Ещё в 1954 году Носов предвидел появление Инстаграмма
P.S. Не очень только понятно зачем разные шаблоны для разных цвет глаз и волос.


Ещё в 1954 году Носов предвидел появление Инстаграмма
P.S. Не очень только понятно зачем разные шаблоны для разных цвет глаз и волос.
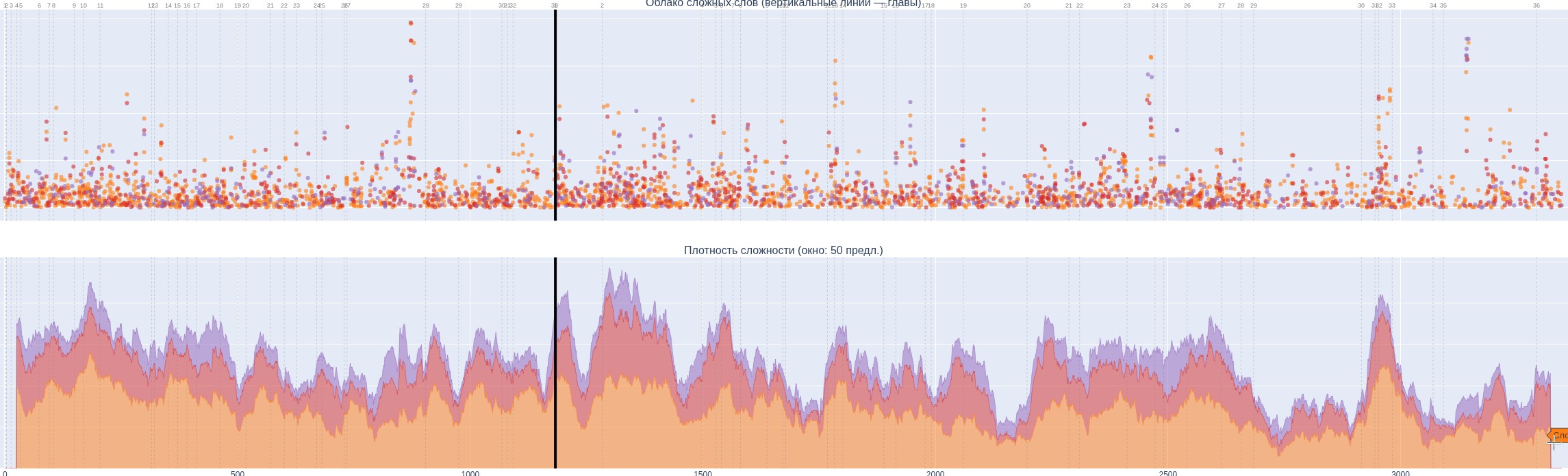
Доделал первую версию книги-словаря по «Лолите» Набокова. На графике показано как распределяется сложность лексики по страницам книги. Нижний график усредняет 25 предложений, по вертикали — число сложных слов, цвета означают сложность/редкость (фиолетовые — самые сложные, красные — менее сложные, желтые — еще менее). Но это я уже убрал еще два уровня, и в целом для иностранца там все пять уровней непростые. В книге пунктиром отмечается уровень 3, простой рамкой — уровень 4, а двойной — уровень 5. Всего сейчас 5794 слова, из которых 541 пятого уровня, 1070 — четвертого, 1883 — третьего, 1393 — второго и 54 — первого (самые простые). Учитывая, что в первой версии получилось 1148 страниц, нужно будет очень сильно подчищать словарь, убирая оттуда то, без чего можно обойтись. Это в существенной степени слова первого и второго уровней, и отдельные из третьего и четвертого. Редкость слов рассчитывается тремя способами : через LLM, и через два списка частот слов англ языка в корпусе текстов (300К слов).
Не все слова сложные. Например, в предложении «With the ebb of lust, an ashen sense of awfulness, abetted by the realistic drabness of a gray neuralgic day, crept over me and hummed within my temples.» наверняка знающему неплохо английский не знакомы слова ebb, abet, drabness, а все остальное знакомо, но чуть снизь требования к читателю, и словарь может быть уже не очень полезным для таких.
