
Забавно, у нас тут “entertainment center“ — это шкаф


Забавно, у нас тут “entertainment center“ — это шкаф
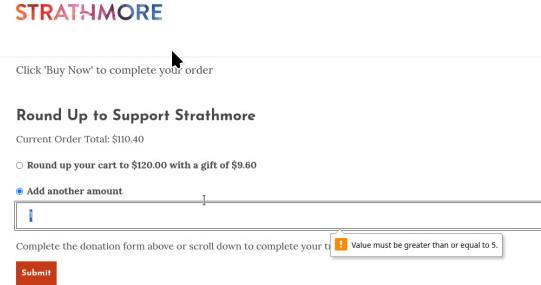
Вот ж редиски. Если случайно выбираешь ответ на «хотите нам пожертвовать», то дорога к «ой, не хочу пока» занимает минут 10 и сопряжено с риском потерять места. Потому что 1) нет пункта не хочу 2) любой выбор стоит от $5 до $9.60 3) рефреш страницы приводит к ошибке, надо заново выбирать места и стараться не попадать мышью в эти радиокнопки. А места, между прочим, последние два места в зале. Вчера их вообще не было, сегодня появились.
Еще доработал новый тул для себя для работы с информацией и её организации. Основная идея — это веб-блокнот для исследований, изучения темы, работой над ней, интегрированный с AI и поддержкой PDF.
Главная проблема обычных PDF-ридеров и заметок заключается в том, что контекст теряется, как только вы переключаетесь на новую вкладку. В моем инструменте каждый фрагмент текста или PDF становится узлом в «живом» гипертекстовом дереве, к которому я могу доступиться с нескольких компов в любое время.
Процесс работы:
— Контекстный AI. Я могу просить AI разъяснить сложные пассажи прямо внутри документа. Объяснение остается именно там, где был задан вопрос. При этом оно является отдельным документом, привязанным к конкретному месту в источнике. При клике вы видите на экране одновременно и оригинал, и пояснение.
— Панели вместо окон. Если само объяснение требует уточнений, справа открывается новая панель. Это позволяет выстраивать бесконечную цепочку запросов, ни разу не теряя места в исходном тексте. То есть, вы видите сразу несколько панелей, ненужные можно закрыть.
— Поддержка PDF. Я могу загрузить PDF, выделить область на странице (например, сложную диаграмму или список авторов), и LLM мгновенно извлечет данные, дополнит или объяснит их. Объяснение прицепится к месту, где его просили, как и в случае не-PDF.
— Вложенные аннотации. Мои комментарии — это не просто статичный текст. Они могут содержать собственные PDF, ссылки и дальнейшие подзадачи для AI, поддерживая глубину вложенности, которая отражает то, как мы мыслим на самом деле.
Это не просто система хранения файлов, а «движок» для построения знаний.
Инструмент отлично подходит мне лично, но, возможно, он решает только мои специфические задачи. Как вы думаете, будет ли нечто подобное полезно другим? Было бы это полезно вам? Стоит ли развивать проект до полноценного продукта и давать его на тест другим пользователям?
Некоторые мысли по поводу LLM и искусственного интеллекта в целом. И в конце про нейроморфные процессоры и Intel Loihi.
Как вы все знаете, фундаментально LLM работают по принципу «предлагай вероятное следующее слово, используя контекст из предыдущих N слов», и затем слово попадает в контекст, и повторяется все заново для следующего слова. Ну еще и контекст там обрабатывается с учетом важности слов.
А теперь задумаемся, как в первобытных обществах учили языкам детей. Никаких азбук не было, как и грамматики. Но вот сама грамматика, по оценкам, была довольно сложной — по наблюдениям за малыми языками малых народов. Простая грамматика — это современное, когда язык распространился на миллионы и миллиарды.
То есть, мозг ребенка должен реконструировать в своих нейронах грамматику просто на потоке речи от окружающих и через тестирование на понимание сказанного. Возможно, ребенка поправляли, если он говорил неправильно, но как-то эта грамматика и звукоизвлечение должны были улечься в мозг — и вот тут используется тот же механизм, что и в LLM: какие слова/звуки идут рядом в каком контексте определяется латентными и не интерпретируемыми правилами, которые каждый человек в детстве создает в своем мозгу на свой лад. То есть, грубо говоря, тренирует модель ML каждый раз с нуля на потоке речи от окружающих. Ребенок не знает, что такое «падеж», но чувствует, какое окончание статистически более вероятно в данном контексте.
Собственно, современная когнитивистика (теория Карла Фристона) утверждает, что мозг — это буквально «машина предсказания». Мы постоянно генерируем гипотезы о следующем звуке или слове и корректируем их при несовпадении (ошибка предсказания).
