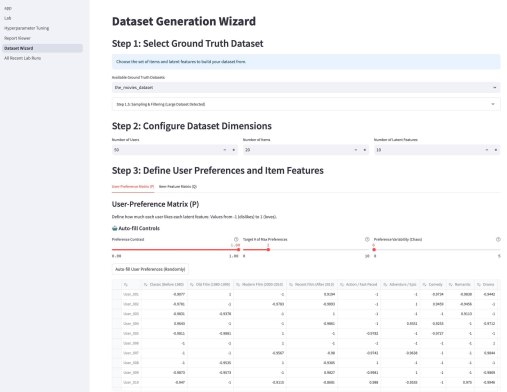
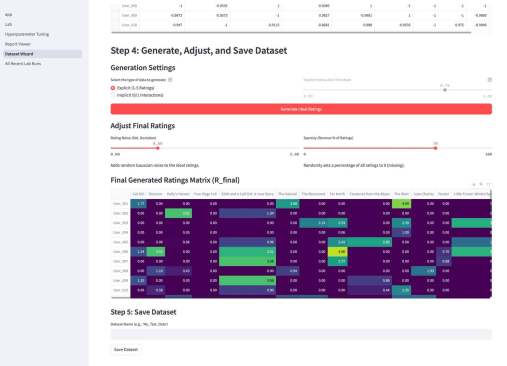
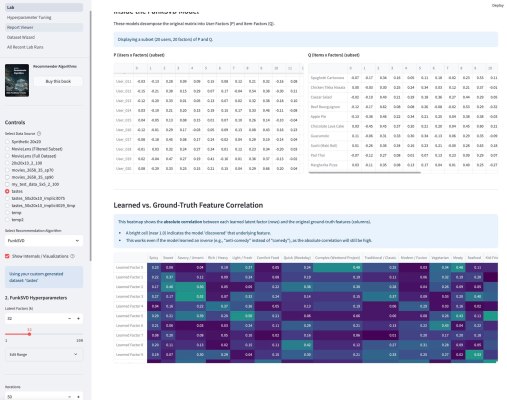
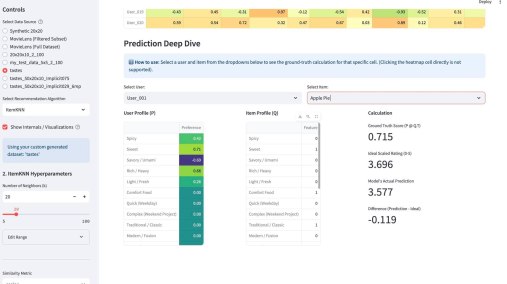
Ух какую я прикольную задачку только что решил. Хрен только объяснишь. Ну я попробую.
Короче, у клиента есть 10 сайтов с поиском. Они все используют один индекс, но кидают разные запросы к нему. К тому, что вводит пользователь, прибавляется очень длинный и сложный query, который генерирует модуль на сайткоре. Он содержит айдишники шаблонов и страниц, которые нужно включать или исключать. В итоге понять, что там происходит, вообще невозможно. Там может быть десять открывающих скобок и где-то рандомно закрывающие, но с Coveo работало. Реформаттинг помогал, но не сильно.
И у каждого сайта такое свое. При этом там фигурируют периодически одни и те же айдишники. Я сначала пытался в этом вручную разобраться, но это был кошмар. Ни фига не помогает. Там же еще вложенные условия. Например, «исключить этот шаблон» не глобально, а только если вон то поле равно единице.