Или вот предложение:
Homo pollex of science, with all its many sub-species and forms; the modest soldier, spic and span, quietly waiting, quietly conscious of khaki’s viatric appeal; the schoolboy wishing to go two blocks; the killer wishing to go two thousand miles; the mysterious, nervous, elderly gent, with brand-new suitcase and clipped mustache; a trio of optimistic Mexicans; the college student displaying the grime of vacational outdoor work as proudly as the name of the famous college arching across the front of his sweatshirt; the desperate lady whose battery has just died on her; the clean-cut, glossy-haired, shifty-eyed, white-faced young beasts in loud shirts and coats, vigorously, almost priapically thrusting out tense thumbs to tempt lone women or sadsack salesmen with fancy cravings.
У меня даже браузер подчеркивает тут четыре слова.
У меня есть определения слов на английском, немецком, французском, русском. Я столкнулся с тем, что для разных языков разные слова из текста считаются сложными, а они у меня единые. Так что придется отдельно помечать, например, французские слова в английском тексте, чтобы не включались во французскую версию, так как там читатель знает, например, что такое quel mot.
В общем, на выходных буду убирать, видимо, половину, в ручном режиме, и тогда можно делать обложку и выставлять на Amazon.

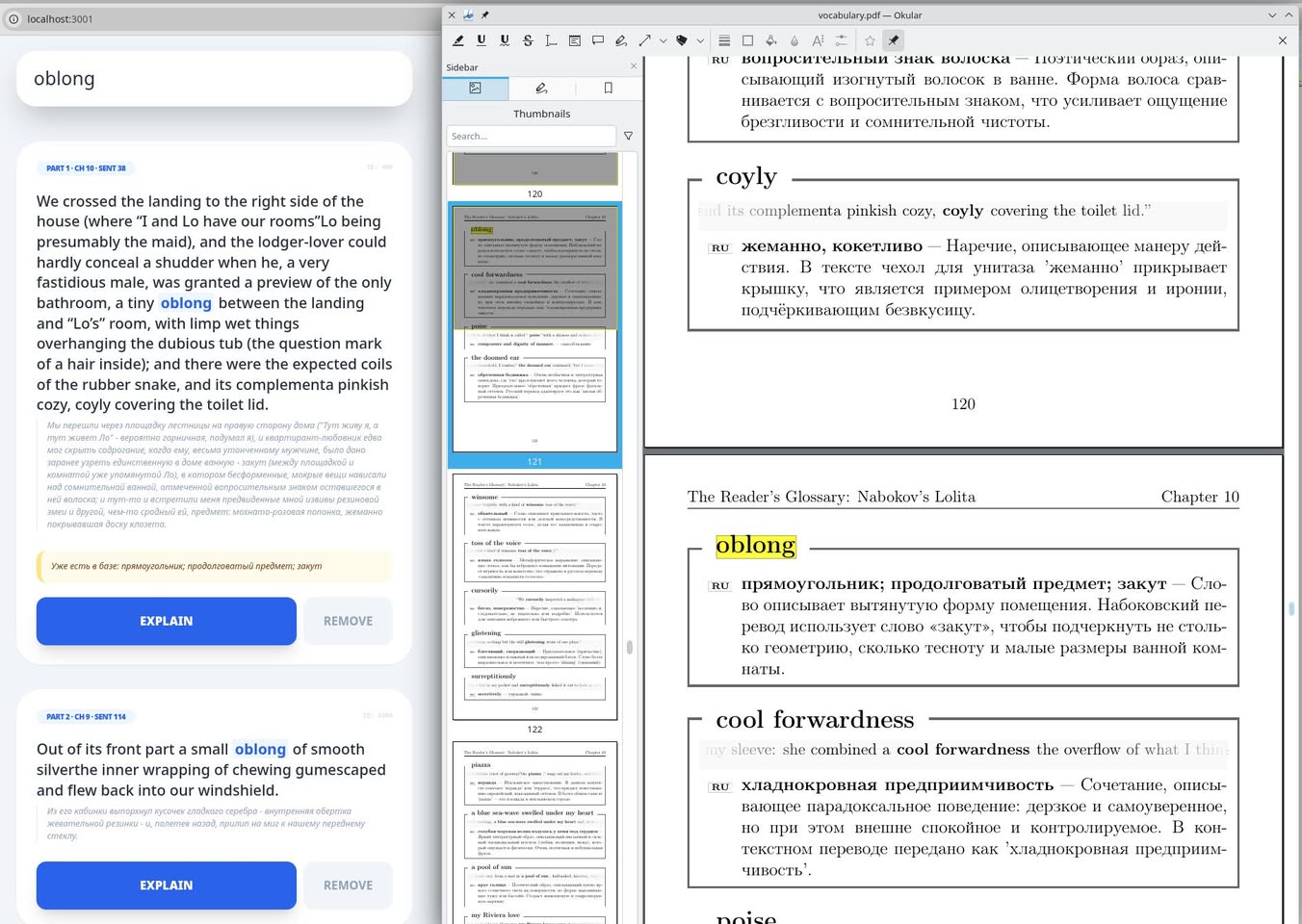
Иногда в английском встречаются очень необычные слова, которые очень непросто перевести на русский. Вот, например, слово oblong. Как прилагательное оно переводится как «вытянутый, продолговатый», но в книге оба использования — существительные. Часто oblong относится к лицу — то есть, близко к овалу, но oblong — это более широкое понятие, которое описывает любую фигуру, имеющую растянутый вид. My mom bought an oblong tablecloth for her new table.
