
Listening to the physics lectures, and drew attention that there are two interesting words in English, looking similarly but having completely different pronunciation: _infinite_ and _finite_ ( /ɪnfənɪt/ and /faɪnaɪt/). Another example is mal-tai rather than mul-tee (multi-).
Метка: Languages
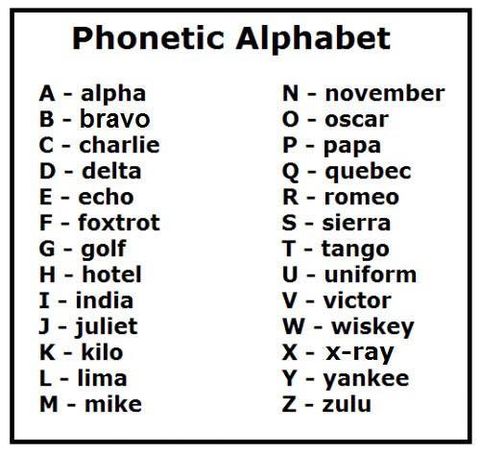
Трудности языковой коммуникации в Walmart | 31 июля 2018 года, 10:26
In Walmart, three Indian guys in the Fin Dept was attempting to properly type the MoneyGram recipient’s name which I was pronouncing, letter by letter, as clearly as I can. My “D” they have interpreted as Z, G or J, but never as D. Can’t say those were their ears or my mouth are broken or all together. This phonetic alphabet would be a great helper in such cases.
Набирали втроём с двумя индусами (?) имя получателя в пункте перевода денег в волмарте. На букву D (Ди) они нажимают Z, G, или J, но не D. Вот такую табличку не лишне заучить наизусть.
Марковские цепи: от бессмысленных текстов до алгоритмов поиска | 13 июля 2018 года, 23:06
Кстати, люди используют для генерации бессмысленных текстов цепи Маркова. Современные смартфоны используют статистику пар слов в чужих и ваших предложениях, чтобы подсказать следующее слово. Попробуйте написать что угодно матом- она правильно продолжит;) так вот, цепь Маркова – это последовательность таких предположений, основанных на статистике сочетаний. В моем практически детстве так пытались обманывать поисковики генерацией страниц-заглушек с типа реальным текстом и рекламными ссылками внутри ( они уже секут давно этот прием). А ещё я использовал этот механизм для создания случайных слов, которые можно читать без напряга (заполнял ими словарь и обфускировал по словарю данные с реальных логов для публикации на блоге).
Есть ещё интересное применение. Вы наверняка не знали, что марковские цепи лежат в основе способа сортировки результатов поиска Гугла. Если проводить параллели со словами, то пары часто используемых слов тут – пары сайтов, связанных ссылками. Есть интересное свойство марковской цепи : если она достаточно длинна, и данных достаточно много , то на “длинной дистанции” вероятность исхода (слова в случае подсказок) не зависит от того, с какого слова вы начали писать, предполагая, что речь идёт о длиной цепочке. Так вот, чем выше вероятность, тем выше pgerank, тем ближе к началу будет результат. Ну понятно, что гугл уже серьезно модифицировал алгоритм, но принципы этой фигни по ссылке и гугловского Pagerank очень близки;)
https://meduza.io/shapito/2018/07/13/prochital-na-meduze-chto
https://meduza.io/shapito/2018/07/13/prochital-na-meduze-chto
09 июля 2018 года, 12:56
Как интересно. Для Гугла и Яндекса “Новичок” практически не обозначает ничего иного, чем отравляющее вещество. Как слово, обозначающее человека, кто недавно ознакомился с чем-нибудь, для поисковиков практически умерло. Гугл транслейт еще переводит как Newbie, но, чувствую, скоро будет переводить как Novichok…
19 июня 2018 года, 11:21
Интересно, что еще ни один голосовой помощник или просто распознаватель голоса не может нормально обрабатывать речь, содержащую слова из разных языков. Также у них у всех есть проблемы с распознаванием слов, отсутствующих в словаре английского языка, но присутствующих в каком-то ограниченном списке (типа телефонного справочника). Мне так и не удалось научить сири или гугл распознавать русские имена, написанные латинницей через транслит. Казалось бы, базовая функция телефона, а нет, не работает
05 июня 2018 года, 08:01
Интересно, кто-нибудь может не заглядывая в википедию назвать второй по численности носителей язык в России? Я слегка удивился
20 мая 2018 года, 14:14
Интересно, как точно у нас работает речевой аппарат и распознавание звуков мозгом. Взять, к примеру, слоги «па» и «ба».
Разница между «па» и «ба» заключается лишь во времени задержки звука перед гласным: если задержка дольше, мы слышим «п», если короче – «б». Поднесите руку к шее в области голосовых связок: при произнесении «ба» губы размыкаются одновременно с вибрацией связок; при произнесении «па» вибрации запаздывают.
График показывает, что разница порождается в районе 20-30 мс задержки
Вдруг я понял, что мое имя стоит на пауза | 07 мая 2018 года, 11:15
Вот так на 41-году жизни узнаешь, что правильно в моем имени ударение ставить на второй слог, а не на первый, как меня родители всегда называли)
04 мая 2018 года, 15:41
“Медуза” вытащила из пыльных заколок слово “многажды” и использует вовсю)
31 марта 2018 года, 14:48
Кроме “as though”, который встречается 51 раз в первом Гарри Поттере и ноль в двух Нарниях, я заметил, что Роулинг любит использовать глагол “stare” – 58 раз в “Филосовском камне”, в то время как в двух Нарниях – 9 раз.
