более чем 100% загрузка каждый день. И еще у меня в этом году, кажется, было больше отпуска, чем обычно, но все равно меньше, чем я мог бы взять. Съездил в Коста-Рику, Мексику, Сиеттл, Анталию.
Суть в том, что на каждом новом месте ты учишься чему-то, иногда с нуля. И это чертовски круто. Это дает гораздо больше энергии, чем если бы я «врастал корнями» в любую из этих корпораций на все 10 лет. Возможно, с чисто финансовой точки зрения люди, осевшие в одном месте в этих компаниях, заработали больше меня, но деньги — не приоритет, если ради них приходится жертвовать интересом и азартом. Прожигать жизнь на работе, от которой ты смертельно устал — сомнительное удовольствие.
Прошлый год в EPAM выдался максимально интенсивным, и я искренне надеюсь, что 2026-й не будет сбавлять обороты.
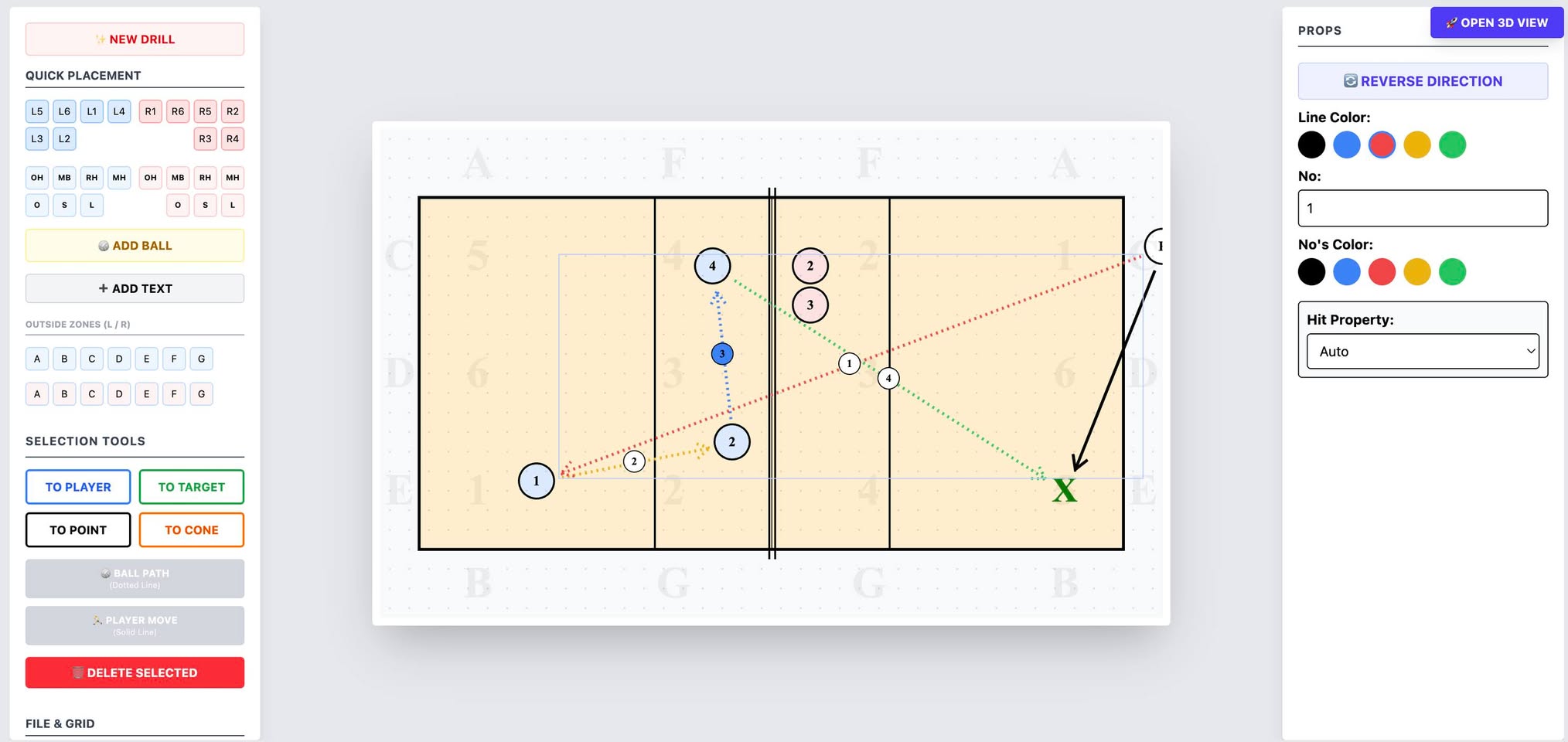
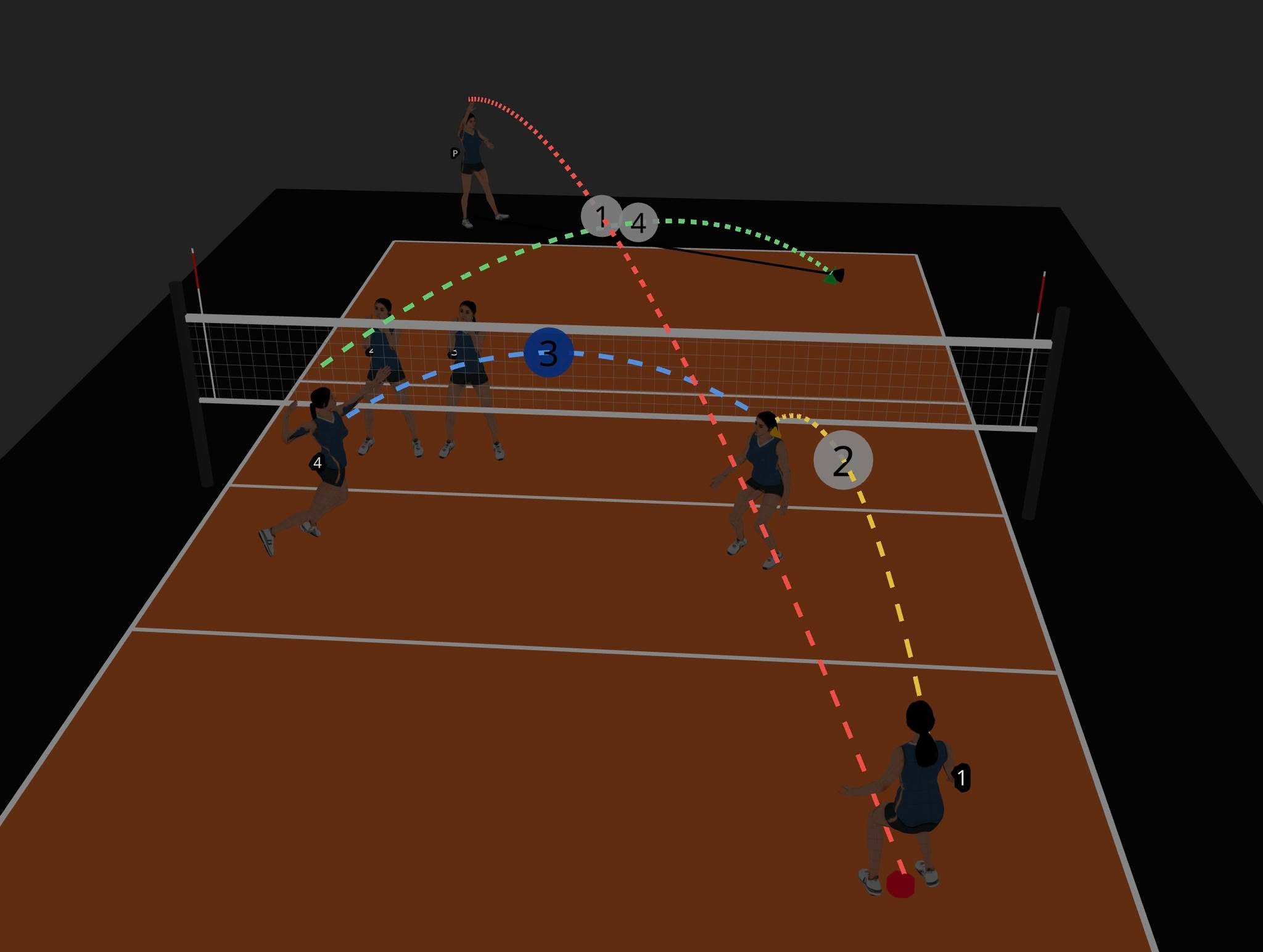
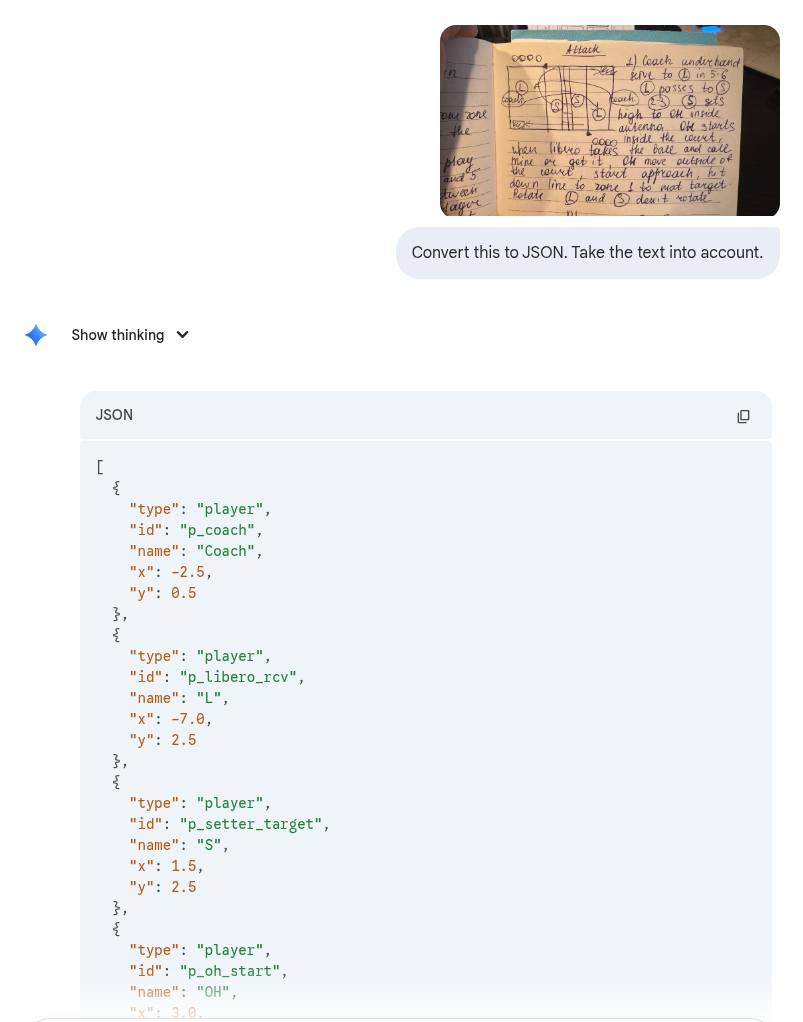
Чем я занимался в самолете в/из отпуска и иногда между и после: 3D-визуализация и редактор волейбольных схем для Нади (она — тренер). Этот корт на приложенном изображении свободно вращается, на нем могут быть поставлены игроки, и указан путь мяча и игрока — все в 3D.
Траектория мяча рассчитывается так, чтобы мяч не пересекал сетку при движении из A в B (формула Безье). Игроки могут принимать несколько поз — прямо сейчас есть наспех сделанные позы serve, attack, block, pass/receive. Кстати, из интересного в коде: пришлось прописать немного «волейбольных мозгов». Система сама считает траекторию мяча через кривые Безье так, чтобы он всегда проходил над сеткой. Причем высота вылета зависит от типа действия: для атаки мяч «вылетает» с более высокой точки, чем а для паса. Еще добавил авто-разворот: 3D-моделька сама поворачивается лицом туда, куда она по схеме должна пасовать или бежать.