Как существительное оно тоже используется, и довольно часто (хотя реже, чем как прилагательное). Как существительное, oblong — это «прямоугольный объект или плоская фигура с неравными прилежащими сторонами». Линейки считаются продолговатыми предметами (oblongs). Ноутбуки, планшеты и плоские телевизоры — это oblongs разных размеров. Прямоугольник можно определить как oblong; однако не все продолговатые фигуры являются прямоугольниками. То же лицо, например. Ещё, в математике oblong number — это то, что на русском прямоугольное число (произведение двух последовательных чисел. Например, 12). В общем, чёрт ногу сломит.
С 15 века слово живет, между прочим. Так вот, в книжке оно у меня встречается два раза, и оба — существительные. В первом случае Набоков перевел его как «закут», а во втором — «a small oblong of smooth silver» как «кусочек».
Блин, реально ж удобно. Сижу читаю.
Паттерн использования такой: держу телефон в руках. Там в apple books эта и книжка. Видишь незнакомое слово — оно с большой вероятностью будет в списке слов главы. Определение учитывает перевод самого Набокова. Дальше смотришь на пару слов вперёд, убираешь телефон, продолжаешь читать. Встречаешь те слова, и они ещё в кратковременной памяти, и ура, понимаешь. В паузу загружаешь в мозг следующие пару слов. В руках надо держать телефон и перелистывать, каждая страница содержит 4-5 определений.
Сейчас каждое слово имеет определения на английском (толкование), французском, и немецком. Соответственно, я могу издать четыре книжки.
В целом, мой уровень английского совпадает с предположениями моей программки о том , какие слова будут вызывать сложность. Но когда-нибудь мне надо такое для французского, и там понадобится для и каждого слова некоторую оценку уровня сложности, потому что мне будут непонятны и некоторые базовые слова тоже. Не уверен, что книжка с базовыми словами будет удобна. С редкими — точно удобна.

Читаю Набокова и решил отвлечься и сделать удобную программку «Словарь Набокова» и подумываю продавать его на Амазоне как книгу. По сути, выглядит это так (см скриншот) — определения сложных слов на английском, русском, немецком и французском, идущих в том же порядке, в каком они идут в оригинальной книге.
Вы бы купили такую книжку?
