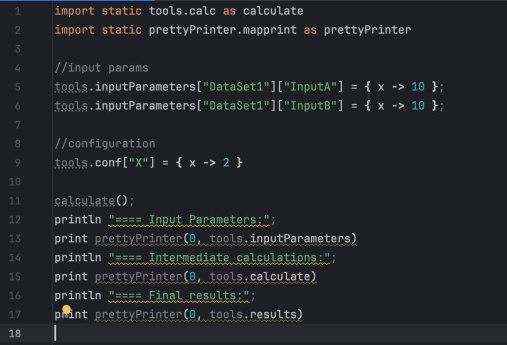
Все мы с этим сталкивались — «Главная Excel-Таблица, Управляющая Бизнесом». Та самая, которую B2B-компании используют, чтобы считать котировки на миллионы долларов. В ней 12 вкладок, 1000+ вложенных формул и ноль документации. Десять лет туда лепили «быстрые фиксы» и прятали константы. Это уже не файл, а живой организм, который уже никто до конца не понимает кроме того чела, уволившегося годы назад. Вот такой я был озадачен. Более того, там еще была неопределенность нужна ли вообще половина формул, или это рудименты прошлого.
Типичная ячейка:
=IF($D11=$D10,»», IF(ISNUMBER( INDEX(Data!$T$10:$U$17,
MATCH(TabCalc!$F11,Data!$T$10:$T$17,0),2)),
INDEX(Data!$T$10:$U$17, MATCH(TabCalc!$F11,Data!$T$10:$T$17,0),2),
INDEX(TabProd!$C$8:$U$112,TabCalc!$D11,I$1)))
Мне поручили перенести эту логику в код, чтобы все считалось софтом. Excel-файл как бы все имел что надо, но по факту — это был сложнораспутываемый черный ящик. 1069 формул.
Челлендж был в том, как перевести тысячу взаимозависимых формул в чистый код и не потерять ни одного пограничного случая (edge case).
В итоге вот что я сделал.
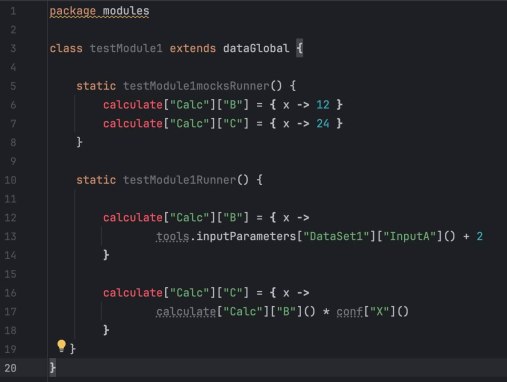
Вместо того чтобы переписывать всё с нуля одним махом с неопределенными перспективыми наплодить багов, я использовал стратегию ленивых вычислений и моков.
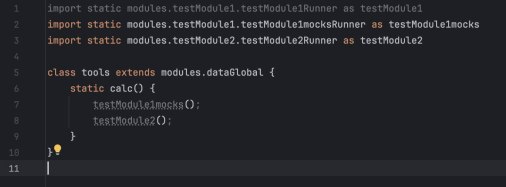
Я построил структуру на Groovy, которая имитировала поведение Экселя. Каждое вычисление (из ячейки) я определил как функцию, которая выполняется только тогда, когда её вызывают. А функциями был многомерный dictionary.
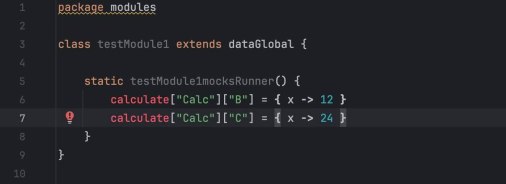
Я пошел с конца графа вычислений: от результатов к входным данным. Если формула зависела от чего-то, что я еще не написал, я «мокал» это в коде, просто подставляя значение из Excel-листа.
Кусок за куском я заменял эти моки на реальную логику. Сравнивая выхлоп моего кода с экселькой на каждом шаге, я точно видел, где моя логика расходится.
Другими словами, движение шло от результата к исходным данным. На каждом шаге было ясно, какие моки надо превратить в код, и можно было сравнить версию +1 с версией -1 — результат должен был совпадать. Как только все моки заменились на вызовы — задача была готова.
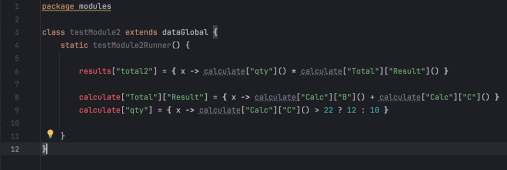
Настоящим «секретным ингредиентом» стала динамическая природа Groovy для создания многомерной карты функций. Вместо статических переменных я использовал глубоко вложенную структуру, где каждый «лист» был замыканием (closure). Это позволило обращаться к любой части таблицы — будь то входной параметр, константа конфига или сложный промежуточный результат — через простой, унифицированный синтаксис, причем некоторые компоненты были динамическими.
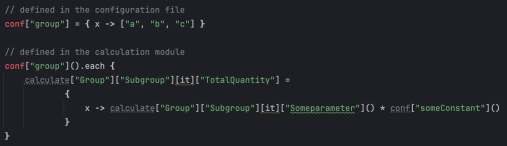
Вот пример:
conf[«group»] = { x -> [«a», «b», «c»] }
conf[«group»]().each {
calculate[«Group»][«Subgroup»][it][«TotalQuantity»] =
{
x -> calculate[«Group»][«Subgroup»][it][«Someparameter»]() * conf[«someConstant»]()
}
}
Используя динамические ключи и замыкания, я мог итерироваться по группам продуктов или наборам данных. Поскольку это были динамические функции, а не сохраненные значения, вся система работала как живой граф зависимостей.
Тестировать можно было прямо сразу после начала переноса формул. Прелесть была в том, что ты вроде как как бы к ячейке обращаешься через синтаксис типа calculate[«Totals»][«A»](), а на самом деле запускаешь целое дерево вычислений в этот момент. И это дико удобно в отладке.
Через две недели «Черный ящик» превратился в прозрачную, модульную библиотеку с понятной логикой, которая выдавала ровно тот же результат, что и оригинальная таблица.
P.S. Ну и конечно, все данные на всех скриншотах тщательно обфусцированы, а точнее сказать, написаны с нуля для этого текста.