На улице очень громкий гром. Юка очень задумчиво себя ведёт. Залез по очереди на все стулья зачем-то. Почему-то ему думается, что там он в большей безопасности.


На улице очень громкий гром. Юка очень задумчиво себя ведёт. Залез по очереди на все стулья зачем-то. Почему-то ему думается, что там он в большей безопасности.
Кто ж придумал для средств для проклеивания холста использовать слово size! Вот так прямо и пишут, «Paper is typically sized by the manufacturer». И иди пойми что этот size есть. А главное нагуглить это ещё та задачка, потому что со мной всеми родственными словами типа canvas легко используется sizes в смысле размеров холстов.

АААА!!! Как же меня бесит Excel на маке. Вот мне нужно иметь json-строчки в колонке. То есть, ячейка должна включать вот такое:
“classId”: “T”
Если я просто переношу эту строчку через буфер обмена в ячейку, то она становится classId: “T”, то есть, кавычки до и после classId автоматически убиваются. Какого лешего? Мне нужно 90 строк перенести, и в процессе они убиваются.
Ну хорошо, я решаю их импортировать через CSV импортер. Где я прямо указываю, что разделитель – табуляция. Та же фигня.
Хорошо, думаю я, это у тебя из-за кавычек крышу сносит. Дай-ка я заменю все кавычки на тильды, импортну, а потом в Excel заменю обратно на кавычки. Норм, импортит, но не заменяет! Как выясняется, тильда у майкрософта – это escape-символ, и чтобы заменить тильду, нужно заменять две тильды подряд ~~. Конечно, в окне Find & Replace об этом не написано.
Дальше мне нужно сделать тоже самое, но получив два столбца, в первом было бы classId, а во втором – вот этот кусок JSON — “classId” : “T”. Если я копирую из тестового файла в эксель через буфер обмена, то он почему-то решает, что разделитель – пробел, а не табуляция, и выдает мне несколько колонок, в первой хранится classId”classId”, а во второй – : “T”. Какого хрена Excel пытается распознавать формат из буфера обмена???
Дальше, если я копирую из любого офисного приложения текст в ChatGPT, то кроме текста копируется еще и изображение этого текста. Мне его приходится постоянно удалять, потому что ChatGPT удивляется, чего это картинку приложили. Причем такое только с офисом.
Дальше, вот мне нужно скопировать список из 50 строк в эксель, заполнив ими ячейки после наложения фильтра на один из столбцов. То есть, всего у меня там условно 200 строк, я отфильтровываю по критерию 50, и хочу вставить текст так, чтобы первая первая строчка заполнила первую отфильтрованную ячейку (с абсолютным номером 13, например), а вторая – ячейку ниже (с абсолютным номером 21). Я беру в буфер обмена этот список, и делаю Paste в колонку, и вижу не 50 строк, а условно 10. Потому что, похоже, остальные 40 были вставлены в ячейки, которые не видны из-за фильтра – то есть, в ячейки между 13 и 21 из примера выше.
Кроме этого, все формулы в Excel имеют разные имена и синтаксис в зависимости от языка системы и локали. То есть ладно что разделителями параметров могут быть в одном случае запятые, а в другом — точки с запятой, так и названия функций выглядят по-разному для разных языков.
Ну то есть, вот есть у них функция DSTDEVP (стандартное отклонение генеральной совокупности с условием). Если вы пересаживаетесь с компьютера, где языком системы установлен английский, на компьютер, где интерфейс не на англйиском, то формулы имеют вот такие названия:
Английский: DSTDEVP
Испанский: DESVEST.PB
Французский: ECARTYPEPB
Немецкий: STABW.DB
Итальянский: DEV.ST.P.DA
Португальский: DESVPAD.PB
Русский: СТАНДОТКЛНУСЛ
Это ж нужно было заморочиться так. Разумеется, мне никакого знания французского не хватит, чтобы из DSTDEVP сделать ECARTYPEPB. У меня если что стоял французский, чтобы не забывать, я из-за вот таких штук вернул обратно на английский, оставив французский на телефоне. Да, надо отметить, что язык Microsoft Office сделать отличным от языка системы без “хаков” нельзя. Хак заключается в том, чтобы из пакета Microsoft Office физически удалить файлы локализации на язык системы, и тогда срабатывает fallback на английский.
Конечно, я для всех проблем знаю решение. Но черт побери, как Microsoft умудряется держать на этом рынке первенство с такими отстойными приложениями. Да, все отстальное хуже. Всякие OpenOffice и родная Numbers (ни разу не видел живого пользователя), к сожалению, по недостаткам перевешивают еще больше.