Для того, чтобы корректно сделать их определения, я также написал aligner — программу, которая сопоставляет предложения и абзацы на английском с их переводами (набоковским) на русский. И когда создается определение слова, используется не только знание LLM, но и перевод на русский автора. Отдельно стоит рассказать, как работает алгоритм (я его сам придумал, потому что все, что нашел в сети, не работало как мне надо). Он находит сначала длинные предложения, и находит для самых длинных предложений их пару через косинусное сходство embedding-векторов, созданных через модель multilingual e5. Эти предложения становятся якорями. Затем, предполагая, что для длинных предложений ошибка почти исключена, находится самое длинное предложение уже между якорями, и все повторяется заново рекурсивно. Там много ситуаций, когда у предложения на русском нет аналога на английском и наоборот, когда предложение разбито на два, или наоборот два слиты в одно. Алгоритм как может это обрабатывает. Результат — очень неплохое качество выравнивания. До такой степени, что ошибки выравнивания уже не получается находить (но наверняка они есть). Так или иначе, оно нужно только для контекста для перевода слов, даже если там и есть редкие ошибки, то не страшно.
Вы бы купили такую книжку?

У Семихатова очень классный фильм вышел про гравитацию. Конечно, прям слишком популярный, но понятно почему — надо не отпугнуть аудиторию. Очень классно и профессионально сделан.
У меня на полке книжка Семихатова лежит (»Все, что движется»). Тоже популярная, но там несколько серьёзнее изложение, местами с формулами и с кучей иллюстраций. Потом мнение о нём немного смазалось из-за за специфической манеры вести подкасты, постоянно перебивая гостя и отвечая на свои же вопросы демонстративно «круче» гостя. Но в фильме он прям красавец. Рекомендую
Ссылка в первом комментарии

Мой план на 2026:
— Уехать на неделю на Галапагоссы, в Эквадор (лето)
— Дописать и выпустить книжку по Information Retrieval (тоже лето, идет медленно, пара первых глав уже написана. Уже потратил на эту тему часов 50-100, то, что шло легко)
— Выпустить как минимум одну научную статью, видимо по Data Mining (весна). В идеале засабмиттить куда-нибудь в журнал (сложно). Уже потратил на эту тему часов 30, осталось еще дохрена.
— Сделать шаг к PhD. Найти профессоров, посетить универы, понять цену вопроса и оценить свои возможности и ресурсы.
— Продолжить изучать фундаментальную математику и не умереть (линейная алгебра, матанализ, тервер, статистика, классическое ML). В 2025 потратил на эту тему часов 200-400.
— Продолжить изучать Deep Learning и дойти до уровня «могу преподавать». В 2025 потратил на эту тему часов 100-200.
— Продолжить изучать Data Mining/NLP.
— Актуализировать мою книжку по RecSys, выпустив версию 2.0 включив обновления и исправления (осень 2026)
— Добиться видимого прогресса в живописи и игре на фортепиано. Конкретно, доучить серенаду Шуберта (Ständchen, D 889) и сделать хотя бы один холст, который не стыдно подарить.
Если вам кто-то говорит, что математика это точная наука — не верьте. Поскольку у меня сейчас хобби data science, я изучаю всякое разное из разных книжек и у меня взрывается мозг, как вообще может такое происходить в науке, где каждая мелочь должна укладываться в систему, иначе она идет лесом. Пока дело не доходит до нотаций. С ними там какой-то дикий бардак. Набор диалектов.
Взять, например, обычные логарифмы. «Стандарт» как обозначать логарифм зависит от того, в какой комнате университета вы находитесь. В матанализе и теории чисел log(x) почти всегда означает натуральный логарифм ln(x) база e. Производная от e^x равна e^x. Это «естественно». Писать ln им лень. Там, же где могут вылезти дясятичные логарифмы (computer science тот же), log(x) внезапно становится десятичным, а ln(x) — по основанию e.
Матожидание E имеет аргумент в квадратных скобках. При этом те же квадратные скобки в computer science используются для степ-фукции 0/1.
