Наконец-то я выпустил книгу! Она называется Recommender Algorithms — в ней я собрал более 50 алгоритмов рекомендаций с математическими выкладками, подробным описанием и примерами кода.
Все началось ранней весной в Германии, когда я посетил конференцию ACM и сделал первые наброски структуры книги, анализируя доклады по потоку RecSys. И вот, спустя полгода, книга увидела свет.
Почему она появилась? Потому что ни в интернете, ни в печати нет единого, доступного источника, где подробно разбирались бы алгоритмы рекомендаций разных типов и назначения. Есть статьи, сфокусированные на узких аспектах, но собрать и систематизировать разработки — от фундаментальных до самых недавних — до сих пор, кажется, никому не удавалось почему-то. Может, это никому и не надо было. Мне вот вдруг стало надо. Не знаю, получилось ли у меня, но буду рад вашим отзывам.
Продаётся на amazon и Barnes and Noble. Есть русский автоматический перевод (удивительно, но очень неплохой), но я не знаю, как его продавать пока.
(Это не единственная моя книга, но сегодня — только об этой.)

Готовлю к публикации книжку по Solr&Lucene. Как вы думаете, публиковать такой перевод на амазоне? 🙂
Книжка про алгоритмы и подкапотную инженерию. Я с этого ракурса еще не видел книг, может, будет кому интересна.



Купил себе AI микрофон, который слушает все вокруг и даёт саммари. Решил для теста разок включить. С ним даже рилсы не посмотришь при выключенном микрофоне на компе, потому что он пытается объединять и обобщать все, что слышит;)
«..Команда методично продвигалась через сложные сопоставления, но неожиданные фразы вроде «Watch the video back if you didn’t notice» и «Don’t be a sucker» создавали тихий, почти поэтический диссонанс — словно вселенная шептала «Let it be» посреди таблиц и тикетов спринтов….»

Я пока работаю над книгой, понял, какого продукта мне не хватает. Это AI-генератор диаграмм по текстовому описанию.
Идея в том, что мастер-документом для диаграммы является текст. Это текстовое описание может быть (и должно быть) довольно подробным, чтобы сгенерированная диаграмма была именно такой, какой ее себе представляет автор. Саму диаграмму не редактируют. То есть, ее можно редактировать — подвигать там кружочки, но в идеале после внесения изменений система должна обновить текст, после генерации из которого получится то, что надвигал юзер.
Результат — диаграмма — должна насколько возможно хорошо соответствовать описанию. Если она не соответствует описанию потому что нельзя условно сделать треугольник с тремя тупыми углами, то система должна сделать максимум возможного и дать словесный ответ, что не получилось. Дальше пользователь может изменить постановку задачи так, чтобы система заткнулась и выдала диаграмму как надо.
Но дальше мы понимаем, что автор мог довольно случайно попасть в то, что ему понравилось своим кривым текстом. И если перегенерить, то получится что-то другое, и не факт, что хорошее. Поэтому —
Можно попросить систему, чтобы она сгенерировала по диаграмме описание диаграммы, по которому, если его засунуть в генератор диаграмм, получится ровно то, по чему это описание сгенерировалось. Да, это описание будет более многословным, и многослойным, но зато будет более надежно описывать результат.
То есть, с этого момента вы уже не работаете с диаграммой. Вы работаете с текстом. Если нужна диаграмма — вы просто компилируете текст в диаграмму и получается как надо. Но вы даже с текстом не работаете напрямую. Вы работаете с этим текстом -описанием диаграммы через LLM. То есть, просите добавить какой-нибудь блок, и меняется текст, но меняется так, чтобы внезапно не поменялось вообще все.
Диаграмма на выходе должна быть в объектной форме, из которой можно уже делать растровую (PNG) или векторную (SVG, EPS).
Также было бы здорово, если бы на вход такой системе можно было бы дать уже имеющиеся диаграммы или диаграммы-шаблоны для того, чтобы она брала оттуда стили и имеющиеся конвенции как отображать что.
В общем, вот такие фантазии. Если у кого есть представления как это реализовать — давайте обсудим 🙂

Я тут какое-то время назад решил книжку написать по алгоритмам рекомендаций. С математикой, примерами кода, репозиторием и т.д. English, of course.