Особенность LLM в том, что для нее учителя — это тексты и картинки, а для мозга ребенка — это живой мир вокруг, и если все тексты, которые он слышит, оцифровать, то объема не хватит даже на тренировку очень слабой модели. LLM видит слово «яблоко» рядом со словом «красное». Ребенок видит яблоко, чувствует его запах, вкус, вес и одновременно слышит звук. Эта «сшивка» разных сенсорных каналов позволяет выстраивать нейронные связи в тысячи раз быстрее, чем на чистом тексте. То есть, LLM современные берут брутфорсом — просто наблюдают за речью миллиардов, а не только своего ближайшего окружения. Хороший вопрос как мозг человека умудряется научиться на относительно маленьком датасете. Правда, большой вопрос маленький ли это датасет — например, движения губ, мимика, контекст дают очень много для построения этой нейронной сети в биологическом мозгу.
Про контекст: в отличие от LLM, ребенок понимает намерение говорящего. Если мама смотрит на чашку и говорит «горячо», мозг ребенка ограничивает пространство поиска смыслов одной чашкой. И если он не понял, то обожжется и запомнит.
Можно, конечно, предположить, что мозг уже при рождении имеет готовую сеть. Оно так, но наука пока это не может нормально объяснить. Вся наша генная программа насчитывает порядка 20 000 генов, кодирующих белки, и эти 20000 отвечают вообще за все — где и как должны быть построены легкие, сердце, кости, кровь, и сами по себе что ни возьми, все имеет запредельную сложность, и где-то среди 3 млрд нуклеотидов и 20 тыс генов эта информация должна быть записана.
Судя по всему, гены кодируют не карту, а алгоритм самосборки. Фактически, архитектура нейронной сети строится динамически, и начинается этот процесс задолго до рождения. Далее она калибруется по всем сигналам, которые принимает еще не родившийся ребенок, и к моменту рождения в мозгу уже есть как-то настроенная сеть.
Вероятно, что мозг ребенка — это миллионы нейросетей разных «архитектур», которые эволюционно усложняются, объединяются в процессе обучения. В отличие от LLM, где обучение и использование жестко разделены во времени. Но самое главное — мозг хоть и самый энергозатратный в организме, но в абсолютных значения он крайне мало потребляет энергии, особенно, если сравнивать с текущими «кандидатами на заменители в железе».
Последние годы активно идут разработки в области нейроморфных систем (например, процессоры старенький IBM TrueNorth и активно разивающийся Intel Loihi). В обычном AI нейроны передают числа (0.15, 0.88…). В нейроморфных системах они передают «спайки» (импульсы) — как в живом мозгу (и архитектура называется Spiking Neural Network — SNN). Несколько лет назад Intel выпустила Loihi 2. Полностью программируемая. Нейроны на Loihi могут менять свои связи (синапсы) прямо во время работы. Поддерживает пластичность — тот самый биологический механизм, когда связь между нейронами усиливается, если они часто «срабатывают» вместе. Но главное — потребляет очень мало.
В этой архитектуре модель может дообучаться «на лету» прямо во время работы, не забывая старые данные (Continual Learning). Кроме этого — экстремальная энергоэффективность.
Loihi 2 не умеет перемножать матрицы как это делают современные GPU, поэтому для них нужно вообще с нуля писать софт (и движется это очень медленно). Никакого PyTorch или Tensorflow — для Loihi есть только фреймворк Lava на сегодня. Ну и 1 млн нейронов от Loihi 2 для LLM очень мало. Поэтому Intel создает системы вроде Hala Point — это массив из 1152 процессоров Loihi 2. Он содержит до 1,15 миллиарда нейронов. Теоретически, по своей эффективности при работе с AI-моделями такая система может превосходить классические GPU в 10–50 раз по показателю «производительность на ватт».
На Loihi 2 уже запускают экспериментальные LLM (например, модели на 370 млн параметров). Они пока не заменят ChatGPT в облаке, но теоретически они — будущее для «умных» роботов и гаджетов, которым нужно понимать человеческую речь, работая от маленькой батарейки.
Понаблюдаем. Может оказаться пшиком, а может быть еще одной большой революцией.
