Читаю всякие инженерные блоги про автопилот Tesla (FSD) — просто потому, что я последние полтора месяца почти постоянно езжу как на такси — указываешь место назначения и дальше практически никогда не нужно вмешиваться, машина едет из точки А в точку Б полностью самостоятельно. Это конечно будущее.
Такие системы есть не только у Tesla. Например, она есть у Мерседеса (Drive Pilot). У остальных только в лучшем случае в пробках помогает. Хотя Tesla кажется единственная, которая работает на всех дорогах.
Так вот, возвращаясь к инженерным интересностям. У Теслы есть производство AI-моделей на своей «ферме», которая называется Dojo — это экзафлопный суперкомпьютер на чипах Tesla. Туда скармливаются видео с камер, и он тренирует модели, которые дальше отправляются для автономной работы на весь парк машин Tesla.
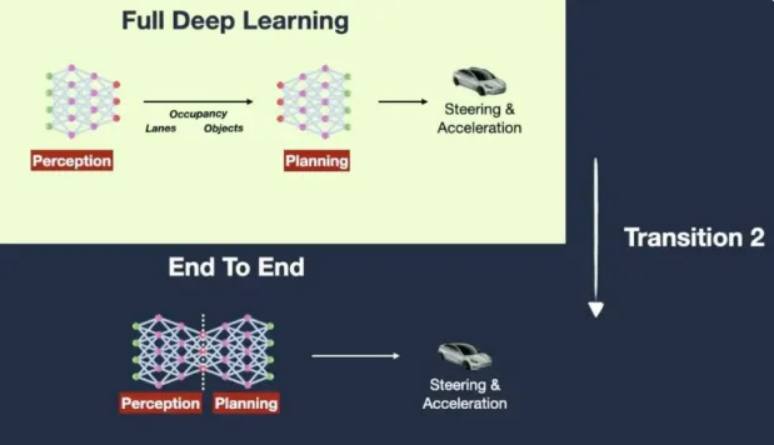
Архитектура FSD состоит из порядка 48 специализированных нейросетей, обученных на Dojo, которые вместе формируют около 1000 разных тензоров-прогнозов. Tesla постепенно переходит с модульных сетей (распознавание объектов + планирование) к end‑to‑end-тренингу — прямое преобразование видеокадров в траекторию/момент рулевого управления. Это похоже на «черный ящик» — нейросеть учится прямо по поведению человека, без ручной установки регуляторов; очень крутое инженерное решение, но, предполагаю, сложное в отладке.
Кстати, заявляется, что Тесла пересела с С++ на питон. И что этот переход на end-to-end training сделал ненужным 300,000 строк кода на С++, где были учтены всякие корнер-кейсы и правила разруливания различных ситуаций — теперь это на уровне модели.
Tesla отказалась от радара и ультразвука, перейдя к полностью камерным решениям (Vision Only) с «Hardware 4» (HW4, FSD Computer 2): 16 ГБ RAM, 256 ГБ флеш‑памяти, производительность 3–8× выше HW3.
Оцените производительность: 22 миллисекунды на создание 3D сцены с машинками, пешеходами, велосипедистами вокруг — идет сбор информации с 8 камер 36 раз в секунду.
85 мс на весь цикл от получения картинки до изменения плана и команд колесам. Фантастика!
Более 4 млн Teslas на дорогах ежедневно собирают данные, а в версии FSD Beta зафиксировано более миллиарда миль автономного вождения. Этот «живой» датасет используется для обучения сетей на самых реальных сценариях, включая редкие «edge‑case» (странные аварии, дорогие условия и т. д.).
В июне 2025 Tesla впервые доставила Model Y из завода в Остине к дому клиента без водителя и удаленного оператора — полностью автономно. Это очень круто.
Vision‑сеть не только анализирует текущий кадр, но и хранит признаки от предыдущих (на расстоянии ≈1 м). Это позволяет запоминать недавно пересечённую разметку/знаки, даже если они уже вышли из поля зрения – очень похоже на человеческую память.