Соответственно, ищу волонтеров-рецензентов, разбирающихся в теме. Также тех, кто имеет опыт с print-on-demand на Амазоне.
Контента уже страниц на 200. Работы еще месяца на три. Рабочее название Recommender Algorithms in 2026: A Practitioner’s Guide. Где-то половина еще сырая, первые страниц 80 уже в 80% готовности.
Сделал себе механизм публикации в HTML и в PDF одним махом. HTML-версия полнофункциональна, с навигацией. Блок навигации отражает текущий раздел, при скролле он сдвигается на тот, что перед читателем. Клик по разделу конечно телепортирует на что кликнули. Все полностью автоматическое.

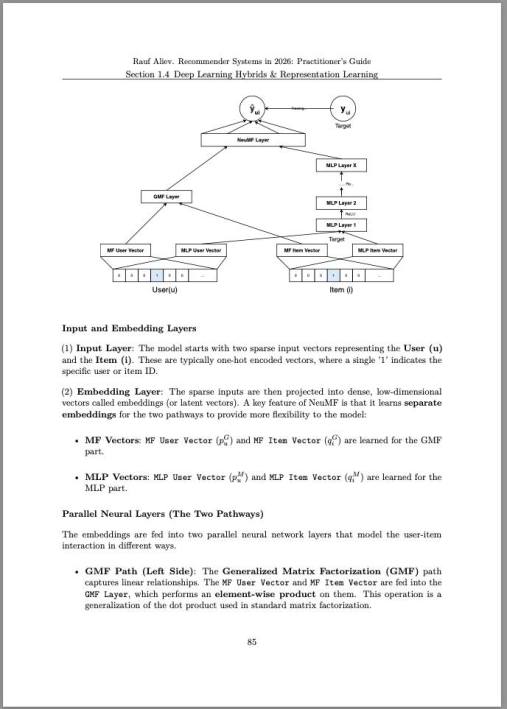
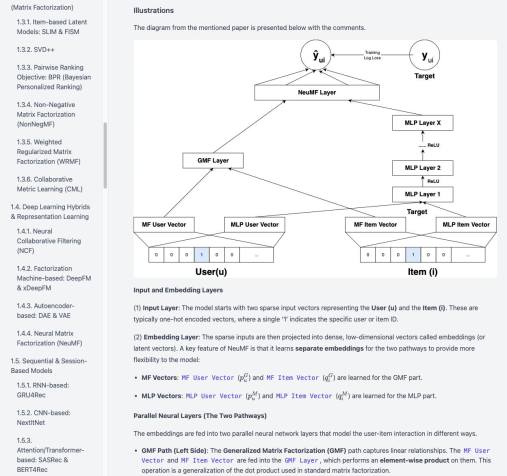



В дополнение к основному продукту для тестирования поиска я разрабатываю на досуге AI Search Agent. Вы даёте ей всего две вводные: сайт, на который нужно перейти, и цель (описанную в коротком абзаце). То есть, эта штука достаточно умная, чтобы совсем не требовать настройки — сайт и цель, а дальше типа я сама.
Как работает: Этот виртуальный агент сам генерирует поисковые запросы, перерабатывает их в зависимости от полученных результатов (например, упрощает), и анализирует, насколько они соответствуют заданному намерению. Если подходящие результаты найдены, агент может добавить товар в корзину и оформить заказ — если это предусмотрено в настройках.
Я об этом уже писал недавно — сегодня просто чуть более найс демо. Будет еще более найс, пока это вытащено из середины разработки, но уже видно, как анализируется страница и есть первые результаты, которые можно использовать.
Агент может использоваться для нескольких целей. Во-первых, это отличный способ создать ground truth — набор запросов с идеальными результатами. Эти данные потом можно применять для тестирования поиска без привлечения часто медленных и дорогих больших языковых моделей (LLM). Во-вторых, он помогает проверить поисковые функции перед запуском для пользователей. В-третьих, агент генерирует реалистичные данные использования, которые нужны для обучения моделей рекомендаций, требующих аутентичных взаимодействий.
Те цветные прямоугольники на видео — это язык взаимодействия агента с ИИ (или LLM). Чтобы понять, куда кликать, система размечает страницу и отправляет ИИ структурированное описание страницы — часто вместе со скриншотом, — чтобы он мог всё проанализировать и принять решение о следующем действии.