В итоге вот что я сделал:
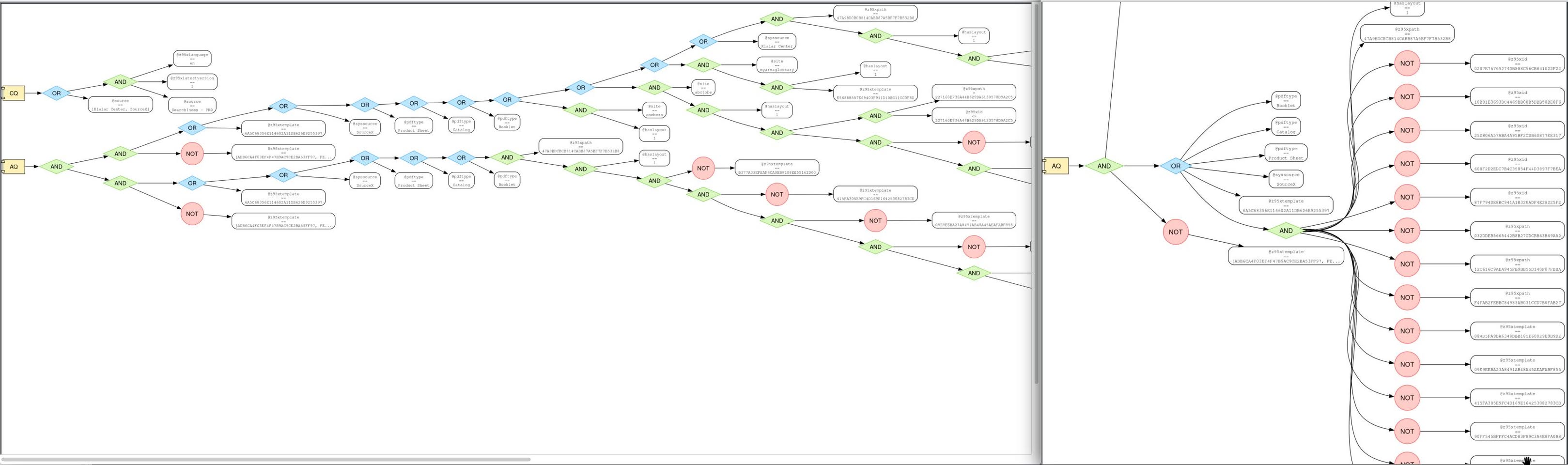
Написал скрипт, который разбирает эту текстовую «кашу» в абстрактное синтаксическое дерево (AST). Это позволило превратить нечитаемую строку в структурированный JSON-объект, где четко видно: вот тут AND, тут OR, а тут — конкретное условие.
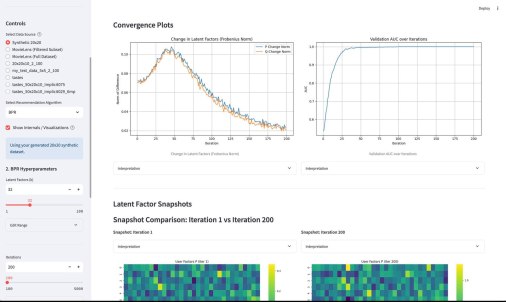
Дальше я превратил эти условия в формулы булевой алгебры. С помощью библиотеки SymPy я «скормил» эти формулы алгоритмам упрощения. Математика сама выкинула дубликаты, схлопнула лишние вложенности и убрала условия, которые логически поглощаются другими. В результате «деревья» стали плоскими и понятными.
В аттаче — оригинальное дерево и упрощенное.
Чтобы быть уверенным, что я ничего не сломал при упрощении, я написал генератор тестов. Он берет упрощенную логику, собирает её обратно в рабочий curl и проверяет, совпадает ли количество найденных документов (totalCount) с оригинальным запросом. Цифры сошлись — значит, логика сохранена на 100%.