Дольше и сложнее всего было сделать 3D-модель волейболистки. Для генерации реалистичной волейболистки я использовал сервис tripo3D. Он мне выдал модель в нейтральной позе (бесплатно выдал). Теоретически дальше с помощью Blender и плагина Rigify можно прицепить к ней armature и двигать руки-ноги, за которыми будет пересчитываться модель.
Однако в реальности такой подход не срабатывает: сгенерированная ИИ модель содержит большое количество геометрических ошибок, которые прощает рендер, но не прощает Rigify. Их можно условно разделить на два вида — неверные нормали полигонов и проблемы с немногообразной (non-manifold) геометрией, которые исправлять значительно сложнее. Внутри корпуса могут «плавать» невидимые кластеры полигонов или пересекающиеся поверхности. Когда Rigify пытается рассчитать веса (какая кость на какую часть кожи влияет), этот внутренний шум сбивает алгоритм с толку, и в итоге веса распределяются хаотично (например, движение руки может начать тянуть за собой сетку на животе). Плюс модель немного не симметрична.
Non-manifold — это ошибка геометрии, при которой топология объекта перестаёт быть корректной с точки зрения трёхмерного тела: рёбра могут принадлежать более чем двум полигонам, полигоны могут соприкасаться только вершинами или рёбрами без общего объёма, внутри модели появляются «висящие» поверхности или нулевая толщина. Такая геометрия формально не описывает замкнутый объём, из-за чего возникают проблемы с риггингом и деформациями. Кроме этого, нужно упростить модель, потому что для рендера в реальном времени в браузере миллионы полигонов не нужны.