В рамках проекта TestMySearch.com я делаю систему «виртуальный покупатель», которая имитирует поведение реального пользователя в интернет-магазине: она начинает с абстрактной цели (например, «что-то яркое и сексуальное для спортзала»), превращает её в конкретный поисковый запрос, выполняет поиск на сайте и в зависимости от результата может либо продолжить просмотр, либо с определённой вероятностью переформулировать запрос, если найденное не соответствует исходной цели; далее система оценивает страницы по соответствию именно изначальной задумке, открывает карточки товаров, случайным образом меняет параметры вроде цвета или размера, принимает решение о добавлении в корзину и оформлении заказа, а также может покинуть сайт, что позволяет за одну ночь сгенерировать множество сессий, похожих на реальные, для тестирования поиска, фильтров и рекомендаций ещё до прихода живых пользователей.
Система полностью автоматическая. То есть, браузер на видео открывается сам, поле поиска там находится само (то есть, от сайта это не зависит), в него вбивается текст, который система придумывает сама на основе той самой изначальной цели, дальше выдаются фасеты и результаты поиска, которые тоже могут быть в совсем непредсказуемом для системы виде — но она все равно понимает где что, и принимает решение о том, перефразировать запрос, выбрать ли фасет или нажать на результат поиска. С какой-то вероятностью виртуальный пользователь покидает сайт. Если запрос перефразируется, например, то этот виртуальный пользователь не повторяет запросы, которые уже приводили к пустым или нерелеватным результатам, то есть, в пределах сессии есть «память».
Я сейчас ну очень много использую Gemini для генерации кода, и вижу скилл, который нужно иметь программистам, чтобы быть успешными на этом поприще. Это умение быстро читать и понимать чужой код, а также умение объяснить, почему генерацию AI нужно переделать и как. Для первого нужно просто очень хорошо знать язык и читать «с листа», потому что времени вдумываться будет мало. Для второго нужно хорошо знать паттерны и понимать, где они применимы, а где — нет. AI еще долго будет лажать с использованием паттернов не к месту.
Кроме этого, человеку все еще нужно будет понимать «как единое целое» на 90% код, который сгенерировал AI, и также успевать находить время на осознание каждой сгенерированной строки кода. Если расслабиться и упустить, то система может родить даже работающий, но очень плохо поддерживаемый код. Например, есть негласное правило, что отдельные файлы должны содержать не так много кода, и если он растет, то нужно делать рефакторинг, разбивая один большой на два или три. Иногда это требует переписывания логики, но это переписывание всегда направлено на одну задачу — упростить поддержку. А AI при переписывании еще и «улучшает» код заодно. И это довольно сложно запретить.
Кроме этого, сама концепция LLM предполагает ограниченность контекстного окна. Которое кодом забивается очень быстро. Чтобы была иллюзия у пользователя, что все работает даже при большом объеме кода, LLM умеют делать предварительную обработку, вытаскивая для процессинга только релевантные куски и откладывая в сторону нерелевантные, чтобы релевантные поместились в реальное контекстное окно. Но этот процесс очень ненадежный, и один раз он срабатывает, а во втором оказывается, что отложили в сторону важное, и в итоге система не увидела всю картину и сгенерировала код, в котором есть функция, очень похожая функции, отложенной в сторону, и вот у нас теперь есть две почти одинаковые.
Кроме этого, сейчас логика распределена между БД и кодом. То есть, данные часто управляют кодом. А данные в LLM просто часто не помещаются. Их слишком много. В итоге, без программистов пока с текущими архитектурами LLM не обойтись. Но вот требования к квалификации программистов только вырастут с LLM, а не упадут. Так что да, джуниорам надо волноваться, но лидам не очень 🙂
Кто в электронике шарит? Рекомендуйте.
