Я тут подумал, что понимание, как работают большие языковые модели (LLM; типа ChatGPT) объясняет как вероятно работает наш (по крайней мере мой) мозг и наоборот, наблюдение за тем, как работает мозг, может дать лучшее понимание, как тренировать LLM.
Ну вы знаете, что в основе LLM лежит простая логика — подбор подходящего следующего слова после N известных, образующих «контекст». Для этого LLM обучают на гигатском корпусе текстов, чтобы показать, какие слова идут ОБЫЧНО после каких в каком контексте.
Так вот когда изучаешь любой английский язык, по сути, этот этап тоже неизбежен. Нужно сталкиваться с потоком слов в любом виде — письменном или устном, чтобы мозг обнаружил и усвоил закономерности просто через наблюдение или слушание (а лучше и то, и то — мультимодальность).
В LLM за единицу берутся вообще не слова, а токены — слова и часто части слов. После обработки этого огромного корпуса текстов оказалось несложным найти просто наиболее частые последовательности, которые конечно оказались где-то словами, а где-то частями слов. Так вот, когда начинаешь говорить что-то на иностранном языке, особенно с системой окончаний, начинаешь произносить начало слова, и мозг в этот момент кипит над «вычислением» окончания.
Когда мы читаем текст или слушаем, мы на самом деле не разбираем слова по буквам, потому что очень часто там просто пропадают важные куски из-за быстрой или невнятной речи, опечаток. Но мозгу вообще не надо перебирать все слова, выглядящие или звучащее как данное, ему нужно понять, совпадает ли что услышано или увидено с очень ограниченным набором слов, которые в принципе могут стоять после предыдущего слова.
Отдельная история с целыми фразами. В нашем мозгу они образуют единый «токен». То есть, не разбиваются по отдельным словам, если специально об этом не думать. И такие токены тоже идут в потоке не случайно — мозг их ожидает, и как только слышит или видит знаки, что фраза появилась, дальше круг вариантов сужается до буквально 1-2 возможных фраз с таким началом и все, какая-то одна из них является тем, что и сказано или написано.
Но самое интересное, что недавнее исследование показало: человеческий мозг действительно работает очень похоже на LLM. В работе «The neural architecture of language: Integrative modeling converges on predictive processing» ученые MIT показали, что модели, которые лучше предсказывают следующее слово, также точнее моделируют активность мозга при обработке языка. То есть механизм, используемый в современных нейросетях, не просто вдохновлен когнитивными процессами, а реально отражает их.
В эксперименте анализировались данные fMRI и электрокортикографии (ECoG) во время восприятия языка. Исследователи обнаружили, что лучшая на тот момент предсказательная модель (GPT-2 XL) могла объяснять почти 100% объяснимой вариации нейронных ответов. Это значит, что процесс понимания языка у людей действительно строится на предсказательной обработке, а не на последовательном анализе слов и грамматических конструкций. Более того, именно задача предсказания следующего слова оказалась ключевой — модели, обученные на других языковых задачах (например, грамматическом анализе), хуже предсказывали мозговую активность.
Если это правда, то ключ к fluent чтению и говорению на иностранном языке — это именно тренировка предсказательной обработки. Чем больше мозг сталкивается с потоком естественного языка (как письменного, так и устного), тем лучше он может формировать ожидания о следующем слове или фразе. Это также объясняет, почему носители языка не замечают грамматических ошибок или не всегда могут объяснить правила — их мозг не анализирует отдельные элементы, а предсказывает целые паттерны речи.
Получается, если хочется говорить свободно, нужно не просто учить правила, а буквально погружать мозг в поток языка — слушать, читать, говорить, чтобы нейросеть в голове натренировалась предсказывать слова и структуры так же, как это делает GPT.