Или вот если вы видите вектор — это столбец или строка? В классической математике вектор — это всегда столбец. Чтобы умножить его на веса, мы пишем T после вектора и потом w для весов. Но во многих пейперов векторы мыслятся как строки. И если вы видите y = xW+b , то x — это не столбец, потому что иначе размерности не сойдутся. x тут — строка. но в следующей статье пишут Wx+b. И тут x — столбец 🙂
Угловые скобки . Для скалярного произведения (dot product) используется знак «⋅», но его плохо видно, особенно на доске, и я очень часто вижу, что математики используют угловые для dot product. Вообще по науке угловые используются для обобщенного (generalized) понятия inner product, где скалярное произведение частный случай. означает некий абстрактный способ перемножить a и b и получить число. Причем в квантовой механике это бы записывалось как . А еще для скалярного произведения некоторые используют кружок с точкой или x в кружочке.
Ну и для кучи еще в России тангенс — это tg, а в США — tan. А есть еще tan^-1 и arctan, что одно и то же, хотя x^-1 вообще означает 1/x

У меня дома в Коломне есть книжка Химический тренажер 1986 года. Я таких никогда не до и не после не видел.
Материал каждой из 54 программ подразделяется на множество мелких, очень коротких частей, или рубрик. В конце каждой рубрики задается один или несколько вопросов. Это делается с целью проверить – действительно ли понято содержание данной рубрики. У каждого ответа есть место в книге, куда нужно перепрыгнуть, чтобы почитать, правильный ли ответ. Если ответ неправильный, там описывается, почему и задается новый вопрос. Если правильный — продвигаешься в этом квесте дальше.
Эти немцы в 1986 году сделали интерактивный учебник еще до того, как это стало модным.





Заумный пост сегодня. Пока писал книгу по RecSys, поймал себя на мысли, что современный data science — это, по сути, алхимия 21 века. За половиной «лучших практик» в алгоритмах нет хорошего математического аппарата. Это набор эвристик, которые «просто работают». Причем как в 17 веке смешивали все подряд, так и сейчас смешивают, и если что-то сработало лучше, все остальные начинают делать так же. Ответа на вопрос «почему» просто нет.