Я исправлял это с помощью MashLab, попутно дорабатывая «напильником» (руками). В итоге получается модель, чуть-чуть отличающающаяся от исходной почти везде. На исходной же модели нацеплена «кожа» в виде текстуры — лицо, майка, шорты должны быть раскрашены. Как все это перенести на упрощенную модель? Для этого есть специальная операция в Blender, называется Baking. Там тоже шаманство. В итоге неидеально перенеслось, но идеально пока и не нужно.
Дальше привязываем арматуру к «суставам», и через часа три разбирательств, почему все работает не так, как должно, оно все-таки заработало. Я сделал четыре позы, и теперь каждому кружочку (игроку) можно указывать в какой позе он стоит.
Еще нужно будет сделать динамическую смену раскраски формы — это не должно быть сложно. Есть еще идея переносить позу с фотографии — это посложнее, но в целом реалистично. С помощью MediaPipe/AlphaPose можно детектировать ключевые точки в 2D, затем с помощью каких-нибудь моделей типа HMR/HybrIK можно «поднять» плоские координаты в 3D-пространство, выдавая относительные углы поворота суставов. Полученные данные можно попробовать спроецировать на Rigify-скелет. Поскольку пропорции сгенерированной волейболистки и человека на фото могут не совпадать, как раз и используется Inverse Kinematics (IK). Это довольно сложная часть, но в целом она уже не очень обязательная — просто интересно разобраться и сделать что-то работающее.
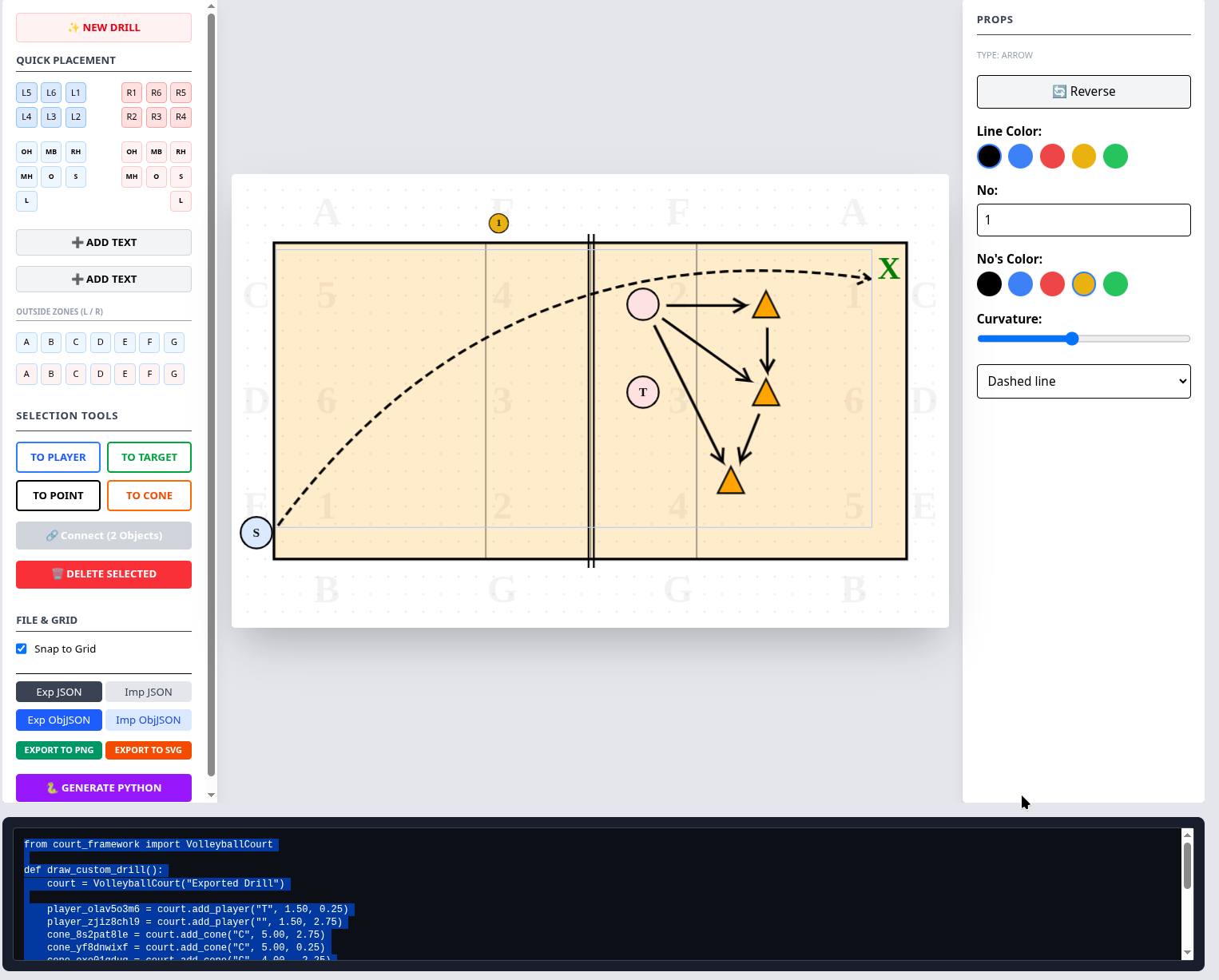
Завтра вылет в Коста-Рику, а я тут для Нади делаю (или сделал) редактор волейбольных схем. Она как тренер готовится к занятиям, и оставляет после себя сотни страниц текста со схемами на каждой странице. Текст рукописный, и теоретически его просто перевести в электронную форму, а вот схемы в качественную векторную форму переводить замучаешься, их очень много. И я решил сделать софт вчера. И вот сегодня уже первая ласточка, можно пользоваться. Это редактор схем, немного похожий отдаленно на редактор диаграмм. Заодно поразбирался с фреймворком fabric.
Процесс выглядит так. Gemini/ChatGPT через API могут конвертировать рукописные схемы в структуру, которая понимает моя программа. Далее открываем этот файл в программе, и немного подправляем если надо. А может и вообще рисуем заново — для простых схем это даже проще. Там есть четыре типа объекта — игрок, конус, мишень, текст. Любые можно соединять друг с другом стрелками, простыми или пунктирными, подписанными текстом или номером или нет, выбранного цвета, прямыми или по дуге. Если зацепить мышкой за объект, то потянутся за ним все стрелки.