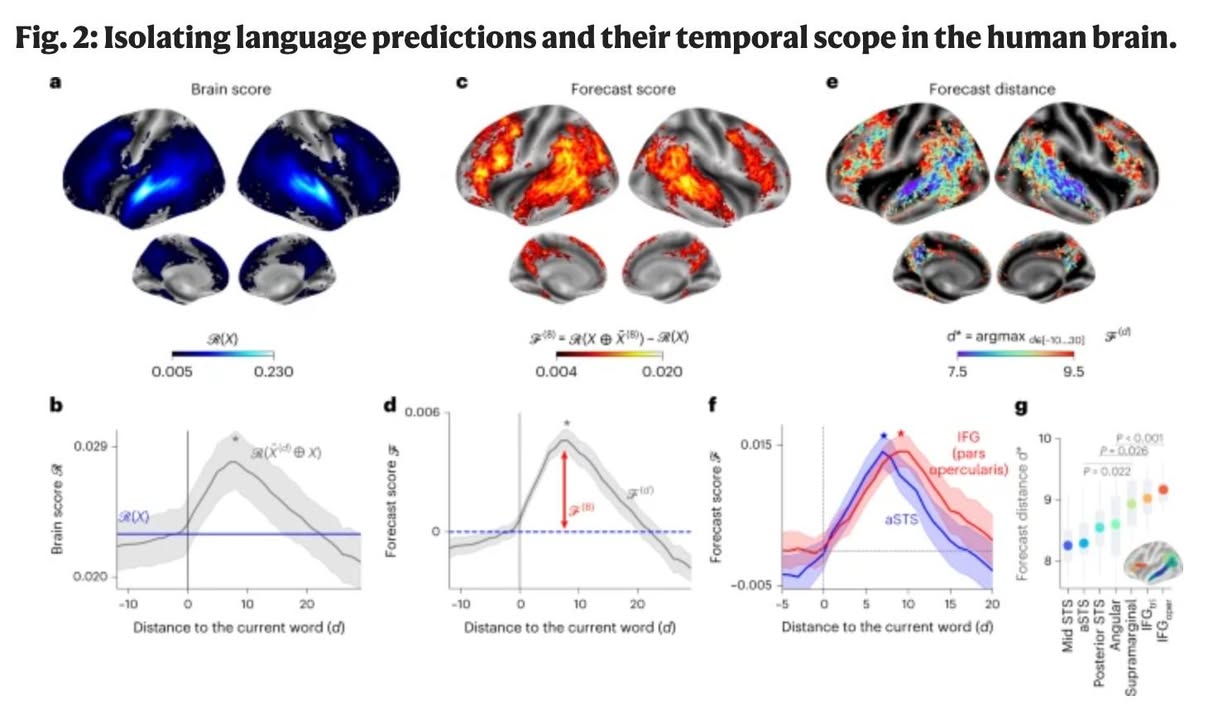
При этом, есть гипотеза предсказательного кодирования, утверждающая, то в отличие от языковых моделей, предсказывающих только ближайшие слова, человеческий мозг формирует предсказания на разных уровнях и временных масштабах. Ее проверяли уже другие ученые (гуглите Evidence of a predictive coding hierarchy in the human brain listening to speech).
Короче, о чем там. Мозг работает не только на предсказание следующего слова, но как бы запускается несколько процессов разного «разрешения». Височная кора (низший уровень) предсказывает краткосрочные и локальные элементы (звуки, слова). Лобная и теменная кора (высший уровень) предсказывает долгосрочные и глобальные языковые структуры. Семантические прогнозы (смысл слов и фраз) охватывают более длительные временные интервалы (≈8 слов вперёд). Синтаксические прогнозы (грамматическая структура) имеют более короткий временной горизонт (≈5 слов вперёд).
Если попробовать перенести эту концепцию в архитектуру языковых моделей (LLM), можно улучшить их работу за счёт иерархической предсказательной системы. Сейчас модели типа GPT работают с фиксированным контекстным окном — они анализируют ограниченное количество предыдущих слов и предсказывают следующее, не выходя за эти рамки. Однако в мозге предсказания работают на разных уровнях: локально — на уровне слов и предложений, и глобально — на уровне целых смысловых блоков.
Один из возможных способов улучшить LLM — это добавить в них механизм, который будет одновременно работать с разными временными горизонтами.
Интересно, можно ли настроить LLM так, чтобы одни слои специализировались на коротких языковых зависимостях (например, соседних словах), а другие — на более длинных структурах (например, на смысловом содержании абзаца). Я гуглю, что-то похожее есть в теме по «hierarchical transformers», где слои взаимодействуют между собой на разных уровнях абстракции, но там все-таки это больше для обработки супердлинных документов.
Как я понимаю, проблема с тем, что для такого нужно с нуля обучать фундаментальные модели, и наверное, это не очень работает на неразмеченном или плохо размеченном контенте.
Другой вариант — использовать многозадачное обучение, чтобы модель не только предсказывала следующее слово, но и пыталась угадать, о чём будет ближайшее предложение или даже целый абзац. Вроде как, опять же, гуглеж показывает, что это можно реализовать, например, через разделение голов (attention heads) в трансформере, где одни части модели анализируют короткие языковые зависимости, а другие прогнозируют более долгосрочные смысловые связи. Но как только я погружаюсь в эту тему, у меня взрывается мозг. Там все реально сложно.
Но возможно, если удастся встроить в LLM такую многоуровневую систему предсказаний, то они смогут лучше понимать контекст и генерировать более осмысленные и согласованные тексты, приближаясь к тому, как работает человеческий мозг.
Буду в марте на конференции по теме, нужно будет поговорить с учеными мужами.