Сегодня днем спутник ERS-2 упадет куда-то на Землю, непонятно куда, непонятно насколько крупные угольки прилетят.
Сегодня выяснил, что оказывается русалки на Руси были вполне себе ногастые, а за вопросы про хвост защекотали бы насмерть или утопили бы любознательных в ближайшем пруду. Специфический признак – растрёпанные русые волосы, отчего название и отчего фраза из Даля «ходит как русалка».
А хвост вообще пришёл от морских дев (mermaids). Морские девы — изобретение народов, живущих у моря. В общем, как в нашем представлении с ними слились русалки — непонятно, но произошло это относительно недавно.
Хотя есть одно предложение. У Андерсена русалочка — буквально морская дева (Den Lille Havfrue). Но в переводе на русский это назвали Русалочкой.
У Лермонтова есть стихотворение Русалка 1831 г., она там плавает по реке. Наверняка современный читатель представляет хвост. Есть ещё сказка Ореста Сомова, там русалка убегает от мамы и зекотит до смерти солдата.
Иллюстрирую картиной Прушковского «Русалки» от 1877 года и одноимённой картиной Ивана Крамского 1871 года. С ногами. Хвост бы их очень удивил.


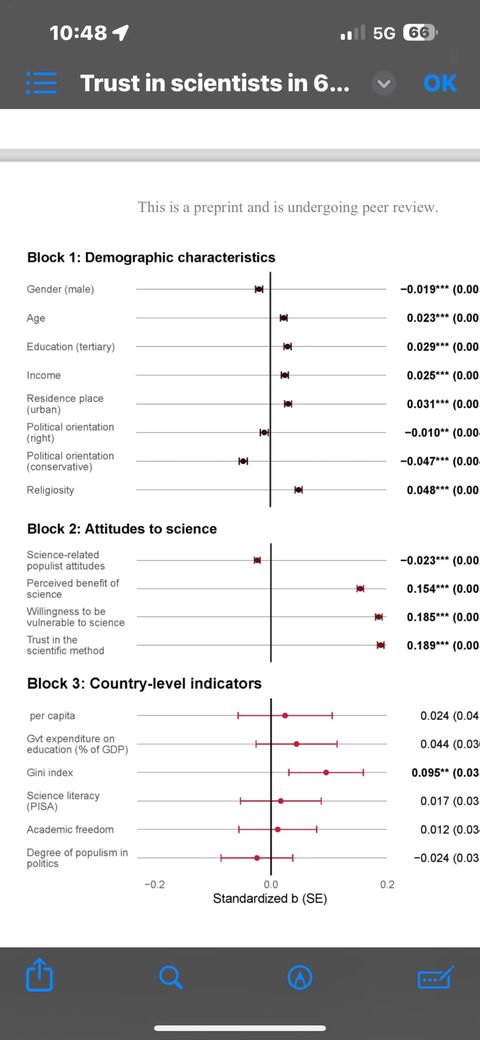
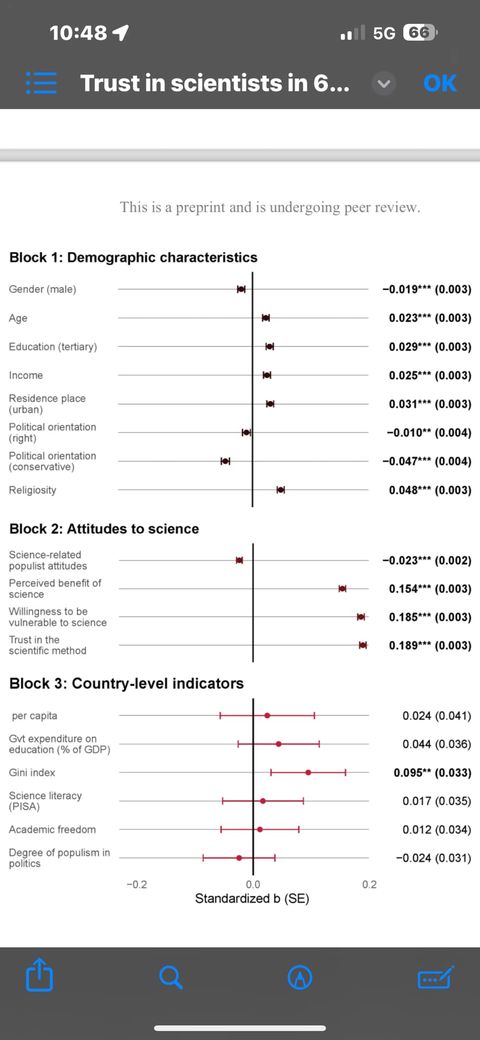
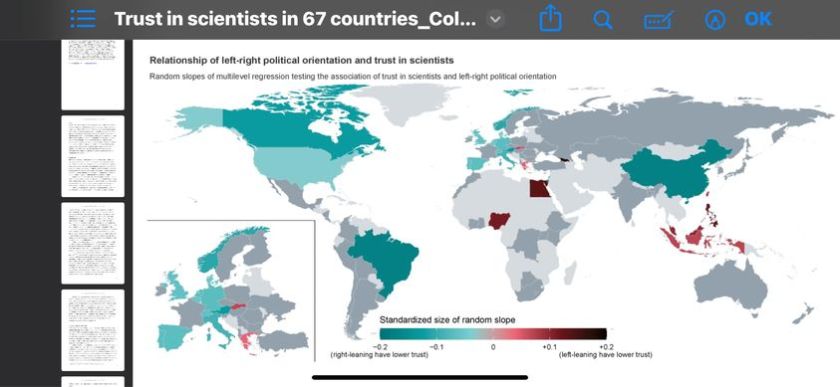
Исследование: доверие к учёным. Опрошено 71,417 чел из 67 стран.
Так и представляю диалог:
– здравствуйте, это учёные из университета Цюриха. Мы изучаем уровни доверия учёным разных народов
– идите вы со своими опросами на хрен и не звоните мне больше!
– спасибо, значит, не доверяете, так и запишем
В общем, интересные. Возможно поэтому ^^^^ Россию искать на четвертной строчке снизу, это 64 место из 67. Египет – на первом. Индия с аюрведами – на втором. Даже идут Нигерия, Кения, Бангладеш, скажу ними Австралия. Надо понимать, это не про то, насколько люди понимают всякие научные рекомендации, а насколько они их предпочитают ненаучным.
Это препринт, может там ещё какие косяки найдут. Но выглядит работа довольно содержательной.
Ссылка в комментариях

