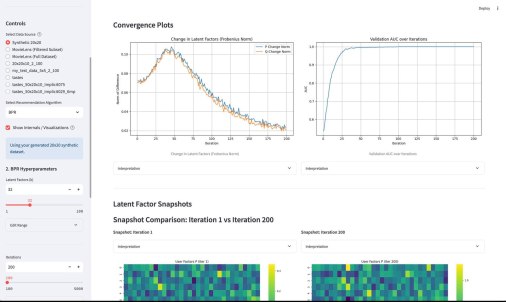
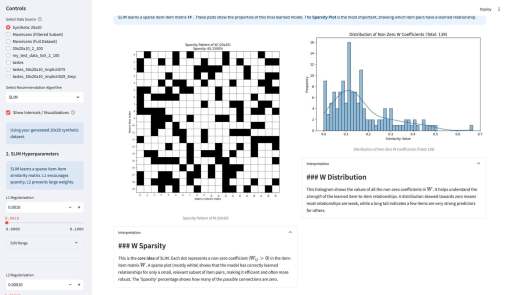
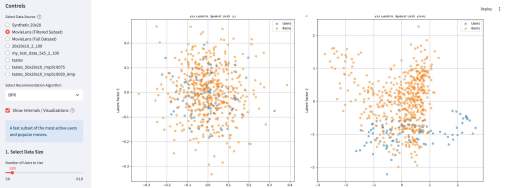
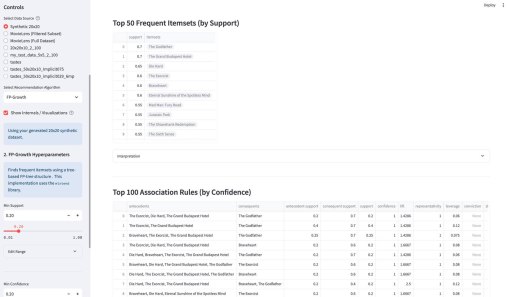
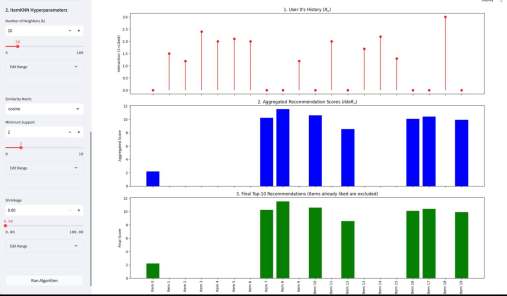
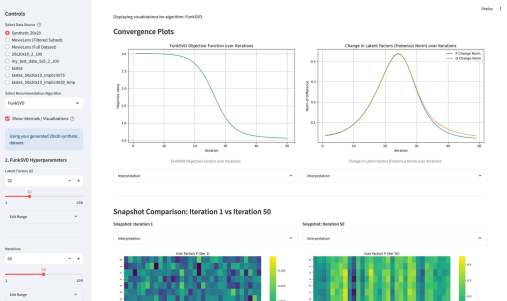
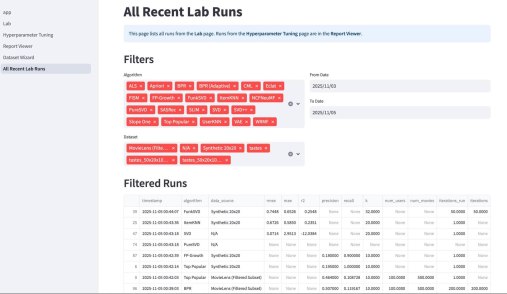
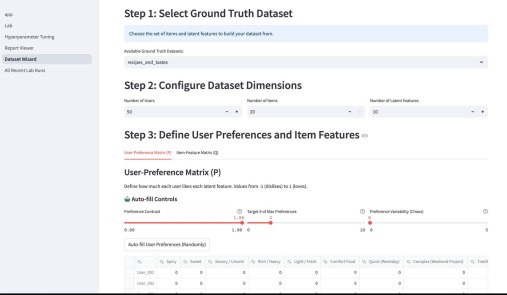
У википедии есть одна большая проблема. Ну или у нас с википедией. Если зайти на практически любую страницу википедии об относительно сложном математическом или физическом понятии, часто резко перестает хотеться ее дальше читать. Формально там все верно, но объяснение дается через концепции, часто еще более сложные, чем объясняемая. Кроме этого, там дается часто много лишнего — то, что формально/академически/таксономически находится внутри темы, но по сути «загрязняет» получение первого впечатления.
Эта проблема возникает потому, что у авторов Википедии (часто математиков) приоритет стоит на строгости и полноте, а не на дидактике и понятности.
В англоязычной среде такое иногда называют «Drift into pedantry» (скатывание в педантизм). Статьи часто пишутся экспертами для экспертов, а не для тех, кто пытается изучить предмет с нуля.
Вот возьмем, например, «тензор». Представьте студента, который слышал, что тензоры используются в машинном обучении (Google TensorFlow) или физике, и хочет понять суть.
Чего ждет читатель (интуиция): «Тензор — это таблица чисел (ну или какой-нибудь контейнер данных), которая описывает свойства объекта и правильно изменяется, если мы повернем систему координат»
Что дает википедия: «Те́нзор (от лат. tensus, «напряжённый», по классической раскладке механического напряжения на гранях деформируемого куба, см.иллюстрацию) — раскладка (расположение в пространстве) чисел (компонент), применяемая в математике и физике как особый тип многоиндексного объекта, обладающего математическими свойствами.» Статья сразу же начинает перечислять ранги, ковариантность и контравариантность индексов. Это формально верно, но это «загрязняет» первое впечатление.
Иллюстрация в самом верху подписана вот так: «Механическое напряжение, деформирующее куб с гранями, перпендикулярными осям координат, в классической теории упругости описывается тензором напряжений Коши (англ. Cauchy stress tensor), который связывает 2 индекса: вектор нормали к грани с вектором напряжения Т (сила на единицу площади); имеются 3 направления нормалей и 3 направления компонент напряжения, что даёт тензор 2-го ранга 3×3 — из 9 компонент.»
Формально — ни одной ошибки. Фактически — это стена текста, которая требует знания линейной алгебры, чтобы просто прочитать определение.
Это как если бы вы спросили «Что такое яблоко?», а вам ответили: «Яблоко — это плод растений подсемейства Сливовые (Amygdaloideae) или Спирейные, обладающий эпикарпием, мезокарпием и эндокарпием, часто участвующий в гравитационных экспериментах Ньютона».
С одной стороны, кажется, что с появлением LLM википедия как бы больше не необходима. Есть же условно LLMы типа ChatGPT, которые по сути пересказывают все то, что есть в wikipedia в нужном виде. Но они так делают, потому что их обучили на википедии, причем наверняка именно википедии дали сильно больше веса при обучении, чем всякому шлаку в интернете. Если бы не было википедии в обучающем сете, все было бы сильно сложнее. При этом википедия постоянно редактируется, и LLM и Google используют именно ее при ответах на вопросы.
Поэтому, с одной стороны, мне кажется, что википедии давно пора переходить на генерацию на основе курируемых экспертами данных и упаковывать знания в требуемом формате, например, в виде вопросов-ответов. С другой, теряется вся идея мастер-данных энциклопедии для LLM/RAG.
Парадокс в том, что LLM — это, по сути, единственный «интерфейс», который смог прочитать эти педантичные определения Википедии, «понять» их (через тысячи примеров кода и статей) и перевести обратно на человеческий язык. Википедия стала отличной базой данных для роботов, но плохим учебником для людей.