В последнем видео о Северной Кореи от Ланькова услышал интересное: владелец устройства не может открыть ни на компьютере, ни на телефоне чужой файл, если тот не подписан специальной электронной подписью от государства. Заинтересовался деталями, накопал для себя и для вас детали.
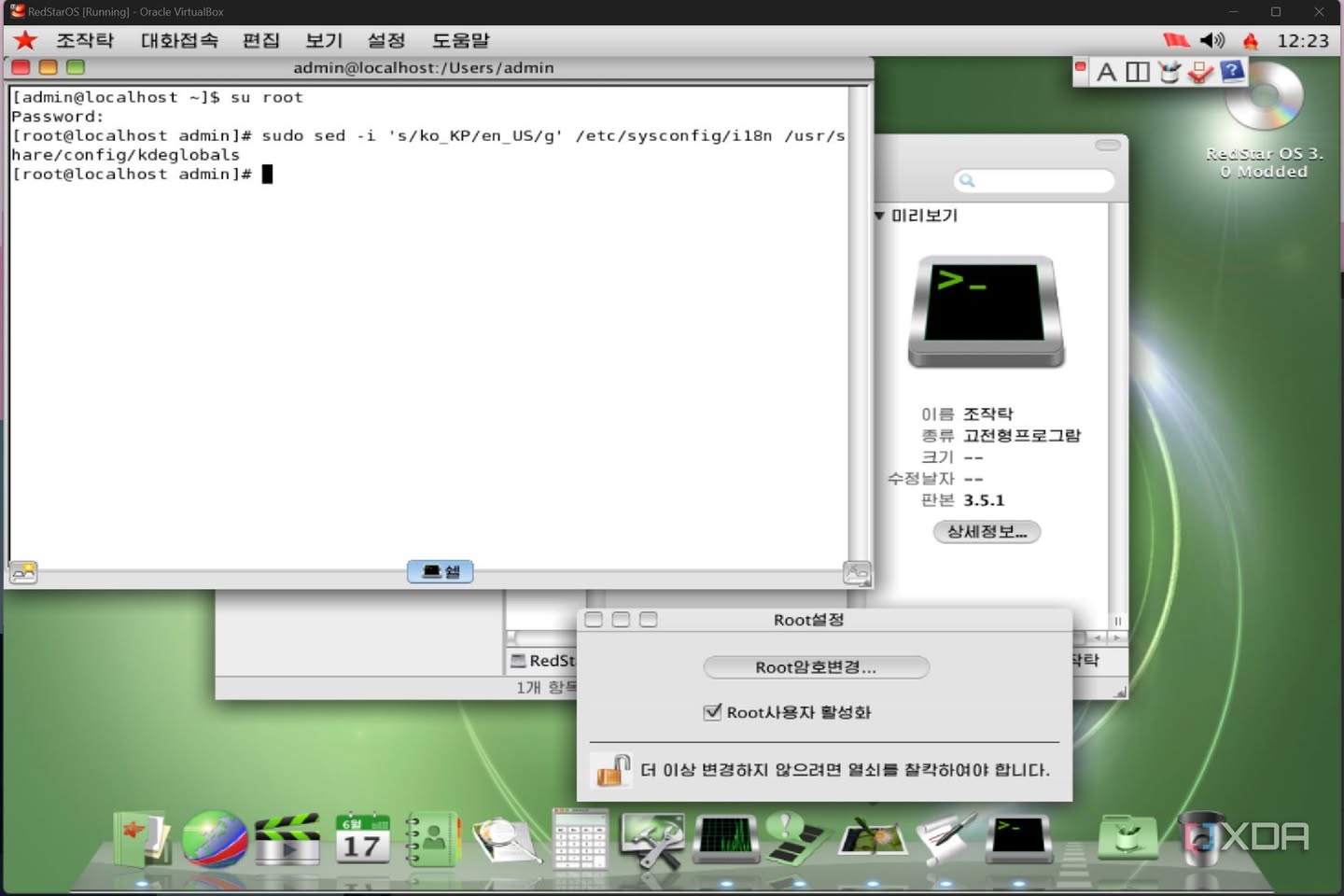
На телефонах у них модифицированный старый «KitKat» Android (2013), а на компах — модифицированный Fedora линукс, Red Star OS 3, с оболочкой, имитирующей интерфейс macOS от Apple (предыдущая косила под Windows XP). Пишут, что этот выбор дизайна, возможно, был сделан под влиянием того, что лидер Ким Чен Ын был замечен с iMac на своем столе, и видимо, сказал сделайте так же.
Северокорейские смартфоны оснащены скрытыми функциями слежки, которые автоматически делают скриншоты каждые пять минут, сохраняя их в секретной папке, доступной только властям, а не пользователю. По другим данным, скриншоты делаются при старте приложений, видимо, псевдослучайно. Еще есть цензура: если вводишь в любом приложении “Южная Корея” (남조선), система автоматически заменяет это на “марионеточное государство” (괴뢰국가). Сто процентов телефонов, очевидно, китайские, доработанные Китаем под Корею. Кстати, собираемые скриншоты доступны пользователям, но удалить их нельзя. Это приложение Trace Viewer явно создано для того, чтобы напоминать пользователям: всё, что они делают на планшете или телефоне, может быть известно правительству,
Весь медиаконтент в Red Star OS, включая документы, изображения, аудио- и видеофайлы, автоматически помечается водяным знаком с уникальным серийным номером жесткого диска, что позволяет властям отслеживать его происхождение и распространение. То есть, вы не можете сделать фотку и кинуть ее кому-нибудь, потому что она либо просто не откроется на том телефоне, либо, видимо, в редких ситуациях, если шаринг разрешен, в новом месте будут следы как того, кто является автором фотки, так и того, кто является следующим владельцем. Но это недоработано, и прямой обмен файлов все-таки ограничен. Вы можете только использовать ее сами. Разумеется, ничего нельзя удалить с телефона бесследно. Не разрешено иметь более одного устройства на человека (кажется, распространяется на отдельно планшет и отдельно телефон).
Северокорейские мобильные устройства используют строгую систему цифровых подписей (NATISIGN для одобренного правительством контента и SELFSIGN для контента, созданного на устройстве), что означает, что любой файл без этих подписей не может быть открыт в принципе. Система подписи и проверки подписи находится на уровне операционной системы, а не приложений. Это относится вообще ко всем файлам, которые люди создают что на телефонах, что на компах. Я вижу тут огромное число edge cases, но информации мало, а спросить не у кого.
Наказания за доступ к несанкционированным иностранным медиа, таким как K-pop или южнокорейские драмы, исключительно суровы. Если на компакт-диске, вставленном в компьютер с Red Star OS, обнаружен «нежелательный файл», система извлечет компакт-диск, запишет путь к файлу, отобразит графическое предупреждение, сделает скриншоты, а затем принудительно перезагрузит систему через 1000 секунд.
Северная Корея управляет национальной интранет-сетью под названием Кванмён, «огороженным садом», который полностью изолирован от глобального интернета и доступен большинству граждан только для одобренных правительством веб-сайтов и систем электронной почты.
При первом запуске браузера Naenara (основан на Firefox 3.5) домашней страницей по умолчанию является IP-адрес «10.76.1.11». То есть их интернет — это по сути интранет.