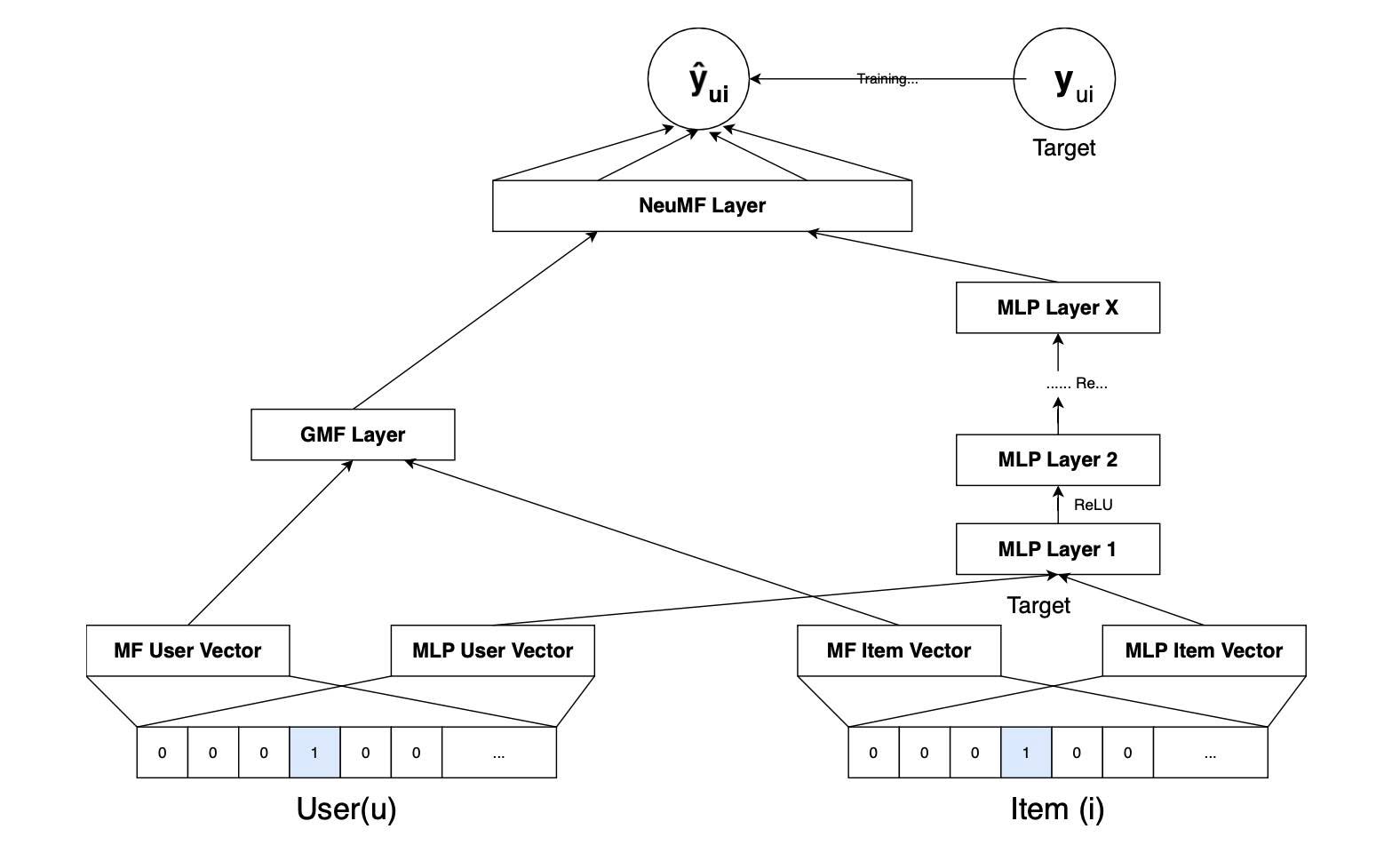
Возьмем, к примеру, алгоритм NCF/NeuMF (Neural Collaborative Filtering). Там такая логика. Есть, скажем, миллион оценок пользователями фильмов. И 100 миллионов оценок пользователями еще на даны — пользователи ж не могут посмотреть все фильмы на свете. Но из этих 100 миллионов для конкретного пользователя надо выбрать кандидатов для рекламы. У алгоритма, конечно, есть фаза тренировки, когда рассчитываются веса, и стадия предсказания, когда эти веса используются на входящих данных.
(Что делает алгоритм. Там по сути ансамбль из три подалгоритмов, два из которых генерят каждый свое заключение, а потом их решения поступают на новую нейронку, третий алгоритм, который дает финальную рекомендацию. По-умному это гибрид GMF (матричная факторизация) и MLP (многослойный персептрон) Первый из этих двух основан на разложении матриц, а второй представляет собой нейронную сеть из нескольких слоев. На тренировочных данных подбираются веса.)
На один позитивный пример он берет 4 негативных. Потому четыре? Да просто это «не много и не мало». Будет ли 8 лучше? Неизвестно, но учиться будет точно дольше.
Почему размерность эмбеддингов 32? или 64? Нет никакой формулы. Это «золотая середина» между «тупой» моделью (мало k) и «переобученной» (много k).
Теперь про нейронку. Почему MLP-блок строят «башней» (64 -> 32 -> 16)? Почему не (50 -> 25 -> 10)? Почему между ними ReLU (а не tanh например)? Чистая эмпирика. Число слоев в башне тоже подбирается.
Почему у GMF и MLP-частей разные эмбединги на входе? Потому что авторы статьи попробовали, и так «получилось лучше». Мат. доказательства нет. Почему на финальный слой они идут с равными весами? Потому что потому.
Почему выходы двух путей «склеиваются» (concat), а не складываются или перемножаются? «Опыт показал, что так результат точнее».
И так во всем, вплоть до выбора оптимизатора Adam или «магического» learning_rate=0.001, хотя с этими по крайней мере понятен матаппарат.
То есть, у одного алгоритма как минимум с десяток параметров подобрано эмпирически, при этом однозначной уверенности, что они независимые друг от друга — нет. Зато многие из них зависят от датасета, но никто не знает как 😉
В общем, алхимия.