Запилил буквально за час такую штуку. Как думаете, она кому-то кроме меня нужна?
Идея такая. Берем любой текст — статья, например, википедии. Выделяем любой фрагмент, например, что непонятно. LLM нам дает объяснение, и тут же в текст втыкает врезку. На которую можно кликнуть, и откроется объяснение. В этом объяснении может быть тоже что-то непонятно. Выделяем мышью уже из этого, и там тоже появляется врезка. И так, пока не разберемся. Все врезки остаются в тексте, так что всегда можно к ним вернуться. Как бы идея, раз мне тут было непонятно, может и другим не будет, и тогда им очень кстати будет готовая ссылка с разъяснениями. Результат можно зашарить с коллегами.
Для разъяснения конечно используется не только фрагмент, но и контекст. Например, иначе бы выделенное слово Terrier выдавало бы текст про собак, а не про про поисковую систему.
Сходили вчера на фильм Mercy с Крисом Праттом. Бекмамбетова! Его формат «скринлайф» наконец-то раздули до блокбастера за $50 млн и засунули в IMAX. Вообще молодец чувак. Сначала снимал шесть Ёлок, а потом рраз — и в люди выбился и даже что-то нормальное стало получаться. (Сидели одни в зале в суперкраслах с моторчиками. Пустые залы — это вообще норма для последних много лет. Я не знаю, как кинотеатры вообще окупаются. Там даже бар закрыли, работает только в викэнды, когда приходит больше двух человек на зал)
Короче, сюжет. Недалекое будущее. Система правосудия максимально оптимизирована: вместо присяжных и многолетних апелляций — беспристрастный AI. Главного героя (Крис Пратт) обвиняют в жестоком убийстве собственной жены. Улики против него весомые, а общество требует крови.
Его сажают в высокотехнологичное кресло и дают 90 минут. Это «окно» для защиты — время, за которое он должен убедить алгоритм в своей невиновности. Если через полтора часа шкала «вероятности вины» не упадет ниже критической отметки — его казнят прямо на месте. Все происходит в реальном времени, фильм 90 минут и идет.
В эпоху нейросетей это выглядит очень своевременно. Скринлайф тут идеален: мы видим улики и мир глазами системы через камеры и браузеры. Крис Пратт и Ребекка Фергюсон в кадре — всегда плюс.
Правда, вот что вызывает сомнение — это попытка скрестить ежа с ужом. Скринлайф хорош своей камерностью, а тут нам продают IMAX 3D, взрывы и погони, хотя 95% времени герой просто сидит в кресле.
Классическое кино для стриминга. Неплохое. На диване под пиццу в пятницу вечером — зайдёт на ура, детективная линия там рабочая. Может мозг взорваться от уймы деталей. Большой вопрос надо ли платить за билет в IMAX, чтобы смотреть, как Пратт смотрит в монитор… Хрен знает. Местами там есть движуха, и неплохая, но именно что местами.
В целом, любителям детективов должно зайти. По сюжету понятно, что чувака под конец фильма на кресле не зажарят, собственно вопрос как он выкрутится.

Угадаете что это?;)


Сегодня Walmart преодолел планку в 1 трлн долларов капитализации, а я в него сходил






Поскольку у меня теперь есть плоттер, я вовсю играюсь со способами алгоритмической стилизации изображений. Чтобы получить то, что приложено, использовался алгоритм Minimum Spanning Tree. По сути, он преобразует изображение в стохастическое растрирование — то есть, где темнее, там точек больше, и затем соединяет точки линиями так, чтобы все точки были связаны в одну единую сеть, общая длина всех линий была минимальной, и не было замкнутых циклов (то есть это именно «дерево» с ветвями, а не «паутина»).
И вот это я делаю над каждым из каналов CMYK, а затем результат объединяю в цветную картинку. На этой картинке как бы нет других цветов, кроме этих четырех CMYK, но на самом деле немного есть, потому что какое-то сглаживание пробралось.
Напечатать такое на плоттере, конечно, сложно, это я вечность буду ждать, но руки набиваю, первую цветную картинку я уже напечатал (так себе получилось. Ну первый блин комом. В комментах)

Собрал плоттер из набора. Практически лего набор — высыпаешь из коробки россыпью детали и дальше читаешь мануал. Заработало сразу. Есть идеи что с этой штукой делать, расскажу как-нибудь.