Вчера сфоткал в Вашингтоне. Рамен, оказывается, заимствован японцами у Китая, где (в Китае) он называется ламянь(拉麵 / 拉面). То есть, выходит, самый аутентичный рамен – это ламянь. Я всегда думал, что это корейская кухня.
В Корее рамен, более известный как “рамён” (라면), стал популярным после Корейской войны и частично вдохновлен японским раменом.
То есть, скорее всего, сначала был и остаётся китайский ламянь (拉面), потом Япония адаптировала рецепт, и стал рамен, а оттуда уже ушло в Корею как рамён (라면).

Снимаю шляпу перед теми, кто это придумал, аппрувнул, и реализовал. Только что вышел из national archives, это самый охраняемый музей, где хранятся свидетельство о рождении США и мастер копии конституции и поправок. Все это находится в ротонде, где даже фотки не разрешают. И вот там можно купить уголок с матрасиком и провести ночь за цену где-то в половину любого отеля в радиусе нескольких миль. Ну ок, ребёнок нужен, иначе никак. Ну и не каждый день, пару раз в год. Но, согласитесь, бомба ж идея!


Кажется, детская литература сломалась






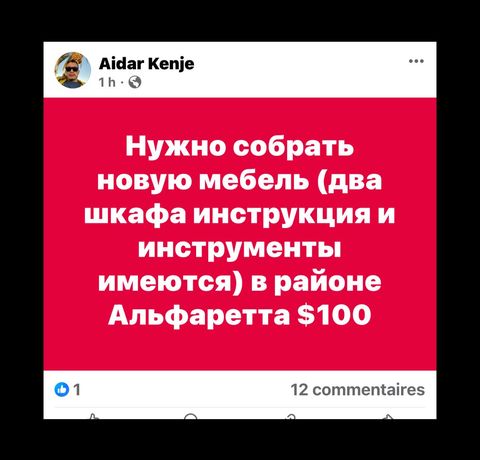
Наши фейсбучные группы жгут