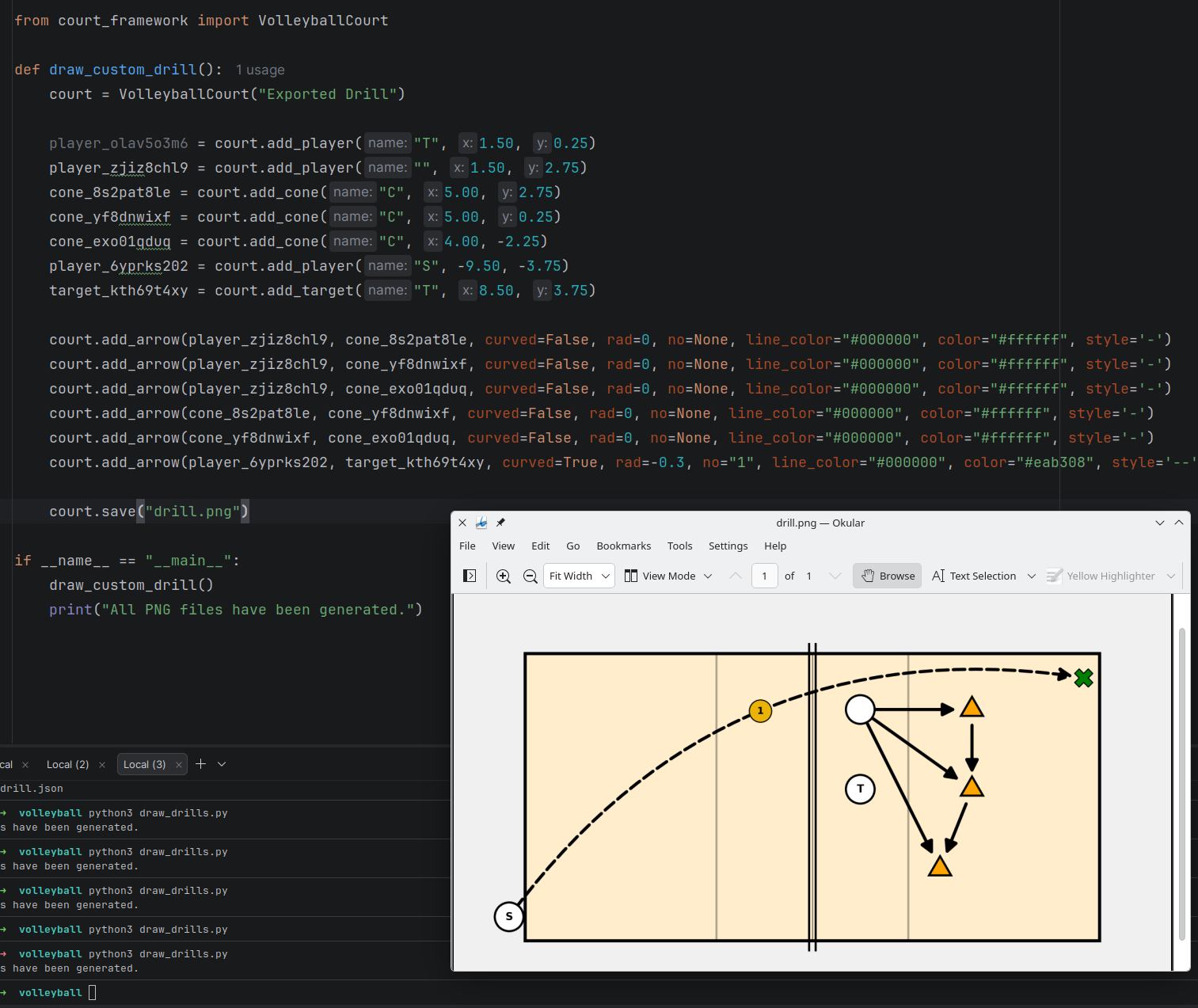
Результат можно записать в файл. Можно открыть шаблон и на его основе сделать что-то новое. Можно сгенерировать скрипт на питоне — вчера это было еще актуально, сегодня в целом не надо уже — SVG/PNG высокого разрешения делаются сразу из этого приложения (вчера делались отдельно с питона).
Понятно, почему сразу не попросить Gemini/ChatGPT сделать что-то для готовых векторных редакторов: во-первых, они слишком гибкие и ограничить фантазию LLM довольно сложно. В итоге получаются разностильные, никуда не годящиеся картинки. Тут же есть фреймворк из четырех объектов и все, LLM о нем знает и генерит только то, что им можно отобразить. Во-вторых, этот фреймворк оперирует объектами, а не элементарными векторными примитивами.
В целом, это первый шаг к моей идее про систему автоматического диаграммрования по описанию. Когда даешь LLM описание диаграммы, а она консистентно генерит то, что написано в описании, и если ты что-то подправил, то при перегенерации это изменение будет учитываться.
Все мы с этим сталкивались — «Главная Excel-Таблица, Управляющая Бизнесом». Та самая, которую B2B-компании используют, чтобы считать котировки на миллионы долларов. В ней 12 вкладок, 1000+ вложенных формул и ноль документации. Десять лет туда лепили «быстрые фиксы» и прятали константы. Это уже не файл, а живой организм, который уже никто до конца не понимает кроме того чела, уволившегося годы назад. Вот такой я был озадачен. Более того, там еще была неопределенность нужна ли вообще половина формул, или это рудименты прошлого.
Мне поручили перенести эту логику в код, чтобы все считалось софтом. Excel-файл как бы все имел что надо, но по факту — это был сложнораспутываемый черный ящик. 1069 формул.
Челлендж был в том, как перевести тысячу взаимозависимых формул в чистый код и не потерять ни одного пограничного случая (edge case).
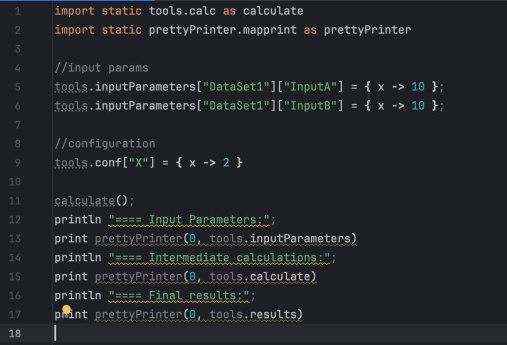
В итоге вот что я сделал.
Вместо того чтобы переписывать всё с нуля одним махом с неопределенными перспективыми наплодить багов, я использовал стратегию ленивых вычислений и моков.
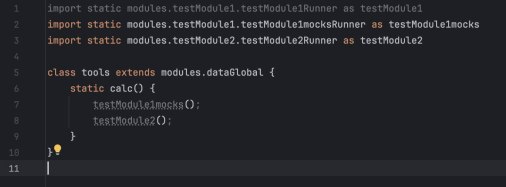
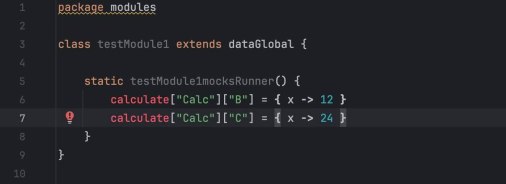
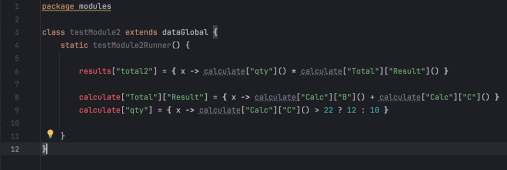
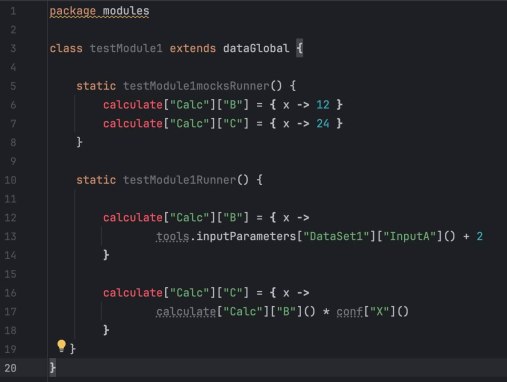
Я построил структуру на Groovy, которая имитировала поведение Экселя. Каждое вычисление (из ячейки) я определил как функцию, которая выполняется только тогда, когда её вызывают. А функциями был многомерный dictionary.
