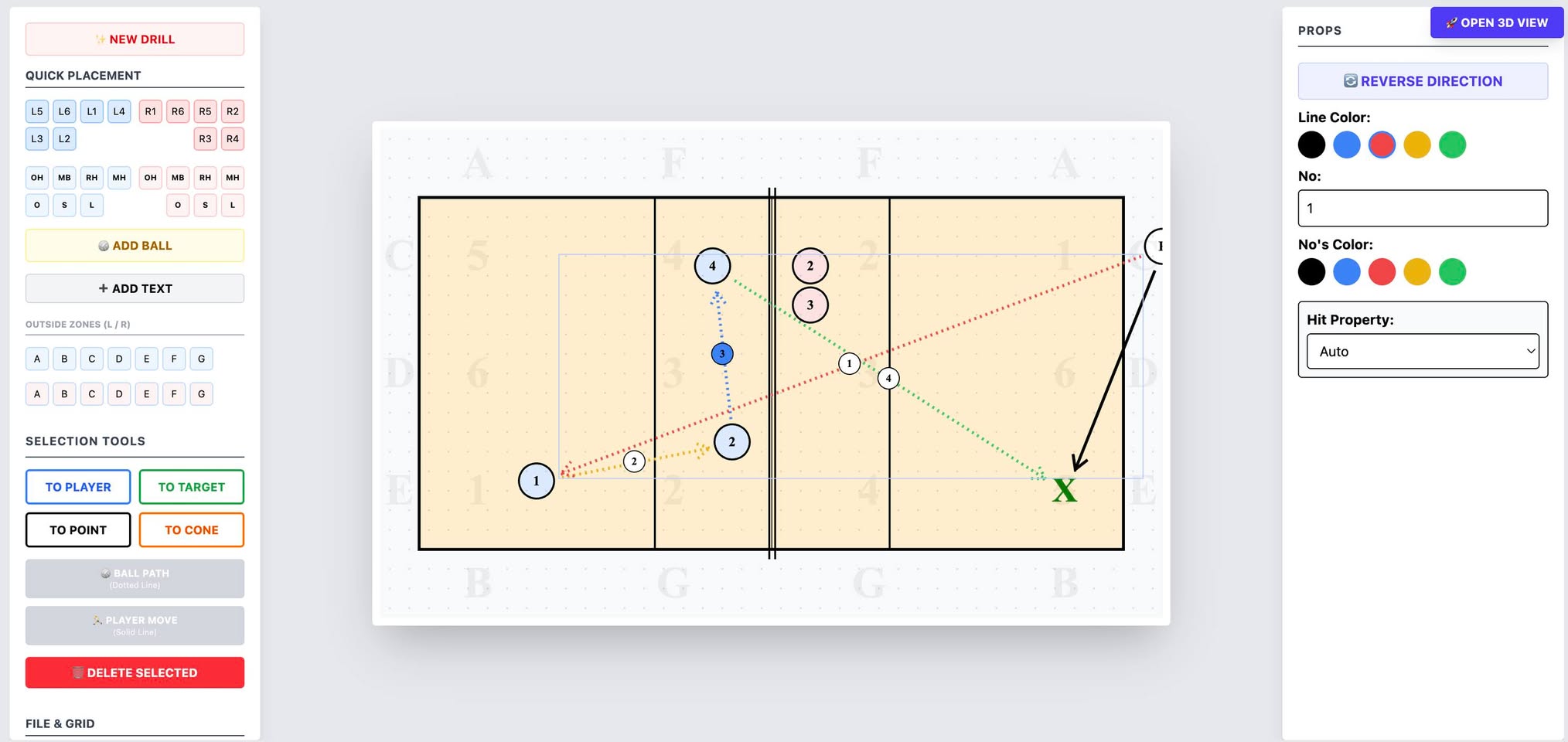
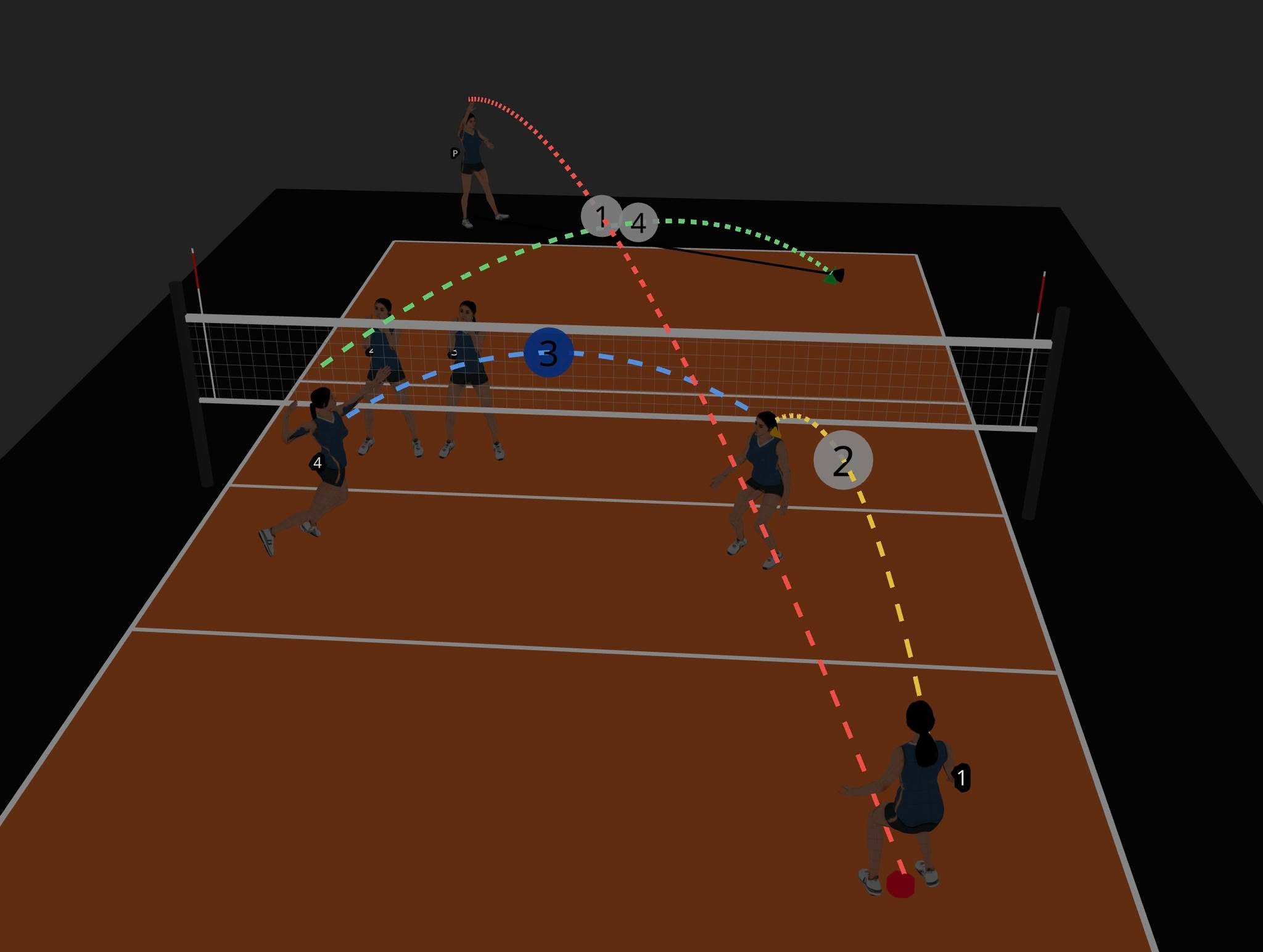
Чем я занимался в самолете в/из отпуска и иногда между и после: 3D-визуализация и редактор волейбольных схем для Нади (она — тренер). Этот корт на приложенном изображении свободно вращается, на нем могут быть поставлены игроки, и указан путь мяча и игрока — все в 3D.