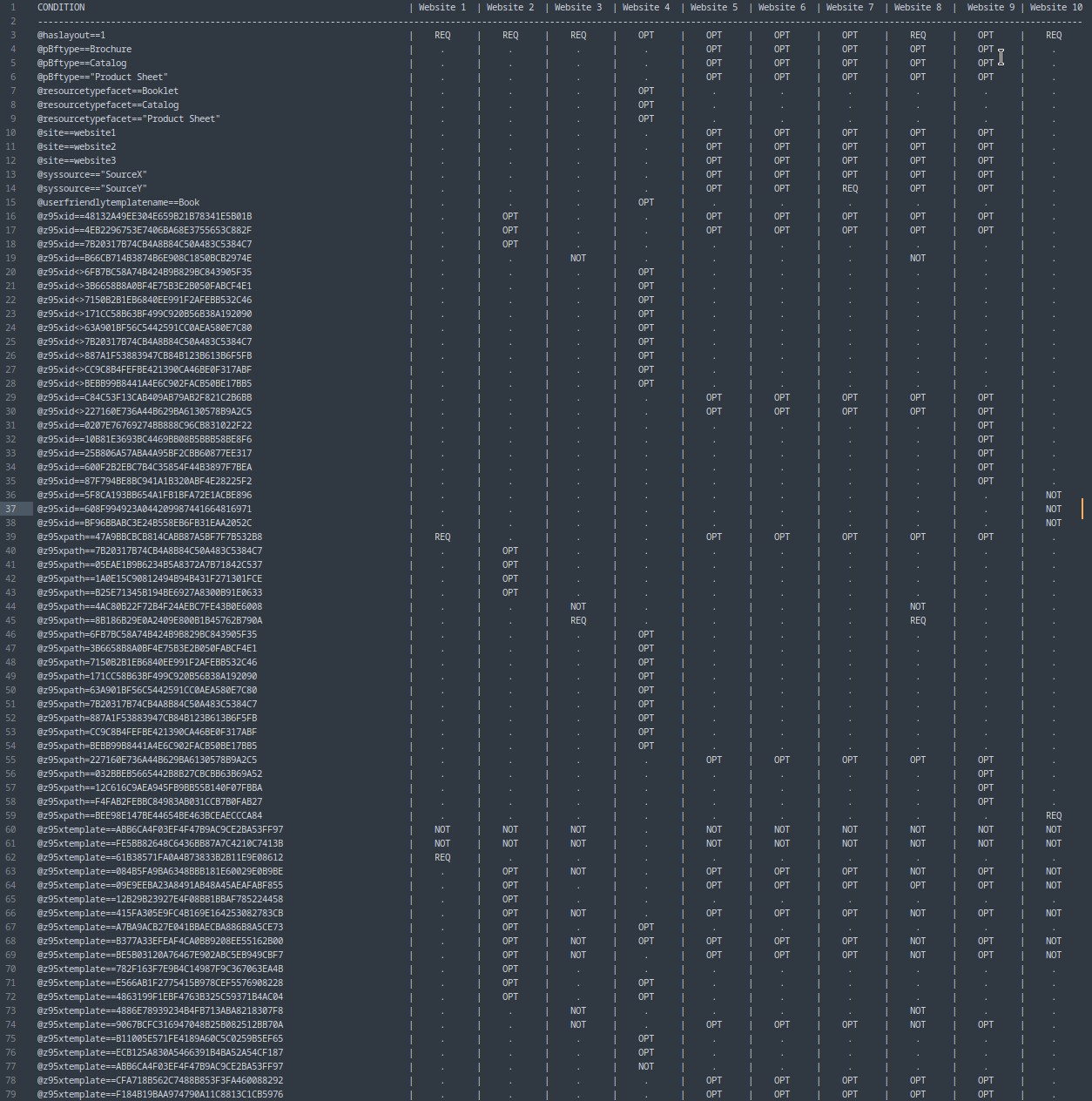
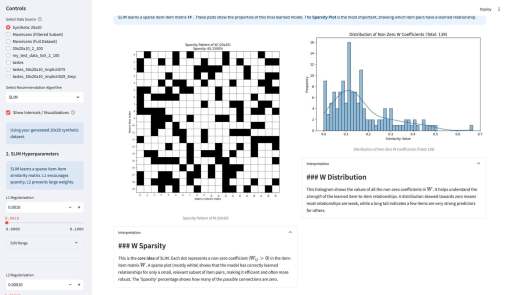
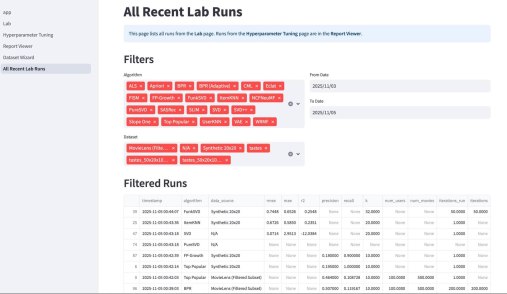
Имея на руках упрощенные и стандартизированные структуры для каждого сайта, я построил матрицу сравнения. Скрипт проанализировал их и выделил Common Core — условия, которые гарантированно требуются (или запрещены) на всех сайтах без исключения, и Specifics — уникальные «хвосты», которые отличают один сайт от другого.
На приложенном скриншоте: REQ означает, что условие гарантированно выполняется для любого документа, который пройдет через этот запрос. NOT — гарантированно не выполняется. OPT — условие присутствует в запросе, но оно не является строгим само по себе. Оно работает только в связке с чем-то еще. «.» — условие вообще не упоминается в запросе.
Для 3 сайтов моментально отвечает, для 10 работает минут 30.
Ну и конечно, все данные на всех скриншотах тщательно обфусцированы.