Я пошел с конца графа вычислений: от результатов к входным данным. Если формула зависела от чего-то, что я еще не написал, я «мокал» это в коде, просто подставляя значение из Excel-листа.
Кусок за куском я заменял эти моки на реальную логику. Сравнивая выхлоп моего кода с экселькой на каждом шаге, я точно видел, где моя логика расходится.
Другими словами, движение шло от результата к исходным данным. На каждом шаге было ясно, какие моки надо превратить в код, и можно было сравнить версию +1 с версией -1 — результат должен был совпадать. Как только все моки заменились на вызовы — задача была готова.
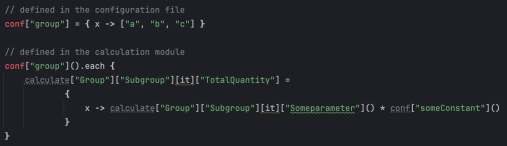
Настоящим «секретным ингредиентом» стала динамическая природа Groovy для создания многомерной карты функций. Вместо статических переменных я использовал глубоко вложенную структуру, где каждый «лист» был замыканием (closure). Это позволило обращаться к любой части таблицы — будь то входной параметр, константа конфига или сложный промежуточный результат — через простой, унифицированный синтаксис, причем некоторые компоненты были динамическими.
x -> calculate[«Group»][«Subgroup»][it][«Someparameter»]() * conf[«someConstant»]()
}
}
Используя динамические ключи и замыкания, я мог итерироваться по группам продуктов или наборам данных. Поскольку это были динамические функции, а не сохраненные значения, вся система работала как живой граф зависимостей.
Тестировать можно было прямо сразу после начала переноса формул. Прелесть была в том, что ты вроде как как бы к ячейке обращаешься через синтаксис типа calculate[«Totals»][«A»](), а на самом деле запускаешь целое дерево вычислений в этот момент. И это дико удобно в отладке.
Через две недели «Черный ящик» превратился в прозрачную, модульную библиотеку с понятной логикой, которая выдавала ровно тот же результат, что и оригинальная таблица.
P.S. Ну и конечно, все данные на всех скриншотах тщательно обфусцированы, а точнее сказать, написаны с нуля для этого текста.
Ух какую я прикольную задачку только что решил. Хрен только объяснишь. Ну я попробую.
Короче, у клиента есть 10 сайтов с поиском. Они все используют один индекс, но кидают разные запросы к нему. К тому, что вводит пользователь, прибавляется очень длинный и сложный query, который генерирует модуль на сайткоре. Он содержит айдишники шаблонов и страниц, которые нужно включать или исключать. В итоге понять, что там происходит, вообще невозможно. Там может быть десять открывающих скобок и где-то рандомно закрывающие, но с Coveo работало. Реформаттинг помогал, но не сильно.
И у каждого сайта такое свое. При этом там фигурируют периодически одни и те же айдишники. Я сначала пытался в этом вручную разобраться, но это был кошмар. Ни фига не помогает. Там же еще вложенные условия. Например, «исключить этот шаблон» не глобально, а только если вон то поле равно единице.
В итоге вот что я сделал:
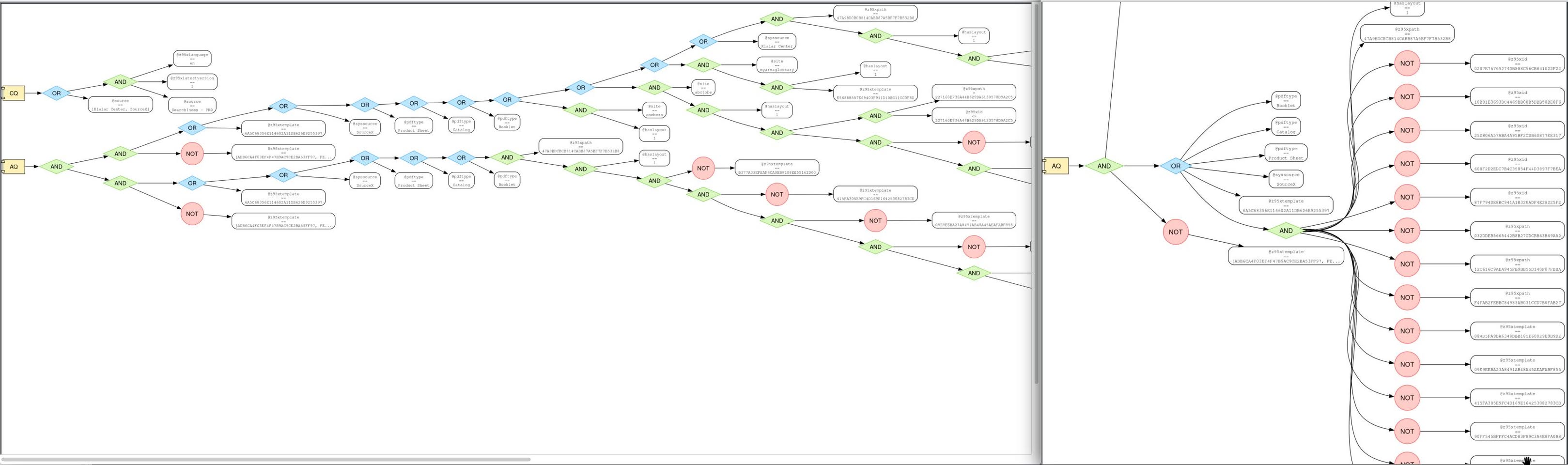
Написал скрипт, который разбирает эту текстовую «кашу» в абстрактное синтаксическое дерево (AST). Это позволило превратить нечитаемую строку в структурированный JSON-объект, где четко видно: вот тут AND, тут OR, а тут — конкретное условие.
Дальше я превратил эти условия в формулы булевой алгебры. С помощью библиотеки SymPy я «скормил» эти формулы алгоритмам упрощения. Математика сама выкинула дубликаты, схлопнула лишние вложенности и убрала условия, которые логически поглощаются другими. В результате «деревья» стали плоскими и понятными.
В аттаче — оригинальное дерево и упрощенное.