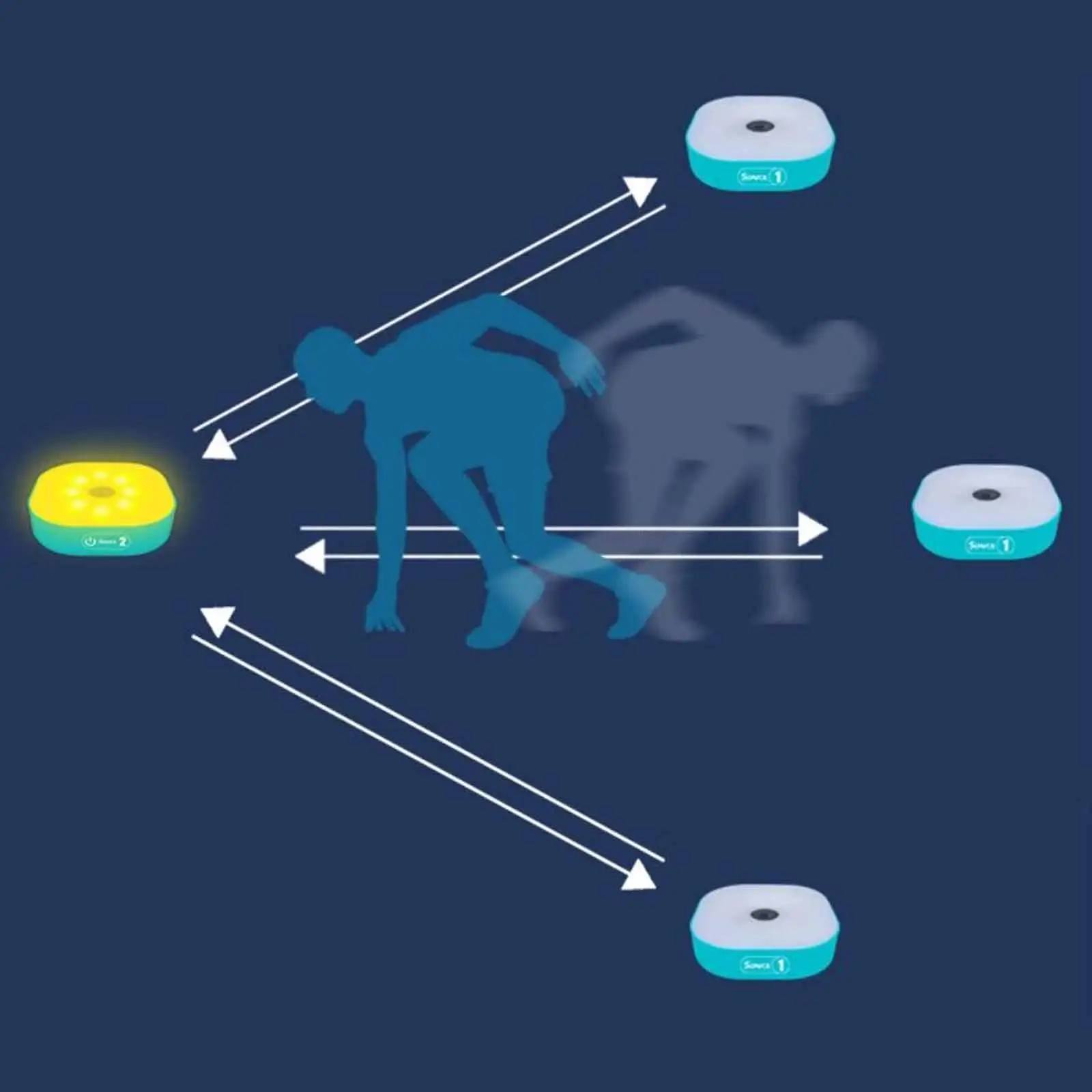
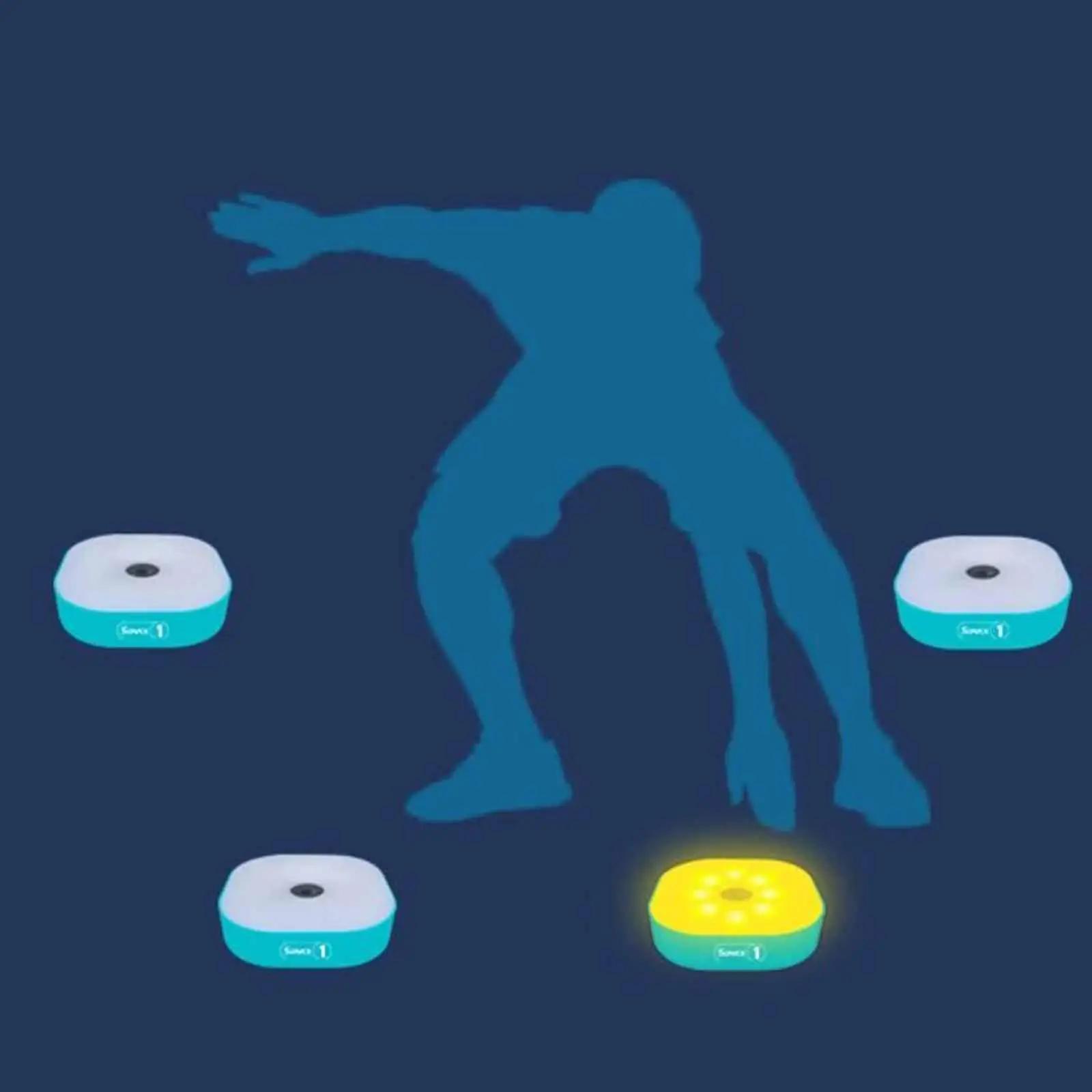
Хочу сделать на каких-то выходных такую штуку. Большая лампочковая кнопка. Загорается — ты по ней долбишь. В приложении сечется время, сколько прошло от загорания до долбежки. Кнопок может быть несколько и они могут быть разбросаны — по стене или полу. БЕЗ ПРОВОДОВ. Загораться они могут рандомно — это управляется приложением (телефон или комп). На лету вычисляются метрики типа среднего времени реакции в разном понятии слова средний. Будет можно, например, поставить кнопки на землю в нескольких метрах друг друга и придумать подвижную игру детям. Можно прикрепить на стенке и шарашить в нее мячиком. Короче, технический вопрос на самом деле.
Как бы вы это сделали — глупые кнопки на чипе nRF24L01+ или умные кнопки на микроконтрлеере esp32?
В первом случае каждый такой модуль слушает радиоэфир: как только от центрального узла приходит команда с его ID, он включает свет. После нажатия кнопки — отправляет обратное сообщение «pressed». Таймер находится на стороне центрального узла. Каждая кнопка имеет Arduino Pro Mini + nRF24L01+, но будет еще центральный хаб тоже с nRF24L01+ и Arduino Uno, Mega или ESP32, который собирает данные и который связан с компом (Bluetooth или Wifi).
Во втором случае кнопки подключены по Bluetooth (BLE) или Wifi. Мозгами кнопки является ESP32, его надо программировать через программатор.
По деньгам получается оба подхода без стоимости аркадных кнопок и 3D-печати плюс-минус одинаково — где-то в районе $10-15 за кнопку.