Оказалось, что ядерные испытания 1955-1963 года на всей Земле оставили отпечаток во всех живых организмах, и ученые могут таким образом определять возраст клеток любого живого (тогда) существа на Земле и частоту их обновления, что без ядерных испытаний было бы это сделать заметно сложнее. Есть даже специальный термин «C-14 bomb-pulse dating».
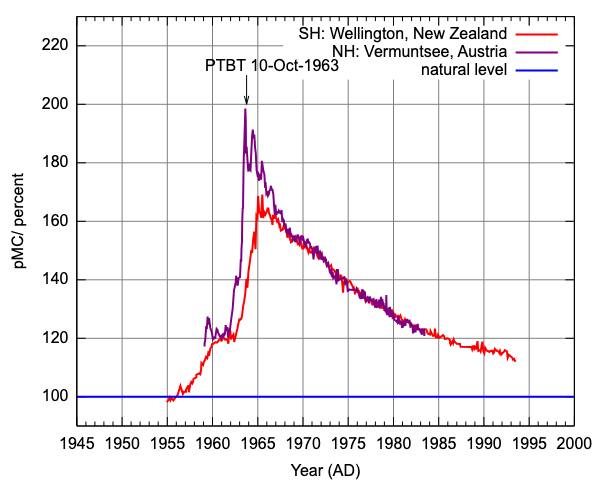
Вот как такой радиоуглеродный анализ работает. С 1955 по 1963 год использование атомных бомб удвоило количество углерода-14 в атмосфере. Атмосферный углерод-14, который обычно образуется только под воздействием космического излучения, реагирует с кислородом, образуя диоксид углерода (¹⁴CO₂). Этот ¹⁴CO₂ поглощается растениями в процессе фотосинтеза и передаётся в организм человека непосредственно через растительную пищу и опосредованно через мясо животных, при этом его количество примерно соответствует концентрации в атмосфере. Животные едят эти растения, мы едим этих животных – и углерод-14 оказывается в наших телах, встраиваясь в наши ткани.
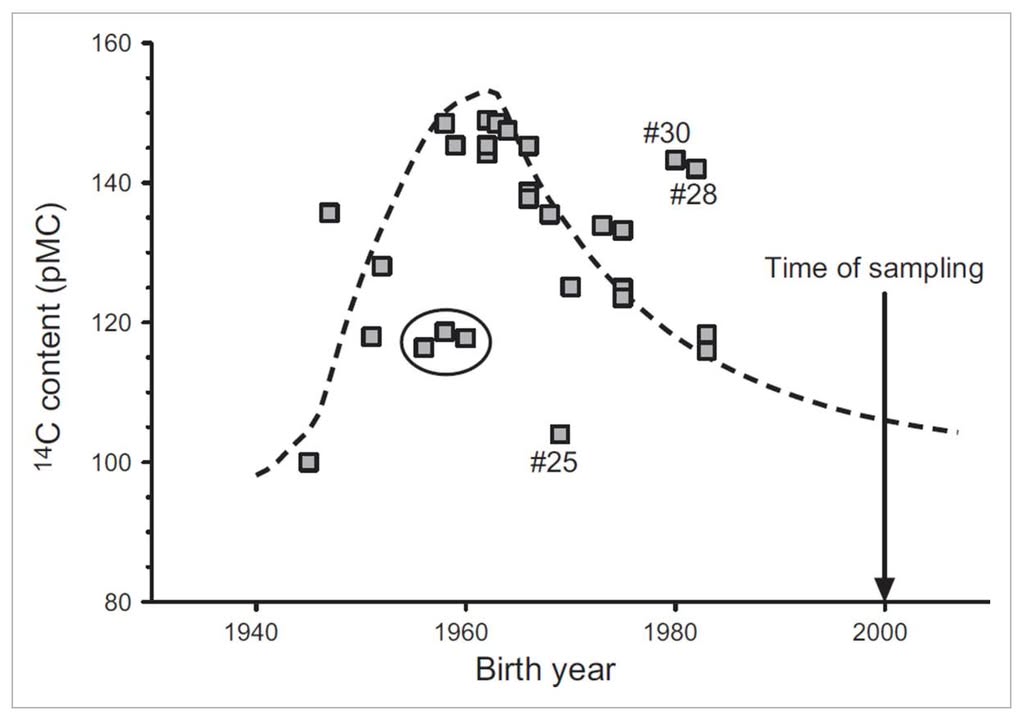
Большинство тканей в живых организмах постепенно обновляются в течение недель или месяцев, поэтому содержание углерода-14 в них соответствует текущему уровню в атмосфере. Однако ткани, которые либо не обновляются, либо обновляются очень медленно, будут содержать уровень углерода-14, близкий к тому, который был в атмосфере на момент их формирования. Таким образом, измеряя содержание углерода-14 в тканях людей, живших во время и после пика «бомбового импульса», можно точно оценить скорость замены определённой ткани или её компонентов.