Чтобы быть уверенным, что я ничего не сломал при упрощении, я написал генератор тестов. Он берет упрощенную логику, собирает её обратно в рабочий curl и проверяет, совпадает ли количество найденных документов (totalCount) с оригинальным запросом. Цифры сошлись — значит, логика сохранена на 100%.
Имея на руках упрощенные и стандартизированные структуры для каждого сайта, я построил матрицу сравнения. Скрипт проанализировал их и выделил Common Core — условия, которые гарантированно требуются (или запрещены) на всех сайтах без исключения, и Specifics — уникальные «хвосты», которые отличают один сайт от другого.
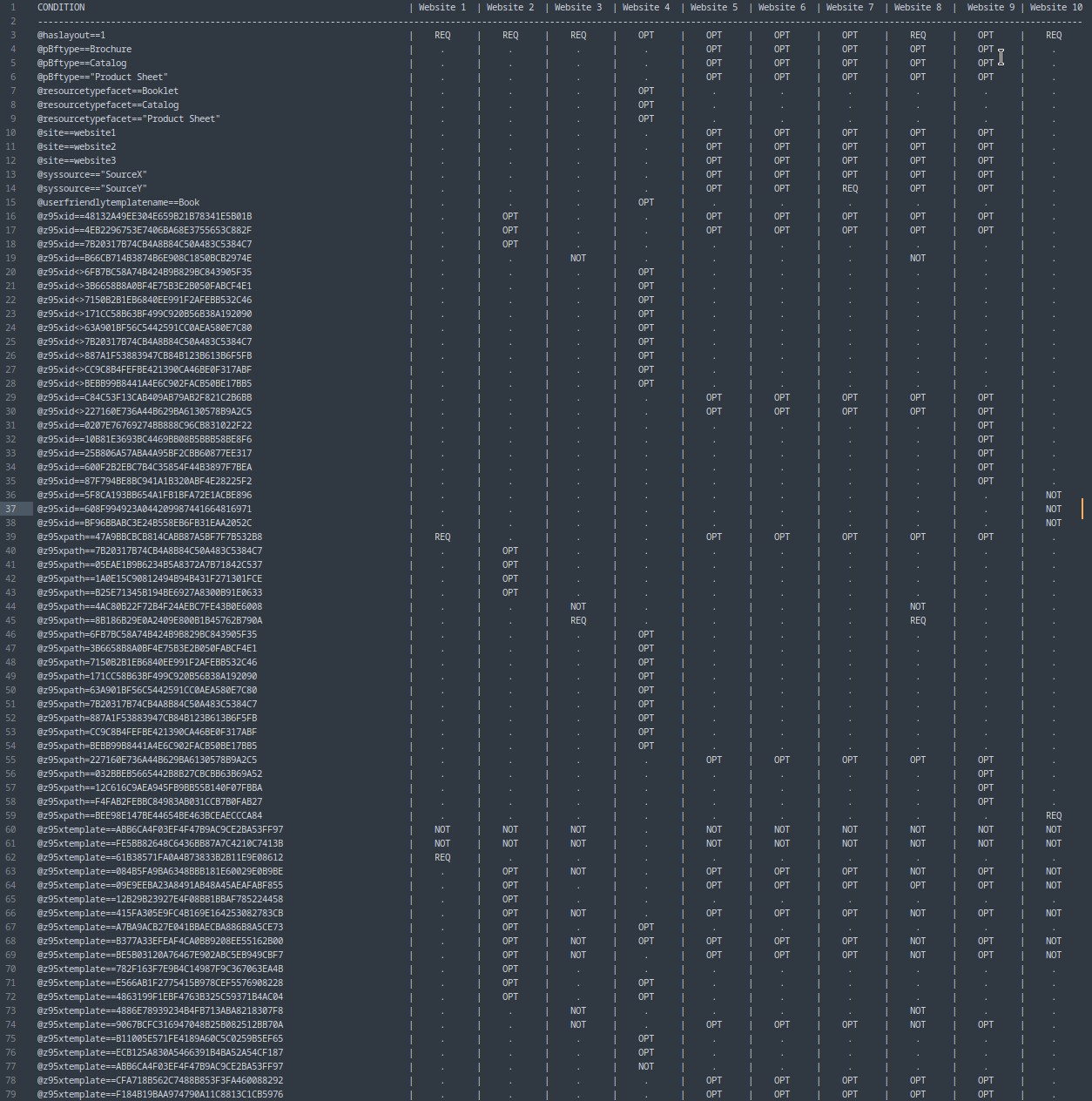
На приложенном скриншоте: REQ означает, что условие гарантированно выполняется для любого документа, который пройдет через этот запрос. NOT — гарантированно не выполняется. OPT — условие присутствует в запросе, но оно не является строгим само по себе. Оно работает только в связке с чем-то еще. «.» — условие вообще не упоминается в запросе.
Для 3 сайтов моментально отвечает, для 10 работает минут 30.
Ну и конечно, все данные на всех скриншотах тщательно обфусцированы.