Траектория мяча рассчитывается так, чтобы мяч не пересекал сетку при движении из A в B (формула Безье). Игроки могут принимать несколько поз — прямо сейчас есть наспех сделанные позы serve, attack, block, pass/receive. Кстати, из интересного в коде: пришлось прописать немного «волейбольных мозгов». Система сама считает траекторию мяча через кривые Безье так, чтобы он всегда проходил над сеткой. Причем высота вылета зависит от типа действия: для атаки мяч «вылетает» с более высокой точки, чем а для паса. Еще добавил авто-разворот: 3D-моделька сама поворачивается лицом туда, куда она по схеме должна пасовать или бежать.
Дольше и сложнее всего было сделать 3D-модель волейболистки. Для генерации реалистичной волейболистки я использовал сервис tripo3D. Он мне выдал модель в нейтральной позе (бесплатно выдал). Теоретически дальше с помощью Blender и плагина Rigify можно прицепить к ней armature и двигать руки-ноги, за которыми будет пересчитываться модель.
Однако в реальности такой подход не срабатывает: сгенерированная ИИ модель содержит большое количество геометрических ошибок, которые прощает рендер, но не прощает Rigify. Их можно условно разделить на два вида — неверные нормали полигонов и проблемы с немногообразной (non-manifold) геометрией, которые исправлять значительно сложнее. Внутри корпуса могут «плавать» невидимые кластеры полигонов или пересекающиеся поверхности. Когда Rigify пытается рассчитать веса (какая кость на какую часть кожи влияет), этот внутренний шум сбивает алгоритм с толку, и в итоге веса распределяются хаотично (например, движение руки может начать тянуть за собой сетку на животе). Плюс модель немного не симметрична.
Non-manifold — это ошибка геометрии, при которой топология объекта перестаёт быть корректной с точки зрения трёхмерного тела: рёбра могут принадлежать более чем двум полигонам, полигоны могут соприкасаться только вершинами или рёбрами без общего объёма, внутри модели появляются «висящие» поверхности или нулевая толщина. Такая геометрия формально не описывает замкнутый объём, из-за чего возникают проблемы с риггингом и деформациями. Кроме этого, нужно упростить модель, потому что для рендера в реальном времени в браузере миллионы полигонов не нужны.
Я исправлял это с помощью MashLab, попутно дорабатывая «напильником» (руками). В итоге получается модель, чуть-чуть отличающающаяся от исходной почти везде. На исходной же модели нацеплена «кожа» в виде текстуры — лицо, майка, шорты должны быть раскрашены. Как все это перенести на упрощенную модель? Для этого есть специальная операция в Blender, называется Baking. Там тоже шаманство. В итоге неидеально перенеслось, но идеально пока и не нужно.
Дальше привязываем арматуру к «суставам», и через часа три разбирательств, почему все работает не так, как должно, оно все-таки заработало. Я сделал четыре позы, и теперь каждому кружочку (игроку) можно указывать в какой позе он стоит.
Еще нужно будет сделать динамическую смену раскраски формы — это не должно быть сложно. Есть еще идея переносить позу с фотографии — это посложнее, но в целом реалистично. С помощью MediaPipe/AlphaPose можно детектировать ключевые точки в 2D, затем с помощью каких-нибудь моделей типа HMR/HybrIK можно «поднять» плоские координаты в 3D-пространство, выдавая относительные углы поворота суставов. Полученные данные можно попробовать спроецировать на Rigify-скелет. Поскольку пропорции сгенерированной волейболистки и человека на фото могут не совпадать, как раз и используется Inverse Kinematics (IK). Это довольно сложная часть, но в целом она уже не очень обязательная — просто интересно разобраться и сделать что-то работающее.
Видео в комментах