Это означает, что случайным образом ядерные испытания предоставили учёным способ понять, когда формируются ткани, как долго они сохраняются и с какой скоростью заменяются.
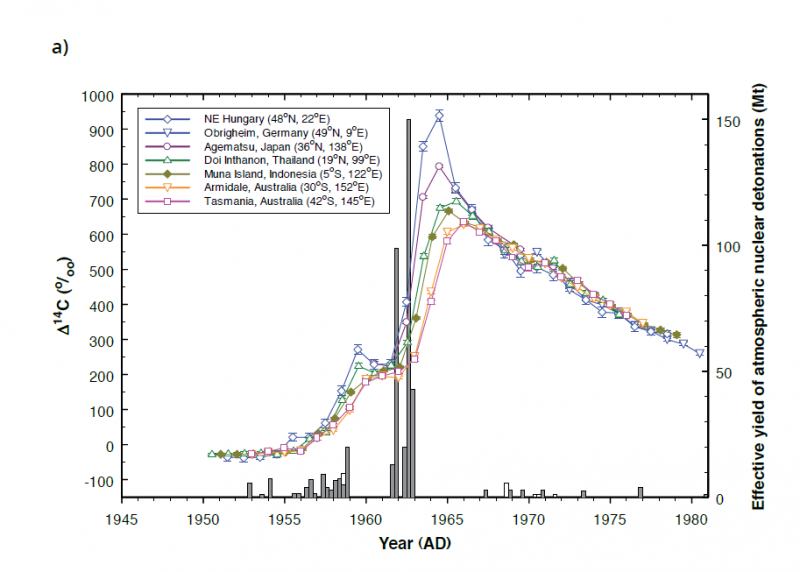
Оказывается, практически каждое дерево, жившее с 1954 года, содержит «всплеск» – своеобразный сувенир от атомных бомб. Где бы ботаники ни искали, они находят этот маркер. Есть исследования в Таиланде, исследования в Мексике, исследования в Бразилии – где бы вы ни измеряли уровень углерода-14, он там есть. Все деревья несут этот «маркер» – деревья северных широт, тропические деревья, деревья дождевых лесов – это общемировой феномен.
Но есть загвоздка. Каждые одиннадцать лет количество углерода-14 в атмосфере уменьшается наполовину. Как только уровень углерода-14 вернётся к исходному значению, этот метод станет бесполезным. Scientific American поясняет, что «у учёных есть возможность использовать этот уникальный метод датирования лишь несколько десятилетий, пока уровень углерода-14 не вернётся к норме». Это означает, что если они хотят воспользоваться этим методом, им нужно торопиться. Если только не произойдут новые ядерные взрывы – но этого никто не хочет.
Кроме прочего, это позволяет определять возраст человека по зубам и волосам. Как только зуб формируется, количество углерода-14 в его эмали остается неизменным, что делает его идеальным инструментом для датировки человека. Поскольку определенные зубы формируются в конкретные возрастные периоды, измерение содержания 14C в различных зубах может помочь исследователям оценить диапазон годов рождения. С волосами тоже самое, только они растут около 1 см в месяц, и по содержанию в разных частях волоса можно тоже делать выводы.
Для датировки углерода в зубах требуется около одной трети целого зуба, или 100 миллиграммов. Для подготовки образца его измельчают и растворяют в кислоте, что высвобождает CO2. При работе с волосами вместо растворения их в кислоте их сжигают. Поскольку волосы имеют высокое содержание углерода, требуется всего 3-4 миллиграмма волос. CO2 из образца зуба или волос затем восстанавливают до графита — кристаллической формы углерода — и помещают в ионный источник в CAMS, где нейтральные атомы графита превращаются в ионы путем придания им отрицательного заряда. Затем ускоритель может использовать этот отрицательный заряд для ускорения образца, что позволяет обнаруживать, подсчитывать и сравнивать соотношения атомов разных изотопов углерода. На графиках pMC — это отношение концентраций.
В 1960-х годах, когда концентрация C-14 резко менялась, метод позволял определять возраст тканей с точностью до ±1 года. Однако после 2000 года, по мере выравнивания уровня C-14, точность снизилась до ±2–4 лет.