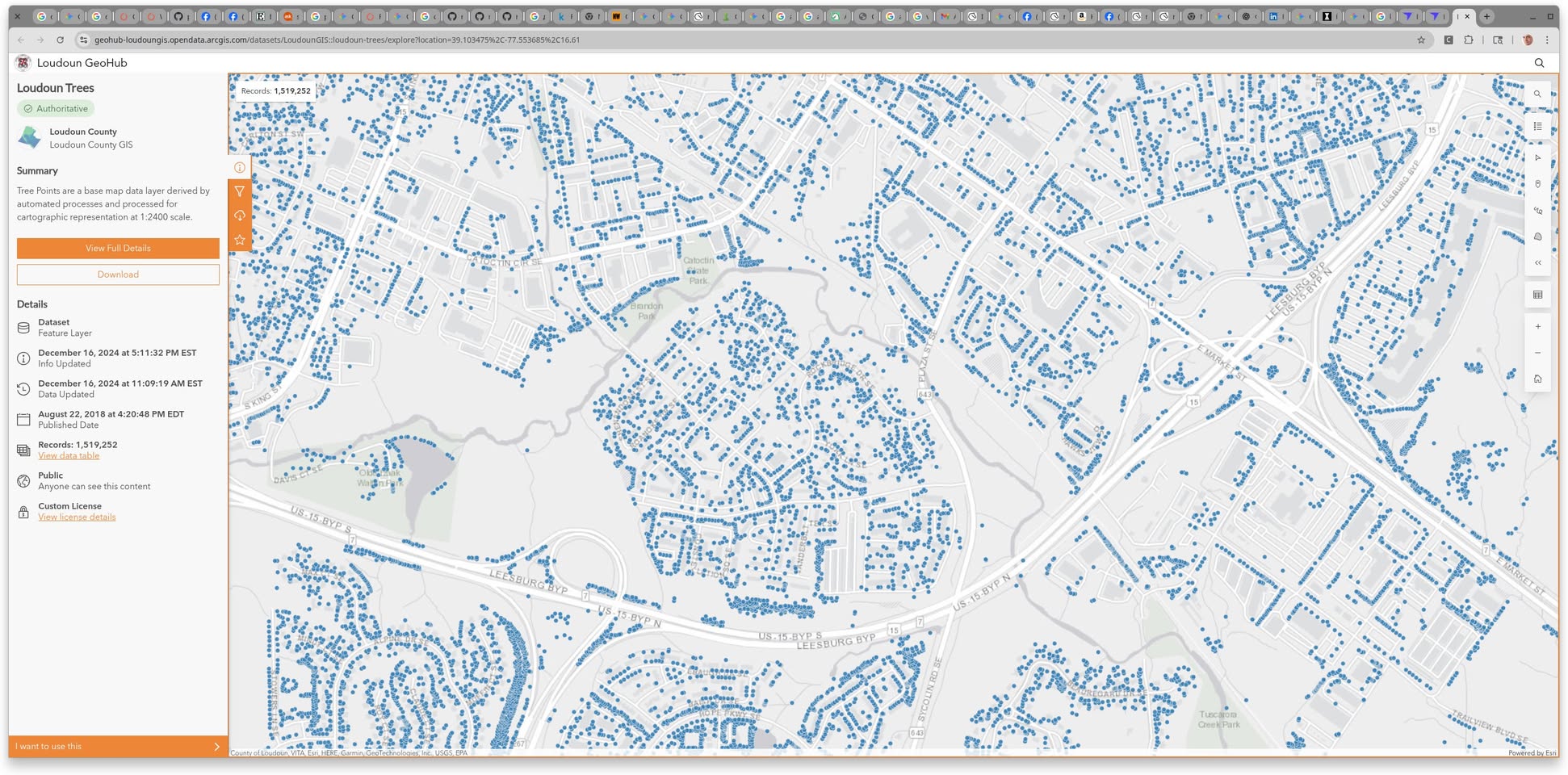
Смотрю какие у нас в каунти есть открытые данные для поиграться с анализом данных на выходных, и обнаружил, что есть, например, открытая база данных всех 1.5 млн деревьев графства. На скриншоте очень маленькая часть вокруг моего дома
Пока разбирался с нейросетями, решил придумать себе игровую задачку. А что если я найду где-то готовые партии, и обучу нейросетку предсказывать ход по ситуации на доске. Сказано — сделано. Конечно, код быстрее генерить с помощью LLM, но задание подробное писал сам и архитектуру придумывал сам. Через 40 минут (!) от идеи до результата: у меня уже было работающее решение, которое ну по крайней мере в первой половине партии не очень сильно косячит.
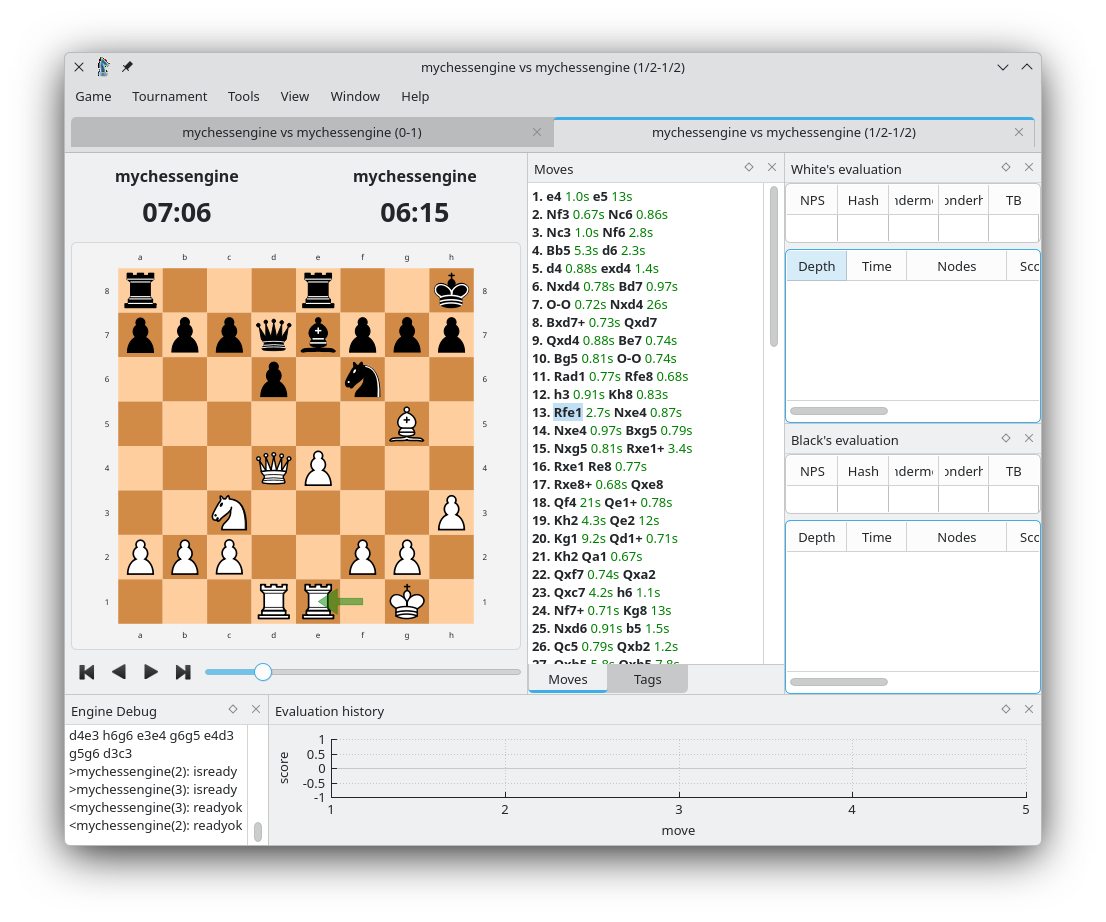
На скриншоте CuteChess — он работает с любым шахматным движком, и в моем случае это простой скрипт на питоне. Скрипт берет ситуацию на доске и скармливает ее модели. Выбирает топ 5 ходов, и только эти топ 5 просматривает вглубь на несколько ходов вперед и оценивает позицию. То есть, нейросеть у меня предлагает возможные ходы на основе анализа 20000 партий (534453 позиций). Из того, что получается, выбирается лучшее. Там используется для этого алгоритм minimax, если это кому-то что-то говорит (мне не очень говорило, поэтому Gemini тут мне помог)
Как тренируется модель. На сайте lichess можно скачать партии, там сотни гигабайт. Я взял файлик с 800000 сыгранными партиями за 2014 год. Из этих 800000 я отбираю 20000, а именно скриптом ищу партии, где результат не ничья (1-0 или 0-1). Далее считаю разницу (Рейтинг_Победителя минус Рейтинг_Проигравшего). Это не самая лучшая метрика, но лучше, чем ничего. Чем больше эта разница, тем «увереннее» должен быть выигрыш (сильный наказывает слабого). Итого получается 20000 таких партий.
«Игнорирование ходов слабого» (чтобы модель не учить плохому) реализуется на этапе тренировки модели. Фактически, логика такая: «Если сейчас ход белых, и белые выиграли эту партию — учимся. Если сейчас ход черных, и черные проиграли — пропускаем и не учим сеть этому ходу» .
Нейросеть тренируется батчами по 128 позиций за раз. Сеть получает на вход позицию на доске и выдает 4096 — оценку вероятности для каждого возможного хода.
Отбор партий занимает минут 5. Тренировка модели у меня на компе занимает минут 10 для 20000 игр. Можно оставить как-нибудь потренироваться на 100К или на миллионе, будет точно лучше. Только уже не надо — я разобрался 🙂
Сейчас экспериментирую с обучением простых нейросетей — главным образом для доведение до автоматизма имеющегося инструментария и некоторые штуки просто создают впечатление магии.
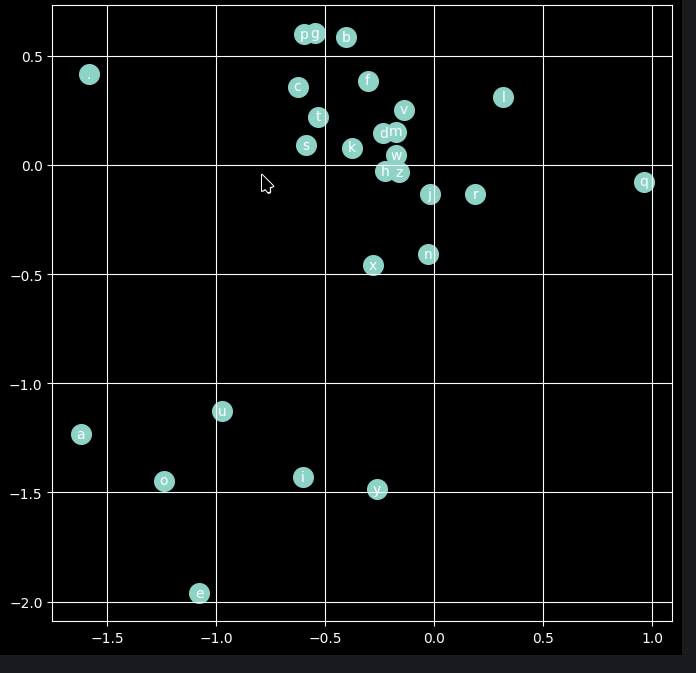
Есть база из 32000 имен. Есть нейросеть, заполеннная случайными числами. Запускаю тренировку, на входе — только этот список имен. Первый слой нейросети — эмбеддинги, и я выставляю число измерений 2, чтобы было легко визуализировать. И после 200000 итераций обучения система четко разделяет гласные от согласных, и почему-то чуть в стороне от других согласных ставит букву «q». Похоже, это потому, что буква ‘q’ почти исключительно предсказывает букву ‘u’ (Queen, Quincy, Quentin).
На русских именах тоже очень надежно разделяет гласные и согласные. В русских именах буквы б и л почему-то поодаль от остальных согласных, как и мягкий и твердый знаки (ну с ними понятно).
Интересно, как ж оно работает. Если на нормальном корпусе текстов натренировать, разница будет совсем четкая. Почему отделяются гласные от согласных? Видимо, с точки зрения математики сети, ‘а’ и ‘о’ выполняют одинаковую функцию: они «триггерят» предсказание согласной, следующей за ними, то есть виной всему чередование гласных и согласных. Но черт побери интересно 🙂
Ну и поскольку моделька умеет предсказывать следующие буквы, можно попробовать запустить ее на русском. На модели с эмбеддингами 30 измерений вот такие имена придумывает: бякетта, афсена, еракей, засбат, дарая, гайомахад, раин, ражул, гжаций, ребен, вуреб, дуродира, туружул, регравгава, разсан, габила, авганжа, рахси, халебкохорта, ратхер. Модель — для тех, кто разбирается — такая: вход 6х33 символа (потому что берем до 6 символов контекста), закодированных эмбеддингами в 60, идут на слой в 100 нейронов, а с них обратно на 33 символа. Фигня какая-то, но по крайней мере понятно как это все работает на всех уровнях.
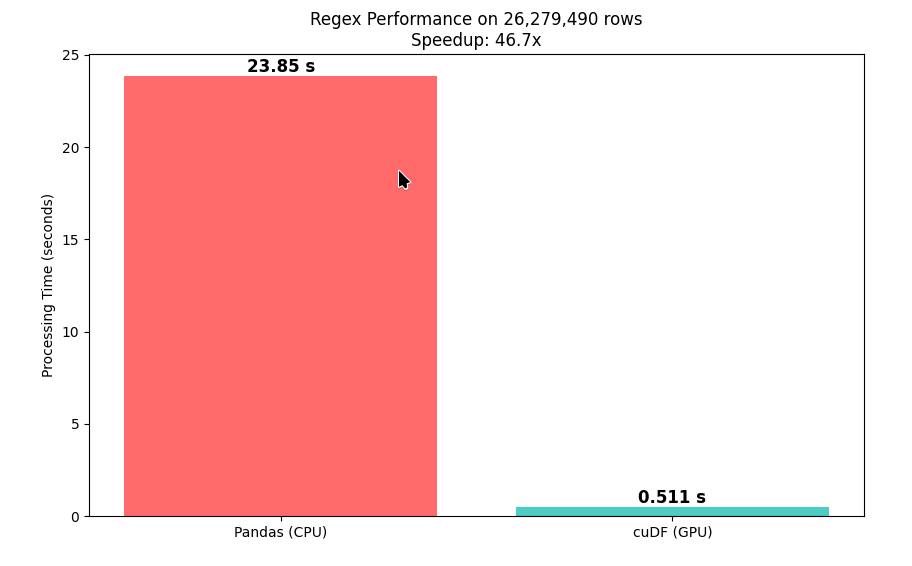
Мучаю свой суперкомпьютер. Иллюстрация того, что GPU — не только для машинного обучения и какой-то сложной математики.
Мой скрипт берет толстый словарь английского языка (Webster) и множит его 30 раз, получается список из 12 млн слов. Далее алгоритм просматривает все 12 млн слов и заменяет все гласные буквы на звездочки через regex. Далее чтобы добавить нагрузки, добавляется колонка «длина слова», и затем берем слова длиннее 10 букв и ищем самые частые (top5).
res = df[df[‘len’] > 10][‘masked’].value_counts().head(5)
и вот этот код выполняется сначала через основной процессор, а затем через GPU.
Основной процессор (у меня это топовый Intel i9 285k) выполняет эту задачу за 24 секунды, а Nvidia RTX 5090 — за 0.51 секунд. То есть, разница в 46 раз!